 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring DINO: Emergent Properties and Limitations for Synthetic Aperture Radar Imagery
Oct 05, 2023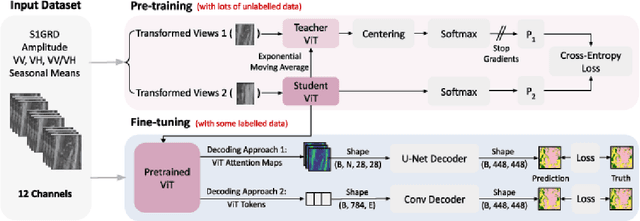
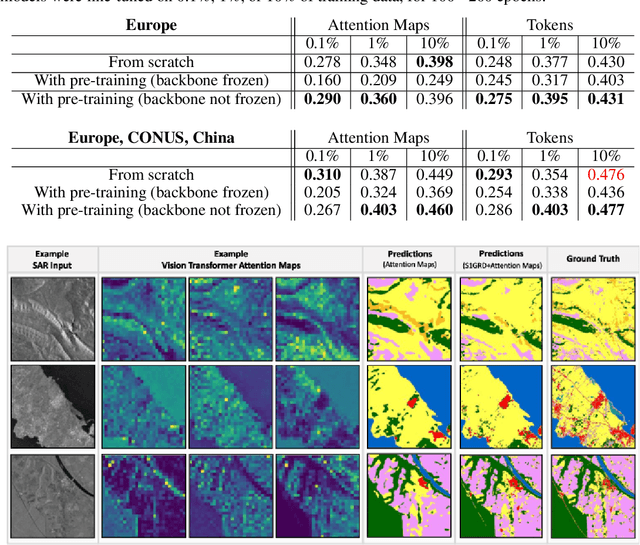
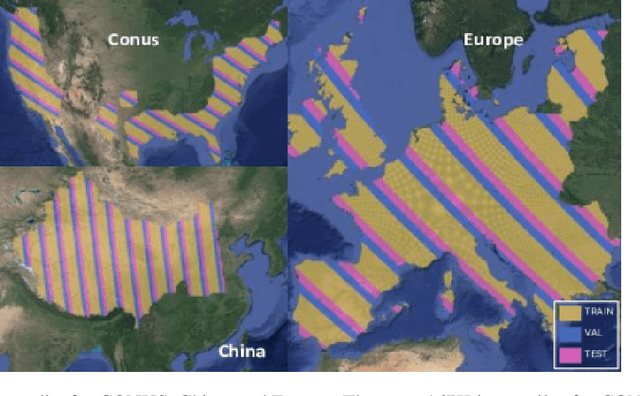
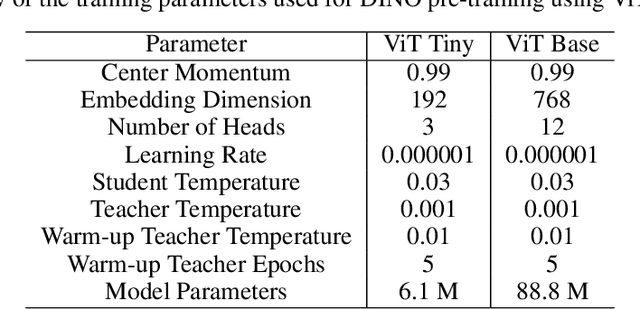
Self-supervised learning (SSL) models have recently demonstrated remarkable performance across various tasks, including image segmentation. This study delves into the emergent characteristics of the Self-Distillation with No Labels (DINO) algorithm and its application to Synthetic Aperture Radar (SAR) imagery. We pre-train a vision transformer (ViT)-based DINO model using unlabeled SAR data, and later fine-tune the model to predict high-resolution land cover maps. We rigorously evaluate the utility of attention maps generated by the ViT backbone, and compare them with the model's token embedding space. We observe a small improvement in model performance with pre-training compared to training from scratch, and discuss the limitations and opportunities of SSL for remote sensing and land cover segmentation. Beyond small performance increases, we show that ViT attention maps hold great intrinsic value for remote sensing, and could provide useful inputs to other algorithms. With this, our work lays the ground-work for bigger and better SSL models for Earth Observation.
Exploring Generalisability of Self-Distillation with No Labels for SAR-Based Vegetation Prediction
Oct 03, 2023In this work we pre-train a DINO-ViT based model using two Synthetic Aperture Radar datasets (S1GRD or GSSIC) across three regions (China, Conus, Europe). We fine-tune the models on smaller labeled datasets to predict vegetation percentage, and empirically study the connection between the embedding space of the models and their ability to generalize across diverse geographic regions and to unseen data. For S1GRD, embedding spaces of different regions are clearly separated, while GSSIC's overlaps. Positional patterns remain during fine-tuning, and greater distances in embeddings often result in higher errors for unfamiliar regions. With this, our work increases our understanding of generalizability for self-supervised models applied to remote sensing.
