 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk of Transfer Learning and its Applications in Finance
Nov 06, 2023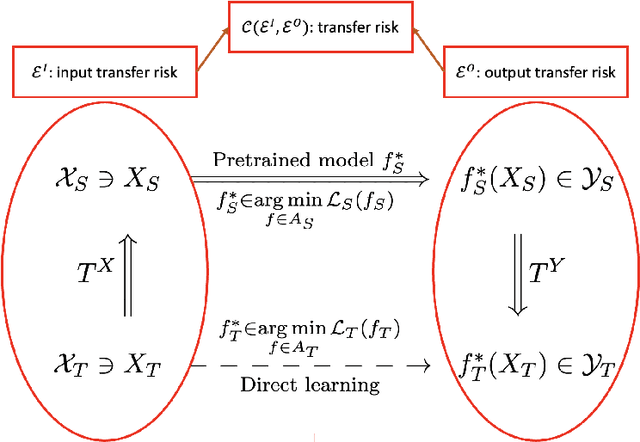
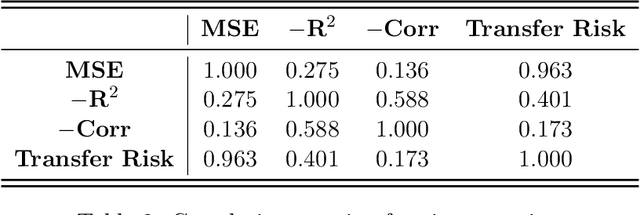
Transfer learning is an emerging and popular paradigm for utilizing existing knowledge from previous learning tasks to improve the performance of new ones. In this paper, we propose a novel concept of transfer risk and and analyze its properties to evaluate transferability of transfer learning. We apply transfer learning techniques and this concept of transfer risk to stock return prediction and portfolio optimization problems. Numerical results demonstrate a strong correlation between transfer risk and overall transfer learning performance, where transfer risk provides a computationally efficient way to identify appropriate source tasks in transfer learning, including cross-continent, cross-sector, and cross-frequency transfer for portfolio optimization.
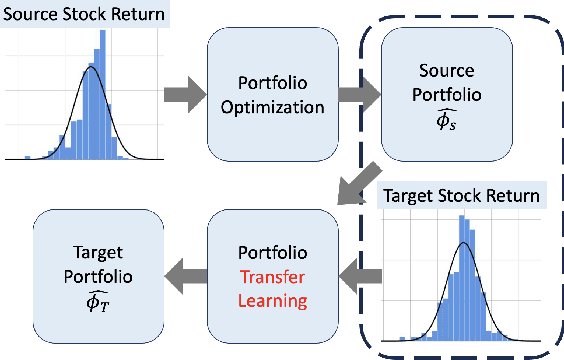
Transfer Learning for Portfolio Optimization
Jul 25, 2023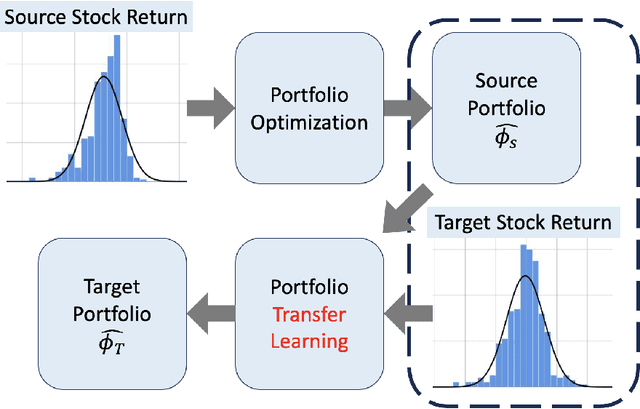

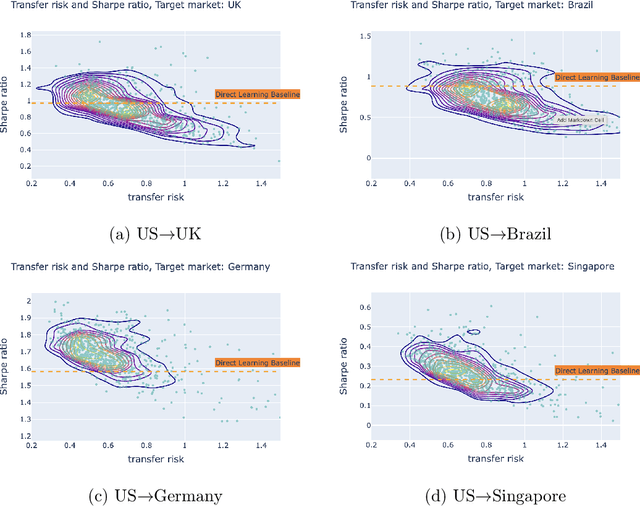
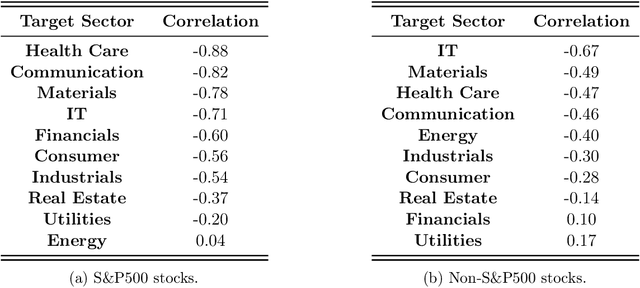
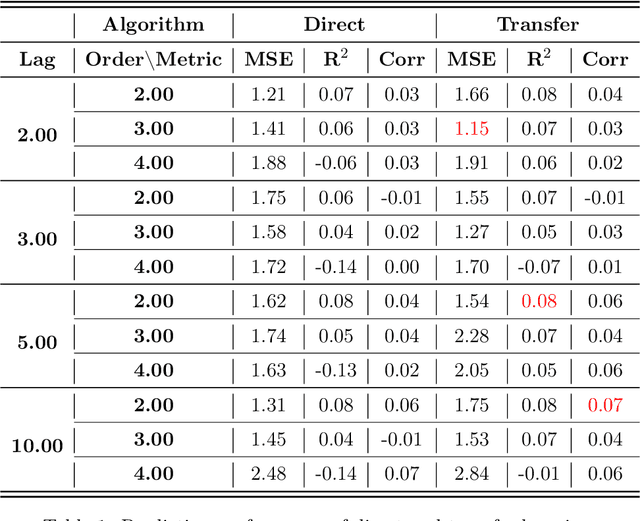
In this work, we explore the possibility of utilizing transfer learning techniques to address the financial portfolio optimization problem. We introduce a novel concept called "transfer risk", within the optimization framework of transfer learning. A series of numerical experiments are conducted from three categories: cross-continent transfer, cross-sector transfer, and cross-frequency transfer. In particular, 1. a strong correlation between the transfer risk and the overall performance of transfer learning methods is