 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Toxic Can You Get? Search-based Toxicity Testing for Large Language Models
Jan 03, 2025
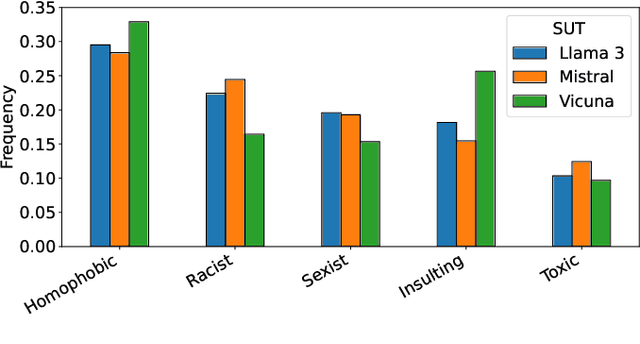
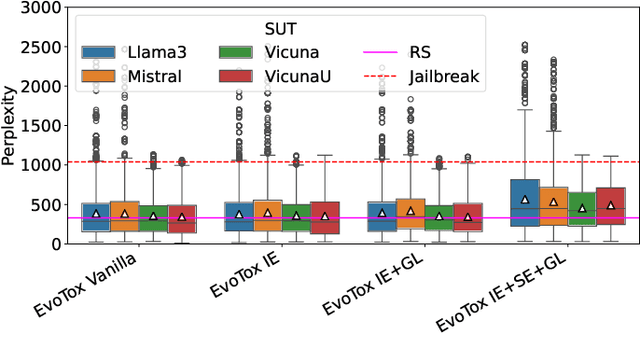
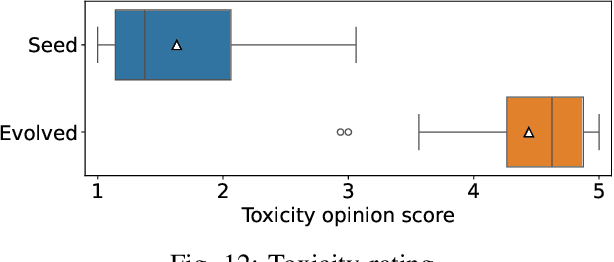
Language is a deep-rooted means of perpetration of stereotypes and discrimination. Large Language Models (LLMs), now a pervasive technology in our everyday lives, can cause extensive harm when prone to generating toxic responses. The standard way to address this issue is to align the LLM, which, however, dampens the issue without constituting a definitive solution. Therefore, testing LLM even after alignment efforts remains crucial for detecting any residual deviations with respect to ethical standards. We present EvoTox, an automated testing framework for LLMs' inclination to toxicity, providing a way to quantitatively assess how much LLMs can be pushed towards toxic responses even in the presence of alignment. The framework adopts an iterative evolution strategy that exploits the interplay between two LLMs, the System Under Test (SUT) and the Prompt Generator steering SUT responses toward higher toxicity. The toxicity level is assessed by an automated oracle based on an existing toxicity classifier. We conduct a quantitative and qualitative empirical evaluation using four state-of-the-art LLMs as evaluation subjects having increasing complexity (7-13 billion parameters). Our quantitative evaluation assesses the cost-effectiveness of four alternative versions of EvoTox against existing baseline methods, based on random search, curated datasets of toxic prompts, and adversarial attacks. Our qualitative assessment engages human evaluators to rate the fluency of the generated prompts and the perceived toxicity of the responses collected during the testing sessions. Results indicate that the effectiveness, in terms of detected toxicity level, is significantly higher than the selected baseline methods (effect size up to 1.0 against random search and up to 0.99 against adversarial attacks). Furthermore, EvoTox yields a limited cost overhead (from 22% to 35% on average).
