 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheano: A Python framework for fast computation of mathematical expressions
May 09, 2016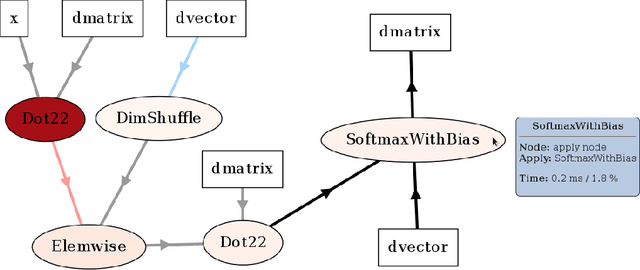
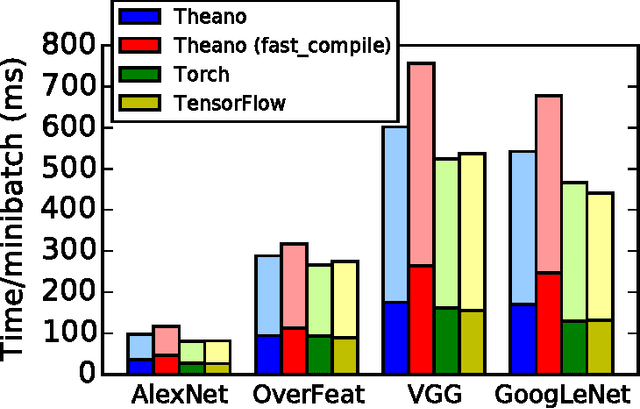
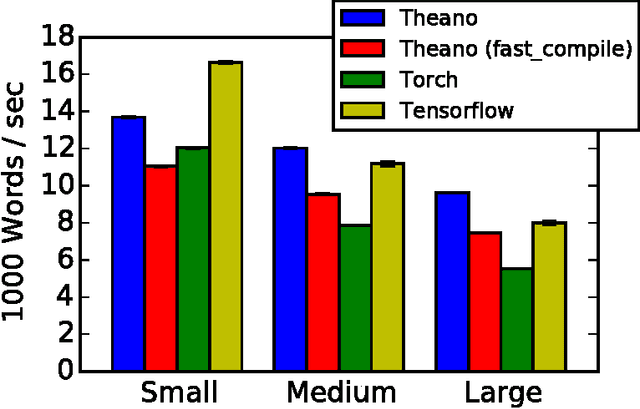
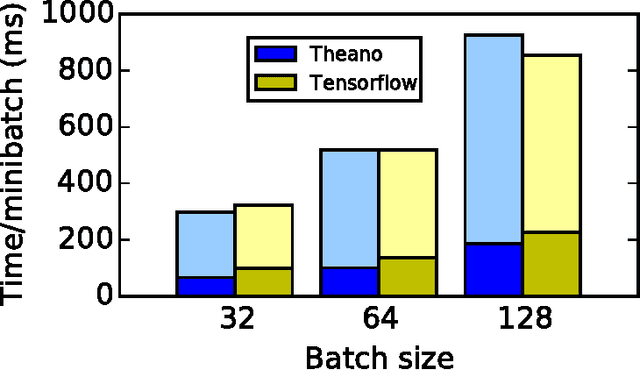
Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.
On Clustering on Graphs with Multiple Edge Types
Sep 08, 2011



We study clustering on graphs with multiple edge types. Our main motivation is that similarities between objects can be measured in many different metrics. For instance similarity between two papers can be based on common authors, where they are published, keyword similarity, citations, etc. As such, graphs with multiple edges is a more accurate model to describe similarities between objects. Each edge/metric provides only partial information about the data; recovering full information requires aggregation of all the similarity metrics. Clustering becomes much more challenging in this context, since in addition to the difficulties of the traditional clustering problem, we have to deal with a space of clusterings. We generalize the concept of clustering in single-edge graphs to multi-edged graphs and investigate problems such as: Can we find a clustering that remains good, even if we change the relative weights of metrics? How can we describe the space of clusterings efficiently? Can we find unexpected clusterings (a good clustering that is distant from all given clusterings)? If given the ground-truth clustering, can we recover how the weights for edge types were aggregated? %In this paper, we discuss these problems and the underlying algorithmic challenges and propose some solutions. We also present two case studies: one based on papers on Arxiv and one based on CIA World Factbook.