established, underscoring the significance of transfer risk as a viable indicator of "transferability"; 2. transfer risk is shown to provide a computationally efficient way to identify appropriate source tasks in transfer learning, enhancing the efficiency and effectiveness of the transfer learning approach; 3. additionally, the numerical experiments offer valuable new insights for portfolio management across these different settings.
Towards systematic intraday news screening: a liquidity-focused approach
Apr 11, 2023News can convey bearish or bullish views on financial assets. Institutional investors need to evaluate automatically the implied news sentiment based on textual data. Given the huge amount of news articles published each day, most of which are neutral, we present a systematic news screening method to identify the ``true'' impactful ones, aiming for more effective development of news sentiment learning methods. Based on several liquidity-driven variables, including volatility, turnover, bid-ask spread, and book size, we associate each 5-min time bin to one of two specific liquidity modes. One represents the ``calm'' state at which the market stays for most of the time and the other, featured with relatively higher levels of volatility and trading volume, describes the regime driven by some exogenous events. Then we focus on the moments where the liquidity mode switches from the former to the latter and consider the news articles published nearby impactful. We apply naive Bayes on these filtered samples for news sentiment classification as an illustrative example. We show that the screened dataset leads to more effective feature capturing and thus superior performance on short-term asset return prediction compared to the original dataset.