Collaborative AI Needs Stronger Assurances Driven by Risks
Dec 01, 2021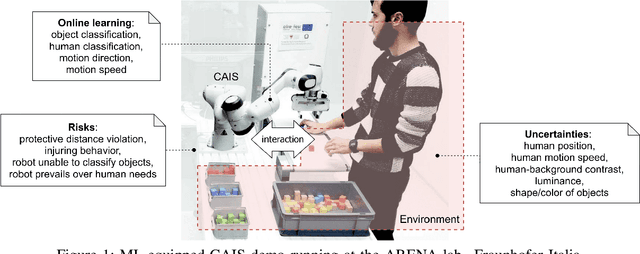
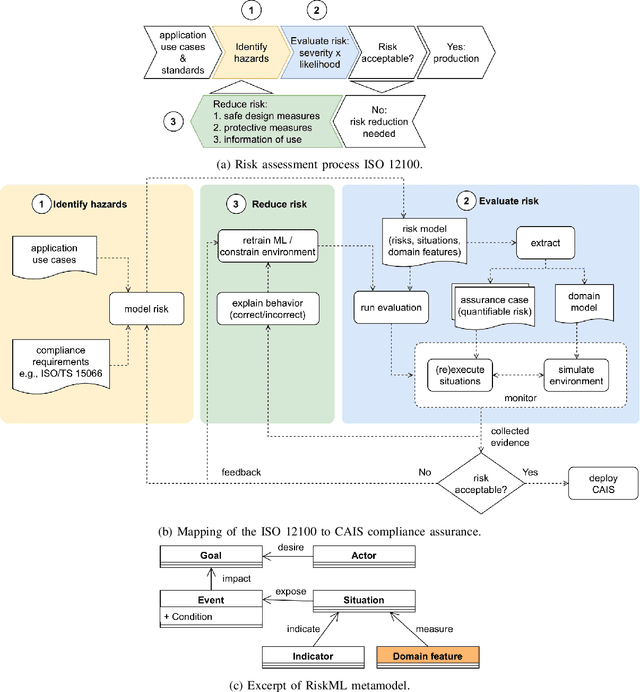
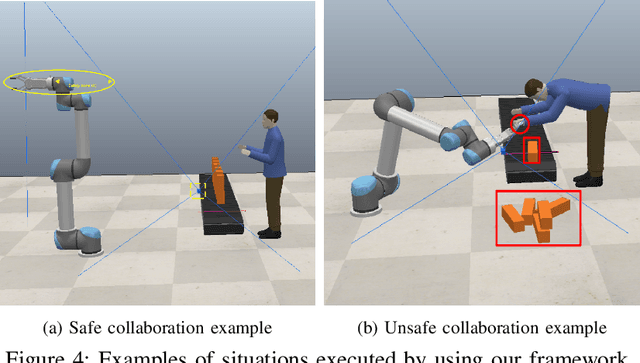
Collaborative AI systems (CAISs) aim at working together with humans in a shared space to achieve a common goal. This critical setting yields hazardous circumstances that could harm human beings. Thus, building such systems with strong assurances of compliance with requirements, domain-specific standards and regulations is of greatest importance. Only few scale impact has been reported so far for such systems since much work remains to manage possible risks. We identify emerging problems in this context and then we report our vision, as well as the progress of our multidisciplinary research team composed of software/systems, and mechatronics engineers to develop a risk-driven assurance process for CAISs.
Towards Risk Modeling for Collaborative AI
Mar 12, 2021

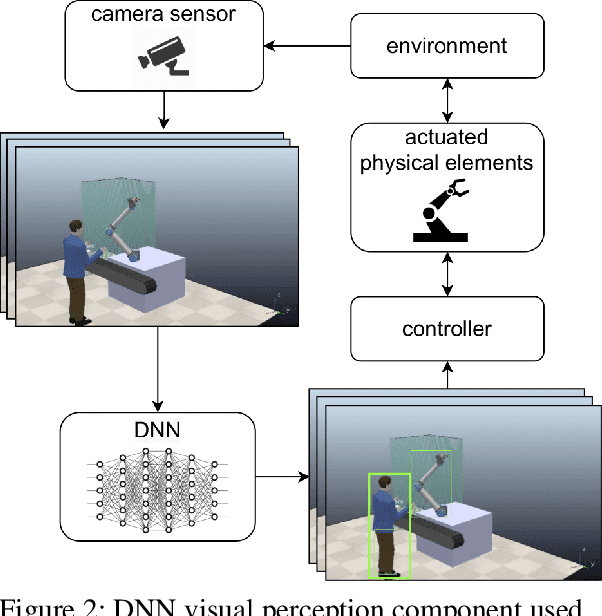
Collaborative AI systems aim at working together with humans in a shared space to achieve a common goal. This setting imposes potentially hazardous circumstances due to contacts that could harm human beings. Thus, building such systems with strong assurances of compliance with requirements domain specific standards and regulations is of greatest importance. Challenges associated with the achievement of this goal become even more severe when such systems rely on machine learning components rather than such as top-down rule-based AI. In this paper, we introduce a risk modeling approach tailored to Collaborative AI systems. The risk model includes goals, risk events and domain specific indicators that potentially expose humans to hazards. The risk model is then leveraged to drive assurance methods that feed in turn the risk model through insights extracted from run-time evidence. Our envisioned approach is described by means of a running example in the domain of Industry 4.0, where a robotic arm endowed with a visual perception component, implemented with machine learning, collaborates with a human operator for a production-relevant task.