 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre complicated loss functions necessary for teaching LLMs to reason?
Mar 19, 2026Recent advances in large language models (LLMs) highlight the importance of post training techniques for improving reasoning and mathematical ability. Group Relative Policy Optimization (GRPO) has shown promise in this domain by combining group relative advantage estimation, PPO style clipping, and KL regularization. However, its complexity raises the question of whether all components are necessary for fostering reasoning behaviors. We conduct a systematic analysis of GRPO and identify two key findings: (1) incorporating negative feedback is essential training solely on actions above a baseline limits learning; and (2) PPO style constraints, such as policy ratio clipping, are not required to improve mathematical reasoning or performance. Building on these insights, we propose REINFORCE with Group Relative Advantage (RGRA), a simplified variant that retains group relative advantage estimation but removes PPO style clipping and policy ratio terms. Experiments across standard mathematical benchmarks indicate that RGRA has the potential to achieve stronger performance than GRPO. Our results suggest that simpler REINFORCE based approaches can effectively enhance reasoning in LLMs, offering a more transparent and efficient alternative to GRPO.
L1RA: Dynamic Rank Assignment in LoRA Fine-Tuning
Sep 05, 2025The ability of Large Language Models (LLMs) to solve complex tasks has made them crucial in the development of AI-based applications. However, the high computational requirements to fine-tune these LLMs on downstream tasks pose significant challenges, particularly when resources are limited. In response to this challenge, we introduce L1RA, a novel technique aimed at dynamically distributing the rank of low-rank adapters during fine-tuning using LoRA. Given a rank budget (i.e., total sum of adapters rank), L1RA leverages L1 regularisation to prune redundant ranks and redistribute them across adapters, thereby optimising resource utilisation. Through a series of comprehensive experiments, we empirically demonstrate that L1RA maintains comparable or even reduced computational overhead compared to other LoRA variants, including the vanilla approach, while achieving same or better performances. Moreover, the post-training analysis of rank distribution unveiled insights into the specific model components requiring the most adaptation to align with the task objective: the feed-forward layers and the attention output projection. These results highlight the efficacy of L1RA in not only enhancing the efficiency of LLM fine-tuning, but also in providing valuable diagnostic information for model refinement and customisation. In conclusion, L1RA stands as a promising technique for advancing the performance and interpretability of LLM adaptation, particularly in scenarios where computational resources are constrained.
Perception Visualization: Seeing Through the Eyes of a DNN
Apr 21, 2022

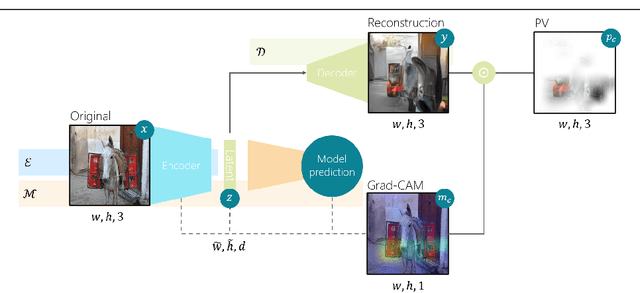
Artificial intelligence (AI) systems power the world we live in. Deep neural networks (DNNs) are able to solve tasks in an ever-expanding landscape of scenarios, but our eagerness to apply these powerful models leads us to focus on their performance and deprioritises our ability to understand them. Current research in the field of explainable AI tries to bridge this gap by developing various perturbation or gradient-based explanation techniques. For images, these techniques fail to fully capture and convey the semantic information needed to elucidate why the model makes the predictions it does. In this work, we develop a new form of explanation that is radically different in nature from current explanation methods, such as Grad-CAM. Perception visualization provides a visual representation of what the DNN perceives in the input image by depicting what visual patterns the latent representation corresponds to. Visualizations are obtained through a reconstruction model that inverts the encoded features, such that the parameters and predictions of the original models are not modified. Results of our user study demonstrate that humans can better understand and predict the system's decisions when perception visualizations are available, thus easing the debugging and deployment of deep models as trusted systems.
What's wrong with this video? Comparing Explainers for Deepfake Detection
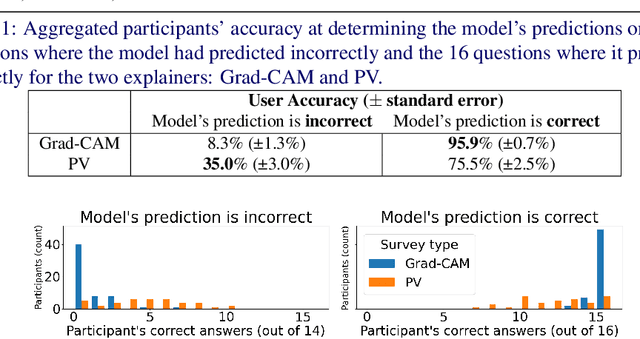
May 12, 2021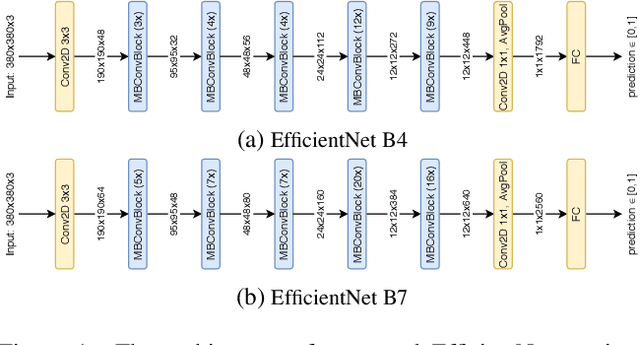
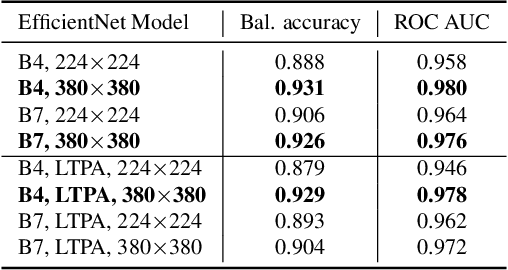