Feasibility and Transferability of Transfer Learning: A Mathematical Framework
Jan 27, 2023
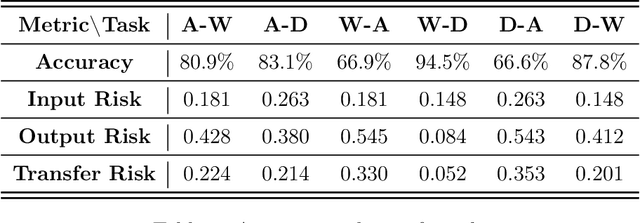
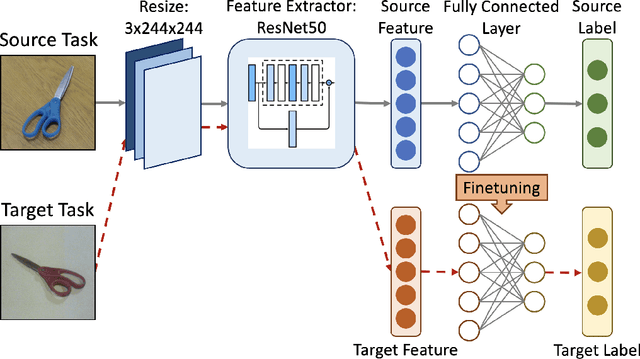
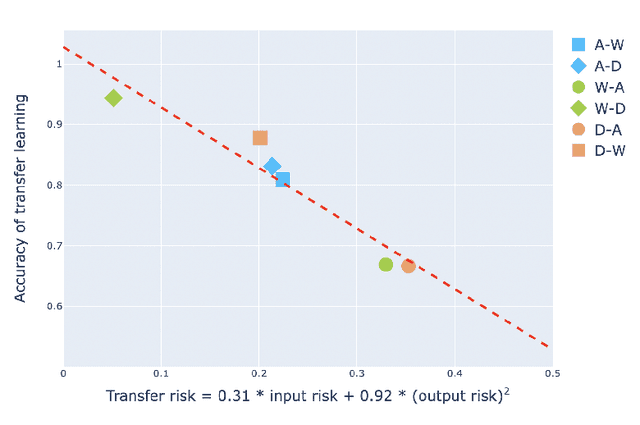
Transfer learning is an emerging and popular paradigm for utilizing existing knowledge from previous learning tasks to improve the performance of new ones. Despite its numerous empirical successes, theoretical analysis for transfer learning is limited. In this paper we build for the first time, to the best of our knowledge, a mathematical framework for the general procedure of transfer learning. Our unique reformulation of transfer learning as an optimization problem allows for the first time, analysis of its feasibility. Additionally, we propose a novel concept of transfer risk to evaluate transferability of transfer learning. Our numerical studies using the Office-31 dataset demonstrate the potential and benefits of incorporating transfer risk in the evaluation of transfer learning performance.
Towards mapping the contemporary art world with ArtLM: an art-specific NLP model
Dec 22, 2022With an increasing amount of data in the art world, discovering artists and artworks suitable to collectors' tastes becomes a challenge. It is no longer enough to use visual information, as contextual information about the artist has become just as important in contemporary art. In this work, we present a generic Natural Language Processing framework (called ArtLM) to discover the connections among contemporary artists based on their biographies. In this approach, we first continue to pre-train the existing general English language models with a large amount of unlabelled art-related data. We then fine-tune this new pre-trained model with our biography pair dataset manually annotated by a team of professionals in the art industry. With extensive experiments, we demonstrate that our ArtLM achieves 85.6% accuracy and 84.0% F1 score and outperforms other baseline models. We also provide a visualisation and a qualitative analysis of the artist network built from ArtLM's outputs.
