 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Transformer Language Models on Arithmetic Operations Using Number Decomposition
Apr 21, 2023In recent years, Large Language Models such as GPT-3 showed remarkable capabilities in performing NLP tasks in the zero and few shot settings. On the other hand, the experiments highlighted the difficulty of GPT-3 in carrying out tasks that require a certain degree of reasoning, such as arithmetic operations. In this paper we evaluate the ability of Transformer Language Models to perform arithmetic operations following a pipeline that, before performing computations, decomposes numbers in units, tens, and so on. We denote the models fine-tuned with this pipeline with the name Calculon and we test them in the task of performing additions, subtractions and multiplications on the same test sets of GPT-3. Results show an increase of accuracy of 63% in the five-digit addition task. Moreover, we demonstrate the importance of the decomposition pipeline introduced, since fine-tuning the same Language Model without decomposing numbers results in 0% accuracy in the five-digit addition task.
* 7 pages, 1 figure, published at LREC 2022
Static Fuzzy Bag-of-Words: a lightweight sentence embedding algorithm
Apr 06, 2023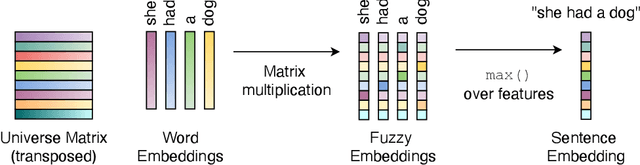

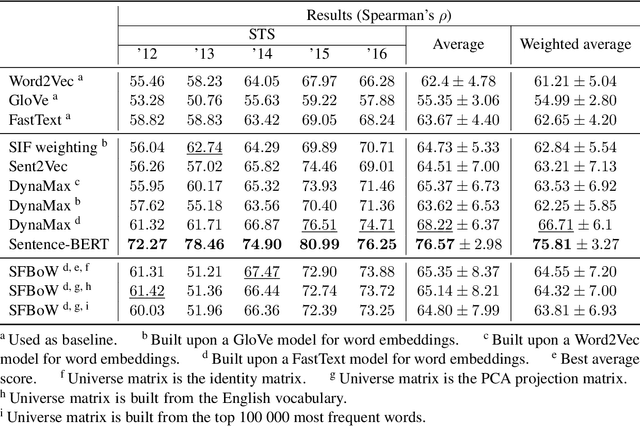
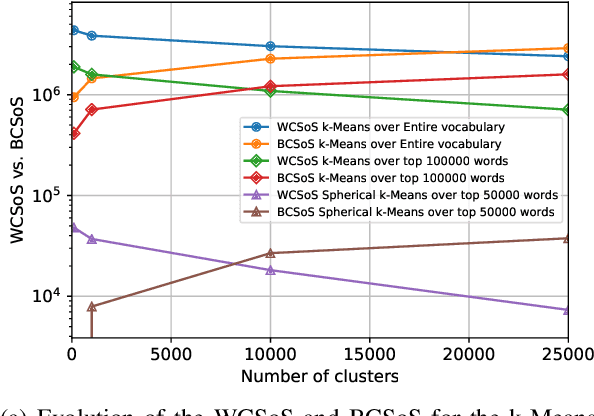
The introduction of embedding techniques has pushed forward significantly the Natural Language Processing field. Many of the proposed solutions have been presented for word-level encoding; anyhow, in the last years, new mechanism to treat information at an higher level of aggregation, like at sentence- and document-level, have emerged. With this work we address specifically the sentence embeddings problem, presenting the Static Fuzzy Bag-of-Word model. Our model is a refinement of the Fuzzy Bag-of-Words approach, providing sentence embeddings with a predefined dimension. SFBoW provides competitive performances in Semantic Textual Similarity benchmarks, while requiring low computational resources.
* 9 pages, 2 figures
BERTino: an Italian DistilBERT model
Mar 31, 2023



The recent introduction of Transformers language representation models allowed great improvements in many natural language processing (NLP) tasks. However, if on one hand the performances achieved by this kind of architectures are surprising, on the other their usability is limited by the high number of parameters which constitute their network, resulting in high computational and memory demands. In this work we present BERTino, a DistilBERT model which proposes to be the first lightweight alternative to the BERT architecture specific for the Italian language. We evaluated BERTino on the Italian ISDT, Italian ParTUT, Italian WikiNER and multiclass classification tasks, obtaining F1 scores comparable to those obtained by a BERTBASE with a remarkable improvement in training and inference speed.
* 5 pages