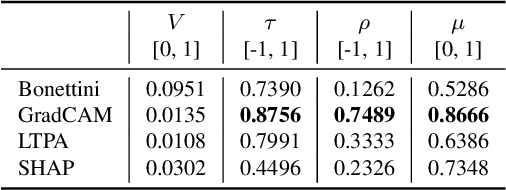
Deepfakes are computer manipulated videos where the face of an individual has been replaced with that of another. Software for creating such forgeries is easy to use and ever more popular, causing serious threats to personal reputation and public security. The quality of classifiers for detecting deepfakes has improved with the releasing of ever larger datasets, but the understanding of why a particular video has been labelled as fake has not kept pace. In this work we develop, extend and compare white-box, black-box and model-specific techniques for explaining the labelling of real and fake videos. In particular, we adapt SHAP, GradCAM and self-attention models to the task of explaining the predictions of state-of-the-art detectors based on EfficientNet, trained on the Deepfake Detection Challenge (DFDC) dataset. We compare the obtained explanations, proposing metrics to quantify their visual features and desirable characteristics, and also perform a user survey collecting users' opinions regarding the usefulness of the explainers.
Automatic Sarcasm Detection: A Survey
Sep 20, 2016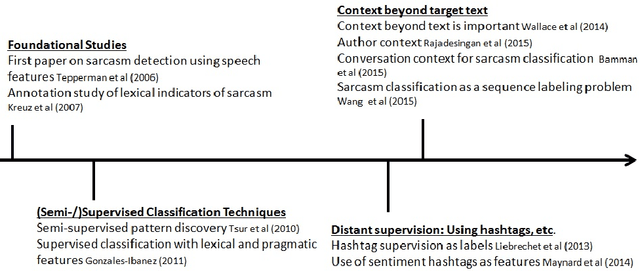
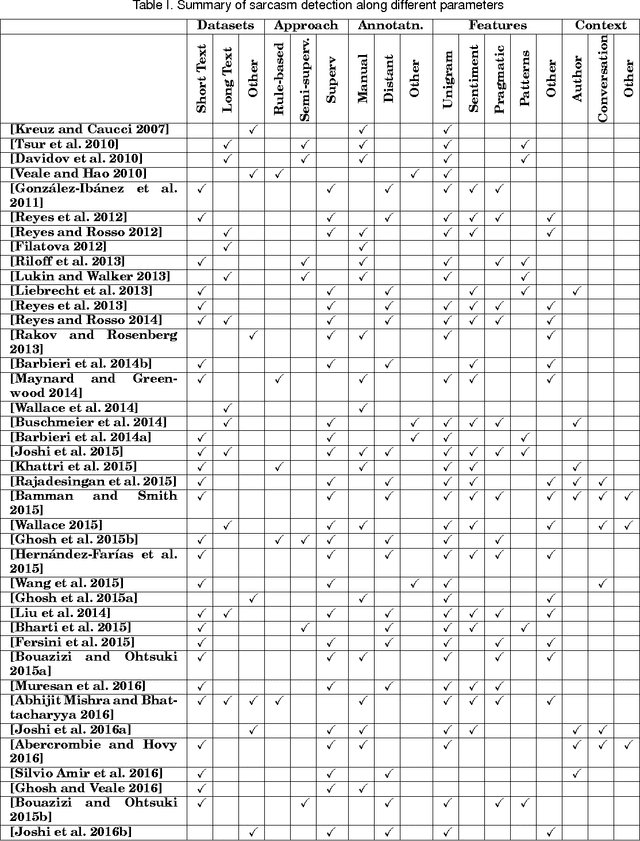

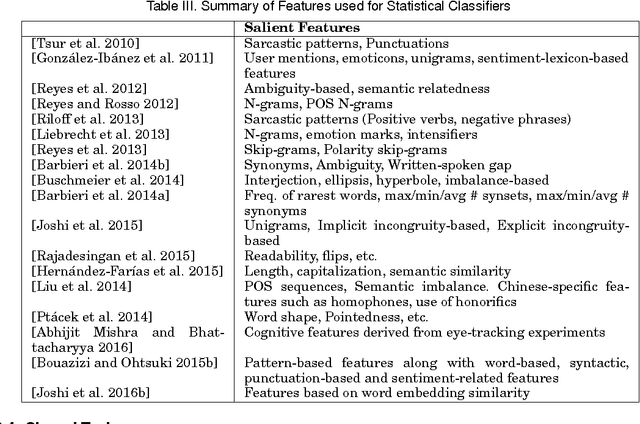
Automatic sarcasm detection is the task of predicting sarcasm in text. This is a crucial step to sentiment analysis, considering prevalence and challenges of sarcasm in sentiment-bearing text. Beginning with an approach that used speech-based features, sarcasm detection has witnessed great interest from the sentiment analysis community. This paper is the first known compilation of past work in automatic sarcasm detection. We observe three milestones in the research so far: semi-supervised pattern extraction to identify implicit sentiment, use of hashtag-based supervision, and use of context beyond target text. In this paper, we describe datasets, approaches, trends and issues in sarcasm detection. We also discuss representative performance values, shared tasks and pointers to future work, as given in prior works. In terms of resources that could be useful for understanding state-of-the-art, the survey presents several useful illustrations - most prominently, a table that summarizes past papers along different dimensions such as features, annotation techniques, data forms, etc.