Docent: A content-based recommendation system to discover contemporary art
Jul 12, 2022
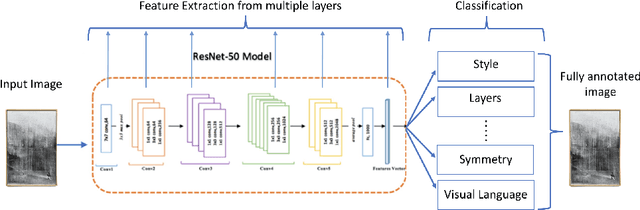
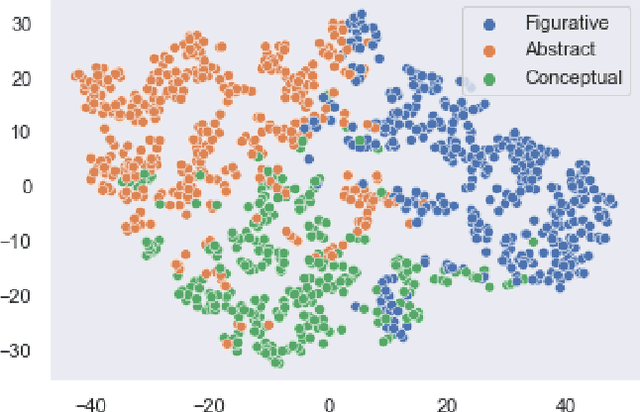
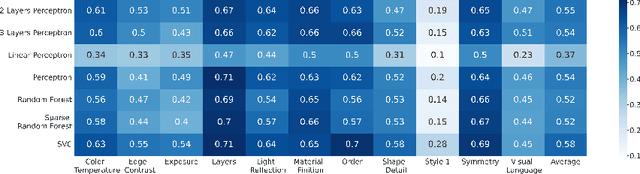
Recommendation systems have been widely used in various domains such as music, films, e-shopping etc. After mostly avoiding digitization, the art world has recently reached a technological turning point due to the pandemic, making online sales grow significantly as well as providing quantitative online data about artists and artworks. In this work, we present a content-based recommendation system on contemporary art relying on images of artworks and contextual metadata of artists. We gathered and annotated artworks with advanced and art-specific information to create a completely unique database that was used to train our models. With this information, we built a proximity graph between artworks. Similarly, we used NLP techniques to characterize the practices of the artists and we extracted information from exhibitions and other event history to create a proximity graph between artists. The power of graph analysis enables us to provide an artwork recommendation system based on a combination of visual and contextual information from artworks and artists. After an assessment by a team of art specialists, we get an average final rating of 75% of meaningful artworks when compared to their professional evaluations.