Large Scale Masked Autoencoding for Reducing Label Requirements on SAR Data
Oct 02, 2023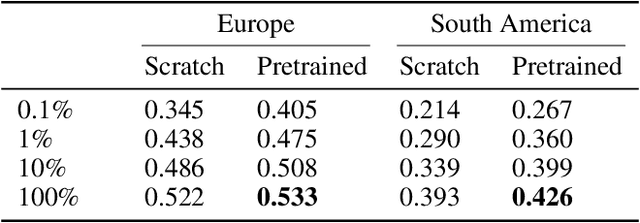
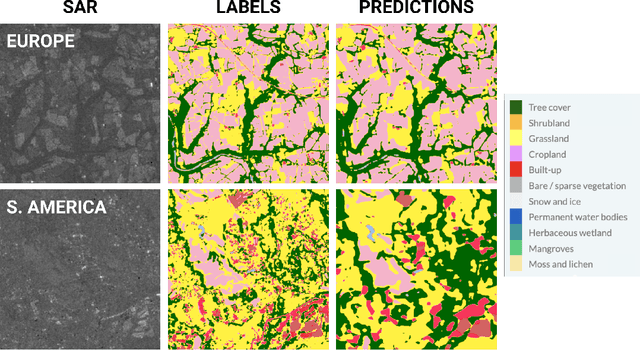
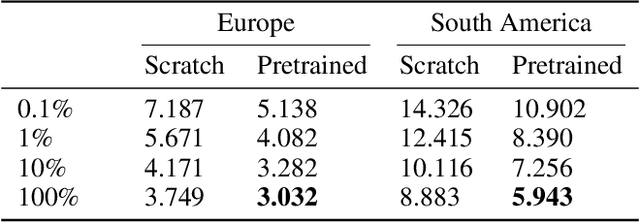
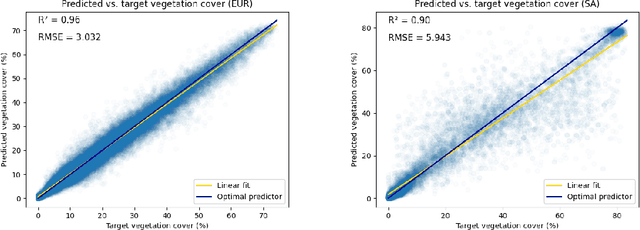
Satellite-based remote sensing is instrumental in the monitoring and mitigation of the effects of anthropogenic climate change. Large scale, high resolution data derived from these sensors can be used to inform intervention and policy decision making, but the timeliness and accuracy of these interventions is limited by use of optical data, which cannot operate at night and is affected by adverse weather conditions. Synthetic Aperture Radar (SAR) offers a robust alternative to optical data, but its associated complexities limit the scope of labelled data generation for traditional deep learning. In this work, we apply a self-supervised pretraining scheme, masked autoencoding, to SAR amplitude data covering 8.7\% of the Earth's land surface area, and tune the pretrained weights on two downstream tasks crucial to monitoring climate change - vegetation cover prediction and land cover classification. We show that the use of this pretraining scheme reduces labelling requirements for the downstream tasks by more than an order of magnitude, and that this pretraining generalises geographically, with the performance gain increasing when tuned downstream on regions outside the pretraining set. Our findings significantly advance climate change mitigation by facilitating the development of task and region-specific SAR models, allowing local communities and organizations to deploy tailored solutions for rapid, accurate monitoring of climate change effects.
Fewshot learning on global multimodal embeddings for earth observation tasks
Sep 29, 2023In this work we pretrain a CLIP/ViT based model using three different modalities of satellite imagery across five AOIs covering over ~10\% of the earth total landmass, namely Sentinel 2 RGB optical imagery, Sentinel 1 SAR amplitude and Sentinel 1 SAR interferometric coherence. This model uses $\sim 250$ M parameters. Then, we use the embeddings produced for each modality with a classical machine learning method to attempt different downstream tasks for earth observation related to vegetation, built up surface, croplands and permanent water. We consistently show how we reduce the need for labeled data by 99\%, so that with ~200-500 randomly selected labeled examples (around 4K-10K km$^2$) we reach performance levels analogous to those achieved with the full labeled datasets (about 150K image chips or 3M km$^2$ in each AOI) on all modalities, AOIs and downstream tasks. This leads us to think that the model has captured significant earth features useful in a wide variety of scenarios. To enhance our model's usability in practice, its architecture allows inference in contexts with missing modalities and even missing channels within each modality. Additionally, we visually show that this embedding space, obtained with no labels, is sensible to the different earth features represented by the labelled datasets we selected.
AI applications in forest monitoring need remote sensing benchmark datasets
Dec 20, 2022With the rise in high resolution remote sensing technologies there has been an explosion in the amount of data available for forest monitoring, and an accompanying growth in artificial intelligence applications to automatically derive forest properties of interest from these datasets. Many studies use their own data at small spatio-temporal scales, and demonstrate an application of an existing or adapted data science method for a particular task. This approach often involves intensive and time-consuming data collection and processing, but generates results restricted to specific ecosystems and sensor types. There is a lack of widespread acknowledgement of how the types and structures of data used affects performance and accuracy of analysis algorithms. To accelerate progress in the field more efficiently, benchmarking datasets upon which methods can be tested and compared are sorely needed. Here, we discuss how lack of standardisation impacts confidence in estimation of key forest properties, and how considerations of data collection need to be accounted for in assessing method performance. We present pragmatic requirements and considerations for the creation of rigorous, useful benchmarking datasets for forest monitoring applications, and discuss how tools from modern data science can improve use of existing data. We list a set of example large-scale datasets that could contribute to benchmarking, and present a vision for how community-driven, representative benchmarking initiatives could benefit the field.