 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo You Understand How I Feel?: Towards Verified Empathy in Therapy Chatbots
Jan 13, 2026Conversational agents are increasingly used as support tools along mental therapeutic pathways with significant societal impacts. In particular, empathy is a key non-functional requirement in therapeutic contexts, yet current chatbot development practices provide no systematic means to specify or verify it. This paper envisions a framework integrating natural language processing and formal verification to deliver empathetic therapy chatbots. A Transformer-based model extracts dialogue features, which are then translated into a Stochastic Hybrid Automaton model of dyadic therapy sessions. Empathy-related properties can then be verified through Statistical Model Checking, while strategy synthesis provides guidance for shaping agent behavior. Preliminary results show that the formal model captures therapy dynamics with good fidelity and that ad-hoc strategies improve the probability of satisfying empathy requirements.
A Research Roadmap for Augmenting Software Engineering Processes and Software Products with Generative AI
Oct 30, 2025Generative AI (GenAI) is rapidly transforming software engineering (SE) practices, influencing how SE processes are executed, as well as how software systems are developed, operated, and evolved. This paper applies design science research to build a roadmap for GenAI-augmented SE. The process consists of three cycles that incrementally integrate multiple sources of evidence, including collaborative discussions from the FSE 2025 "Software Engineering 2030" workshop, rapid literature reviews, and external feedback sessions involving peers. McLuhan's tetrads were used as a conceptual instrument to systematically capture the transforming effects of GenAI on SE processes and software products.The resulting roadmap identifies four fundamental forms of GenAI augmentation in SE and systematically characterizes their related research challenges and opportunities. These insights are then consolidated into a set of future research directions. By grounding the roadmap in a rigorous multi-cycle process and cross-validating it among independent author teams and peers, the study provides a transparent and reproducible foundation for analyzing how GenAI affects SE processes, methods and tools, and for framing future research within this rapidly evolving area. Based on these findings, the article finally makes ten predictions for SE in the year 2030.
L1RA: Dynamic Rank Assignment in LoRA Fine-Tuning
Sep 05, 2025The ability of Large Language Models (LLMs) to solve complex tasks has made them crucial in the development of AI-based applications. However, the high computational requirements to fine-tune these LLMs on downstream tasks pose significant challenges, particularly when resources are limited. In response to this challenge, we introduce L1RA, a novel technique aimed at dynamically distributing the rank of low-rank adapters during fine-tuning using LoRA. Given a rank budget (i.e., total sum of adapters rank), L1RA leverages L1 regularisation to prune redundant ranks and redistribute them across adapters, thereby optimising resource utilisation. Through a series of comprehensive experiments, we empirically demonstrate that L1RA maintains comparable or even reduced computational overhead compared to other LoRA variants, including the vanilla approach, while achieving same or better performances. Moreover, the post-training analysis of rank distribution unveiled insights into