 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Sarcasm Detection: A Survey
Paper and Code
Sep 20, 2016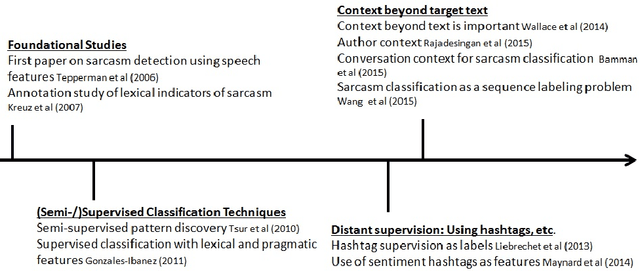
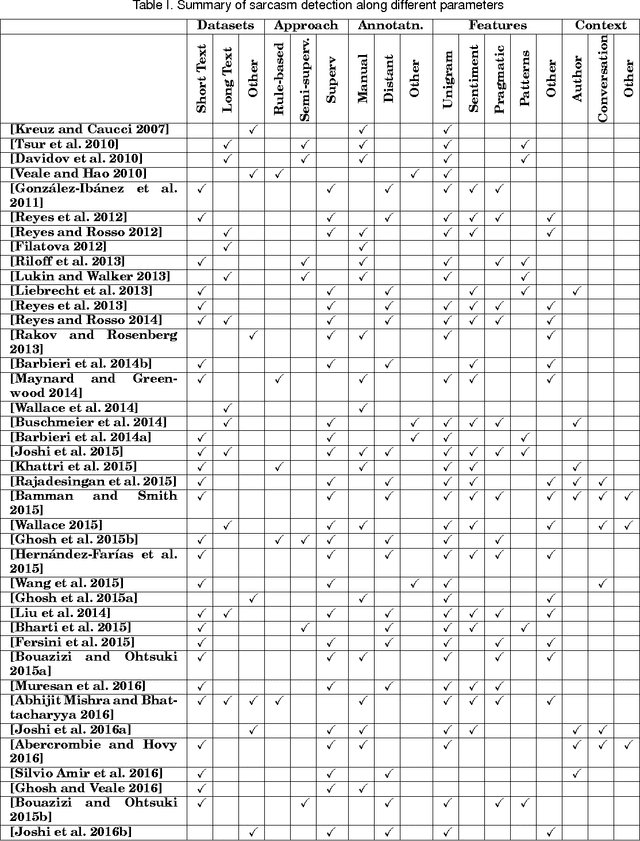

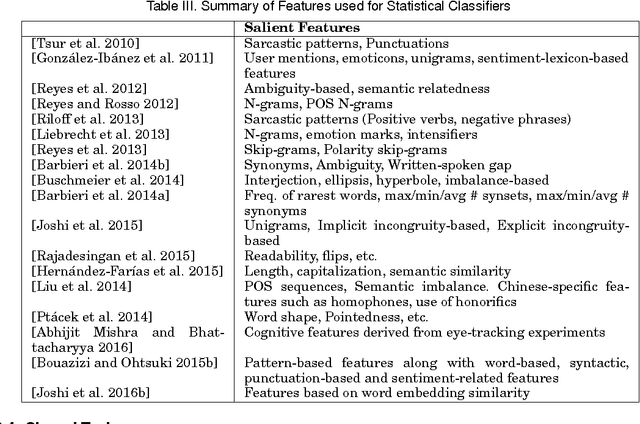
Automatic sarcasm detection is the task of predicting sarcasm in text. This is a crucial step to sentiment analysis, considering prevalence and challenges of sarcasm in sentiment-bearing text. Beginning with an approach that used speech-based features, sarcasm detection has witnessed great interest from the sentiment analysis community. This paper is the first known compilation of past work in automatic sarcasm detection. We observe three milestones in the research so far: semi-supervised pattern extraction to identify implicit sentiment, use of hashtag-based supervision, and use of context beyond target text. In this paper, we describe datasets, approaches, trends and issues in sarcasm detection. We also discuss representative performance values, shared tasks and pointers to future work, as given in prior works. In terms of resources that could be useful for understanding state-of-the-art, the survey presents several useful illustrations - most prominently, a table that summarizes past papers along different dimensions such as features, annotation techniques, data forms, etc.