 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Efficient and Flexible Interpretability of Data-driven Anomaly Detection in Industrial Processes with AcME-AD
Apr 29, 2024While Machine Learning has become crucial for Industry 4.0, its opaque nature hinders trust and impedes the transformation of valuable insights into actionable decision, a challenge exacerbated in the evolving Industry 5.0 with its human-centric focus. This paper addresses this need by testing the applicability of AcME-AD in industrial settings. This recently developed framework facilitates fast and user-friendly explanations for anomaly detection. AcME-AD is model-agnostic, offering flexibility, and prioritizes real-time efficiency. Thus, it seems suitable for seamless integration with industrial Decision Support Systems. We present the first industrial application of AcME-AD, showcasing its effectiveness through experiments. These tests demonstrate AcME-AD's potential as a valuable tool for explainable AD and feature-based root cause analysis within industrial environments, paving the way for trustworthy and actionable insights in the age of Industry 5.0.
AcME-AD: Accelerated Model Explanations for Anomaly Detection
Mar 02, 2024



Pursuing fast and robust interpretability in Anomaly Detection is crucial, especially due to its significance in practical applications. Traditional Anomaly Detection methods excel in outlier identification but are often black-boxes, providing scant insights into their decision-making process. This lack of transparency compromises their reliability and hampers their adoption in scenarios where comprehending the reasons behind anomaly detection is vital. At the same time, getting explanations quickly is paramount in practical scenarios. To bridge this gap, we present AcME-AD, a novel approach rooted in Explainable Artificial Intelligence principles, designed to clarify Anomaly Detection models for tabular data. AcME-AD transcends the constraints of model-specific or resource-heavy explainability techniques by delivering a model-agnostic, efficient solution for interoperability. It offers local feature importance scores and a what-if analysis tool, shedding light on the factors contributing to each anomaly, thus aiding root cause analysis and decision-making. This paper elucidates AcME-AD's foundation, its benefits over existing methods, and validates its effectiveness with tests on both synthetic and real datasets. AcME-AD's implementation and experiment replication code is accessible in a public repository.
ExIFFI and EIF+: Interpretability and Enhanced Generalizability to Extend the Extended Isolation Forest
Oct 09, 2023



Anomaly detection, an essential unsupervised machine learning task, involves identifying unusual behaviors within complex datasets and systems. While Machine Learning algorithms and decision support systems (DSSs) offer effective solutions for this task, simply pinpointing anomalies often falls short in real-world applications. Users of these systems often require insight into the underlying reasons behind predictions to facilitate Root Cause Analysis and foster trust in the model. However, due to the unsupervised nature of anomaly detection, creating interpretable tools is challenging. This work introduces EIF+, an enhanced variant of Extended Isolation Forest (EIF), designed to enhance generalization capabilities. Additionally, we present ExIFFI, a novel approach that equips Extended Isolation Forest with interpretability features, specifically feature rankings. Experimental results provide a comprehensive comparative analysis of Isolation-based approaches for Anomaly Detection, including synthetic and real dataset evaluations that demonstrate ExIFFI's effectiveness in providing explanations. We also illustrate how ExIFFI serves as a valid feature selection technique in unsupervised settings. To facilitate further research and reproducibility, we also provide open-source code to replicate the results.
Continual Learning Approaches for Anomaly Detection
Dec 21, 2022