the specific model components requiring the most adaptation to align with the task objective: the feed-forward layers and the attention output projection. These results highlight the efficacy of L1RA in not only enhancing the efficiency of LLM fine-tuning, but also in providing valuable diagnostic information for model refinement and customisation. In conclusion, L1RA stands as a promising technique for advancing the performance and interpretability of LLM adaptation, particularly in scenarios where computational resources are constrained.
How Toxic Can You Get? Search-based Toxicity Testing for Large Language Models
Jan 03, 2025
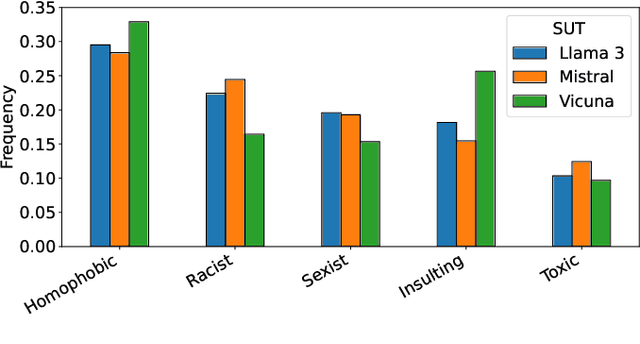
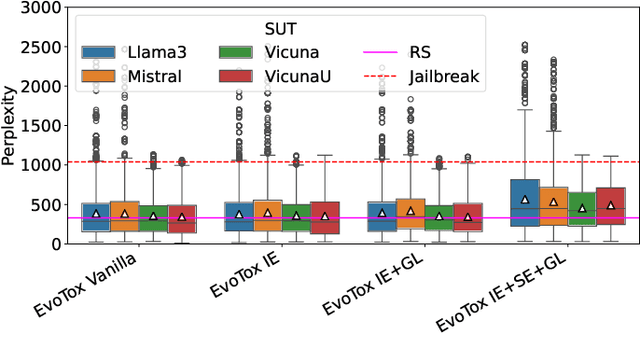
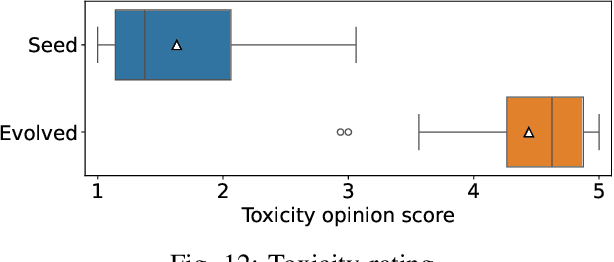
Language is a deep-rooted means of perpetration of stereotypes and discrimination. Large Language Models (LLMs), now a pervasive technology in our everyday lives, can cause extensive harm when prone to generating toxic responses. The standard way to address this issue is to align the LLM, which, however, dampens the issue without constituting a definitive solution. Therefore, testing LLM even after alignment efforts remains crucial for detecting any residual deviations with respect to ethical standards. We present EvoTox, an automated testing framework for LLMs' inclination to toxicity, providing a way to quantitatively assess how much LLMs can be pushed towards toxic responses even in the presence of alignment. The framework adopts an iterative evolution strategy that exploits the interplay between two LLMs, the System Under Test (SUT) and the Prompt Generator steering SUT responses toward higher toxicity. The toxicity level is assessed by an automated oracle based on an existing toxicity classifier. We conduct a quantitative and qualitative empirical evaluation using four state-of-the-art LLMs as evaluation subjects having increasing complexity (7-13 billion parameters). Our quantitative evaluation assesses the cost-effectiveness of four alternative versions of EvoTox against existing baseline methods, based on random search, curated datasets of toxic prompts, and adversarial attacks. Our qualitative assessment engages human evaluators to rate the fluency of the generated prompts and the perceived toxicity of the responses collected during the testing sessions. Results indicate that the effectiveness, in terms of detected toxicity level, is significantly higher than the selected baseline methods (effect size up to 1.0 against random search and up to 0.99 against adversarial attacks). Furthermore, EvoTox yields a limited cost overhead (from 22% to 35% on average).
Static Fuzzy Bag-of-Words: a lightweight sentence embedding algorithm
Apr 06, 2023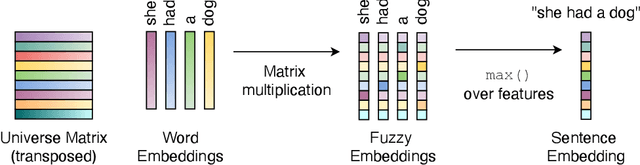

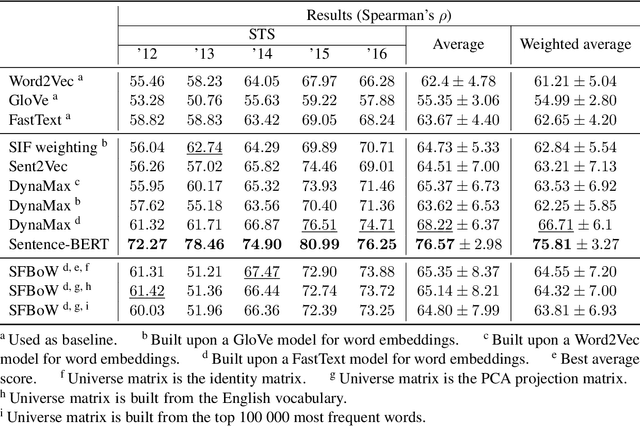
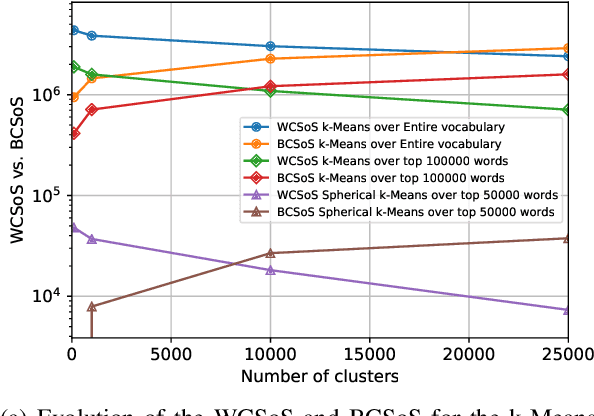
The introduction of embedding techniques has pushed forward significantly the Natural Language Processing field. Many of the proposed solutions have been presented for word-level encoding; anyhow, in the last years, new mechanism to treat information at an higher level of aggregation, like at sentence- and document-level, have emerged. With this work we address specifically the sentence embeddings problem, presenting the Static Fuzzy Bag-of-Word model. Our model is a refinement of the Fuzzy Bag-of-Words approach, providing sentence embeddings with a predefined dimension. SFBoW provides competitive performances in Semantic Textual Similarity benchmarks, while requiring low computational resources.
* 9 pages, 2 figures