 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring DINO: Emergent Properties and Limitations for Synthetic Aperture Radar Imagery
Paper and Code
Oct 05, 2023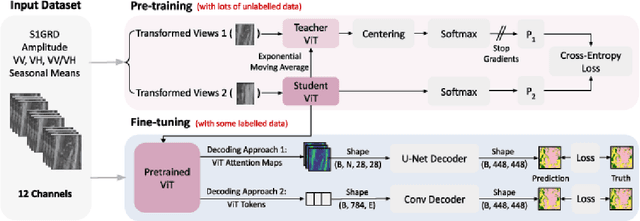
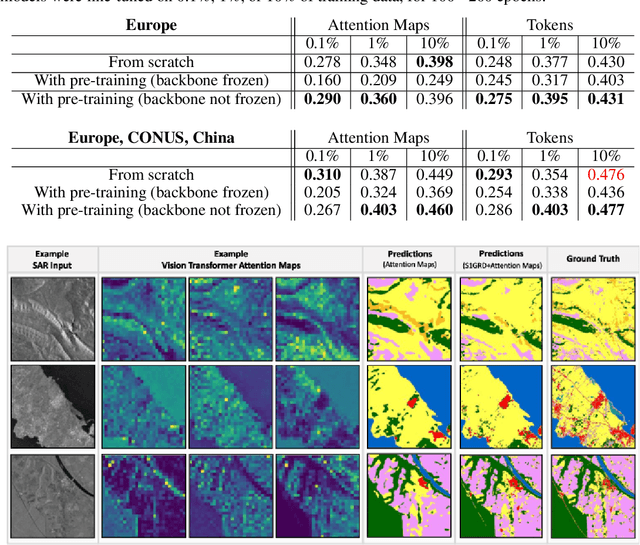
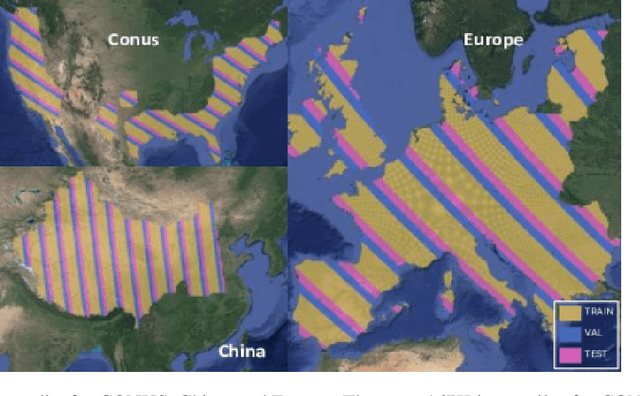
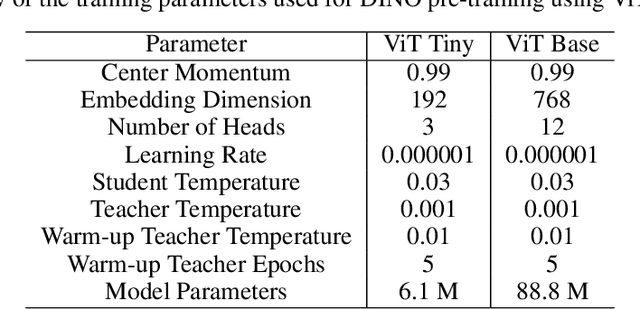
Self-supervised learning (SSL) models have recently demonstrated remarkable performance across various tasks, including image segmentation. This study delves into the emergent characteristics of the Self-Distillation with No Labels (DINO) algorithm and its application to Synthetic Aperture Radar (SAR) imagery. We pre-train a vision transformer (ViT)-based DINO model using unlabeled SAR data, and later fine-tune the model to predict high-resolution land cover maps. We rigorously evaluate the utility of attention maps generated by the ViT backbone, and compare them with the model's token embedding space. We observe a small improvement in model performance with pre-training compared to training from scratch, and discuss the limitations and opportunities of SSL for remote sensing and land cover segmentation. Beyond small performance increases, we show that ViT attention maps hold great intrinsic value for remote sensing, and could provide useful inputs to other algorithms. With this, our work lays the ground-work for bigger and better SSL models for Earth Observation.