Anomaly Detection is a relevant problem that arises in numerous real-world applications, especially when dealing with images. However, there has been little research for this task in the Continual Learning setting. In this work, we introduce a novel approach called SCALE (SCALing is Enough) to perform Compressed Replay in a framework for Anomaly Detection in Continual Learning setting. The proposed technique scales and compresses the original images using a Super Resolution model which, to the best of our knowledge, is studied for the first time in the Continual Learning setting. SCALE can achieve a high level of compression while maintaining a high level of image reconstruction quality. In conjunction with other Anomaly Detection approaches, it can achieve optimal results. To validate the proposed approach, we use a real-world dataset of images with pixel-based anomalies, with the scope to provide a reliable benchmark for Anomaly Detection in the context of Continual Learning, serving as a foundation for further advancements in the field.
A Multi-label Continual Learning Framework to Scale Deep Learning Approaches for Packaging Equipment Monitoring
Aug 08, 2022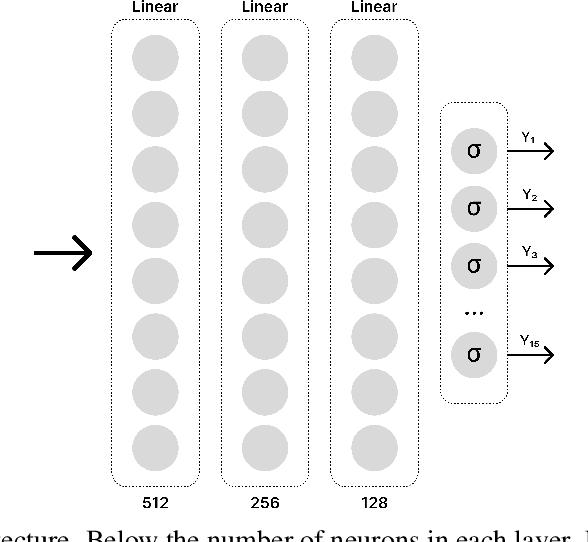

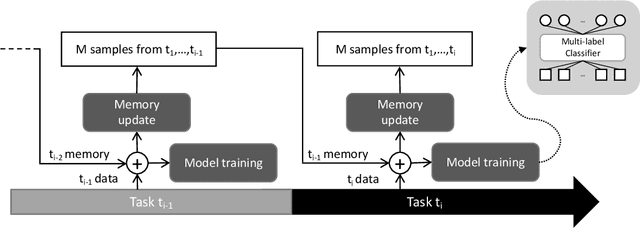
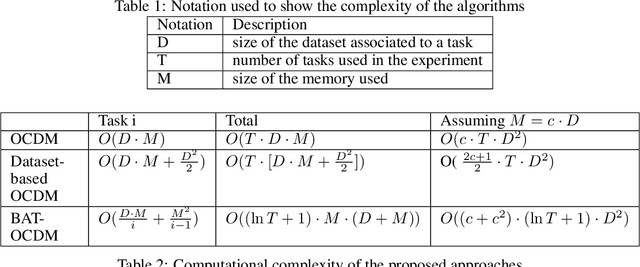
Continual Learning aims to learn from a stream of tasks, being able to remember at the same time both new and old tasks. While many approaches were proposed for single-class classification, multi-label classification in the continual scenario remains a challenging problem. For the first time, we study multi-label classification in the Domain Incremental Learning scenario. Moreover, we propose an efficient approach that has a logarithmic complexity with regard to the number of tasks, and can be applied also in the Class Incremental Learning scenario. We validate our approach on a real-world multi-label Alarm Forecasting problem from the packaging industry. For the sake of reproducibility, the dataset and the code used for the experiments are publicly available.
AcME -- Accelerated Model-agnostic Explanations: Fast Whitening of the Machine-Learning Black Box
Dec 23, 2021In the context of human-in-the-loop Machine Learning applications, like Decision Support Systems, interpretability approaches should provide actionable insights without making the users wait. In this paper, we propose Accelerated Model-agnostic Explanations (AcME), an interpretability approach that quickly provides feature importance scores both at the global and the local level. AcME can be applied a posteriori to each regression or classification model. Not only does AcME compute feature ranking, but it also provides a what-if analysis tool to assess how changes in features values would affect model predictions. We evaluated the proposed approach on synthetic and real-world datasets, also in comparison with SHapley Additive exPlanations (SHAP), the approach we drew inspiration from, which is currently one of the state-of-the-art model-agnostic interpretability approaches. We achieved comparable results in terms of quality of produced explanations while reducing dramatically the computational time and providing consistent visualization for global and local interpretations. To foster research in this field, and for the sake of reproducibility, we also provide a repository with the code used for the experiments.