 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry of the Minimum Volume Confidence Sets
Feb 16, 2022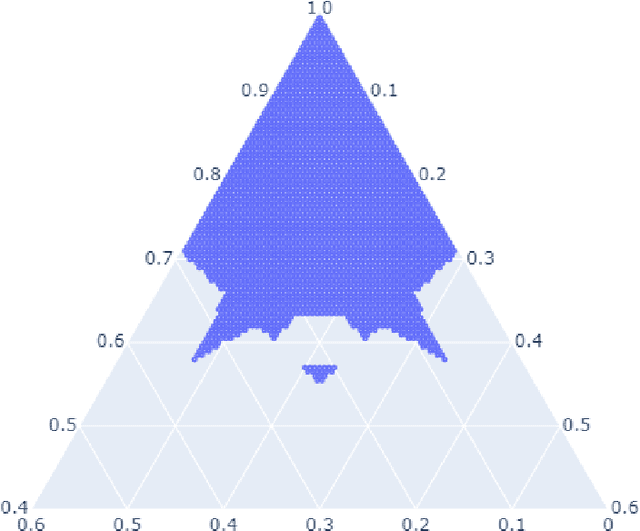
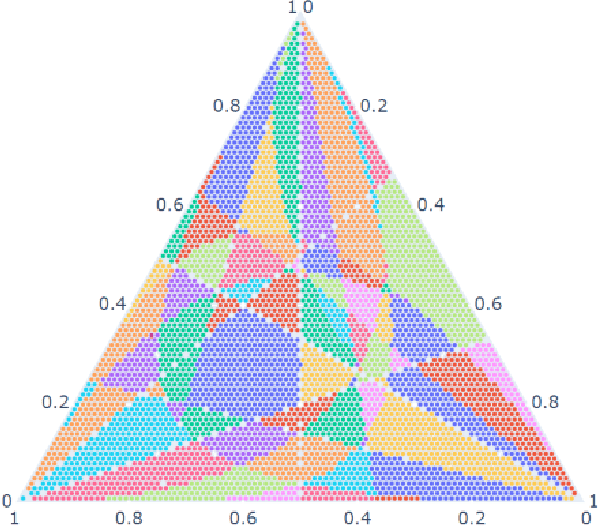
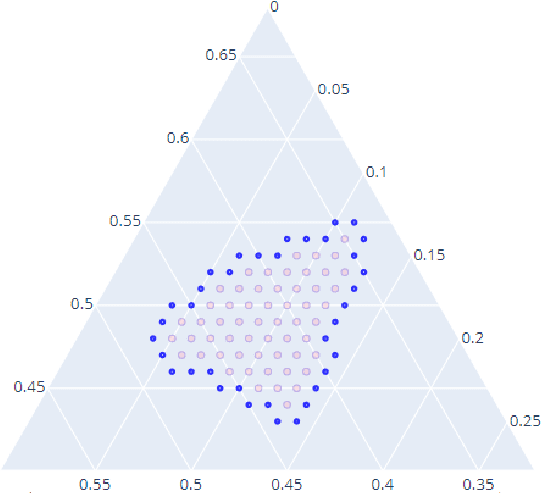
Computation of confidence sets is central to data science and machine learning, serving as the workhorse of A/B testing and underpinning the operation and analysis of reinforcement learning algorithms. This paper studies the geometry of the minimum-volume confidence sets for the multinomial parameter. When used in place of more standard confidence sets and intervals based on bounds and asymptotic approximation, learning algorithms can exhibit improved sample complexity. Prior work showed the minimum-volume confidence sets are the level-sets of a discontinuous function defined by an exact p-value. While the confidence sets are optimal in that they have minimum average volume, computation of membership of a single point in the set is challenging for problems of modest size. Since the confidence sets are level-sets of discontinuous functions, little is apparent about their geometry. This paper studies the geometry of the minimum volume confidence sets by enumerating and covering the continuous regions of the exact p-value function. This addresses a fundamental question in A/B testing: given two multinomial outcomes, how can one determine if their corresponding minimum volume confidence sets are disjoint? We answer this question in a restricted setting.
lil' UCB : An Optimal Exploration Algorithm for Multi-Armed Bandits
Dec 27, 2013

The paper proposes a novel upper confidence bound (UCB) procedure for identifying the arm with the largest mean in a multi-armed bandit game in the fixed confidence setting using a small number of total samples. The procedure cannot be improved in the sense that the number of samples required to identify the best arm is within a constant factor of a lower bound based on the law of the iterated logarithm (LIL). Inspired by the LIL, we construct our confidence bounds to explicitly account for the infinite time horizon of the algorithm. In addition, by using a novel stopping time for the algorithm we avoid a union bound over the arms that has been observed in other UCB-type algorithms. We prove that the algorithm is optimal up to constants and also show through simulations that it provides superior performance with respect to the state-of-the-art.
On Finding the Largest Mean Among Many
Jun 17, 2013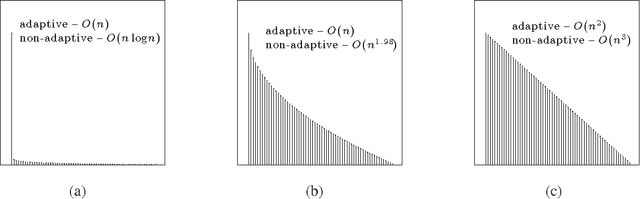

Sampling from distributions to find the one with the largest mean arises in a broad range of applications, and it can be mathematically modeled as a multi-armed bandit problem in which each distribution is associated with an arm. This paper studies the sample complexity of identifying the best arm (largest mean) in a multi-armed bandit problem. Motivated by large-scale applications, we are especially interested in identifying situations where the total number of samples that are necessary and sufficient to find the best arm scale linearly with the number of arms. We present a single-parameter multi-armed bandit model that spans the range from linear to superlinear sample complexity. We also give a new algorithm for best arm identification, called PRISM, with linear sample complexity for a wide range of mean distributions. The algorithm, like most exploration procedures for multi-armed bandits, is adaptive in the sense that the next arms to sample are selected based on previous samples. We compare the sample complexity of adaptive procedures with simpler non-adaptive procedures using new lower bounds. For many problem instances, the increased sample complexity required by non-adaptive procedures is a polynomial factor of the number of arms.