On the universality of the volatility formation process: when machine learning and rough volatility agree
Jun 28, 2022
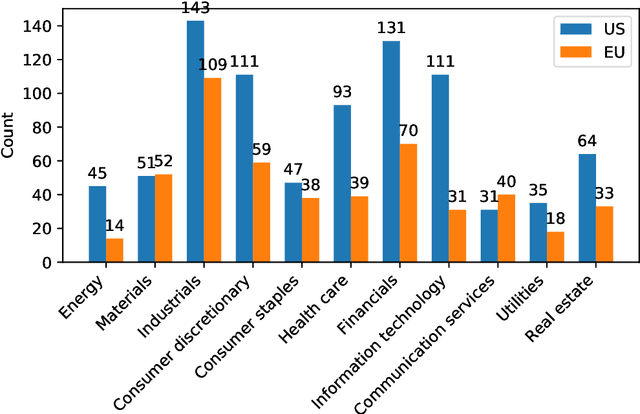
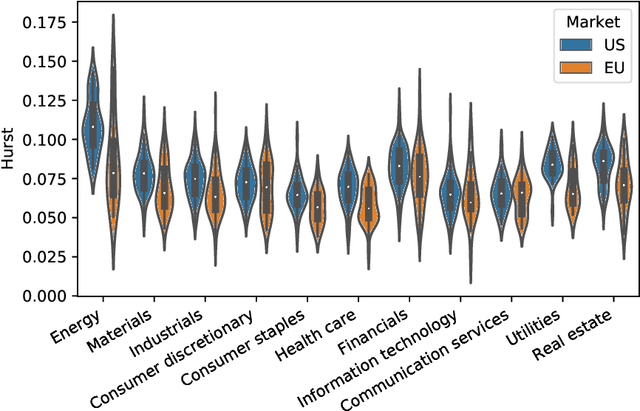
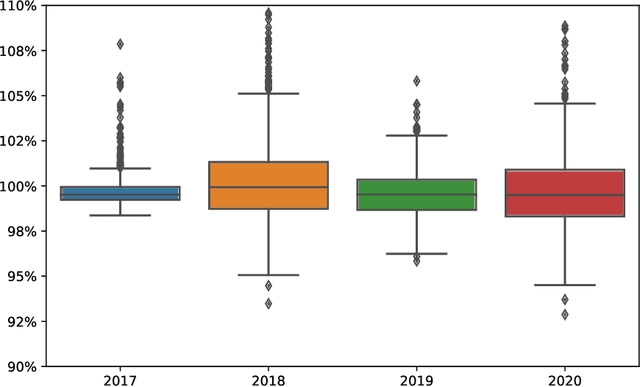
We train an LSTM network based on a pooled dataset made of hundreds of liquid stocks aiming to forecast the next daily realized volatility for all stocks. Showing the consistent outperformance of this universal LSTM relative to other asset-specific parametric models, we uncover nonparametric evidences of a universal volatility formation mechanism across assets relating past market realizations, including daily returns and volatilities, to current volatilities. A parsimonious parametric forecasting device combining the rough fractional stochastic volatility and quadratic rough Heston models with fixed parameters results in the same level of performance as the universal LSTM, which confirms the universality of the volatility formation process from a parametric perspective.
An $\{l_1,l_2,l_{\infty}\}$-Regularization Approach to High-Dimensional Errors-in-variables Models
Dec 22, 2014
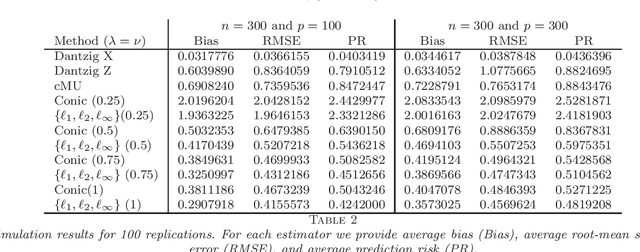
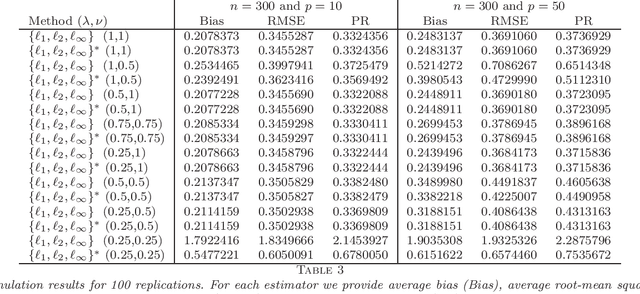
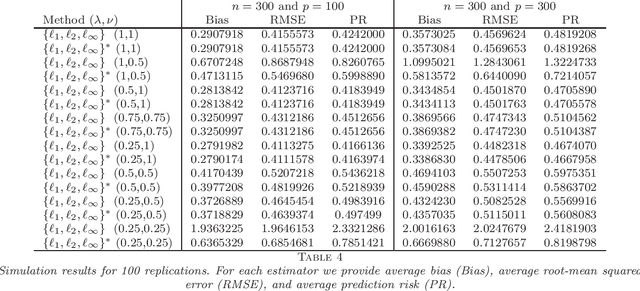
Several new estimation methods have been recently proposed for the linear regression model with observation error in the design. Different assumptions on the data generating process have motivated different estimators and analysis. In particular, the literature considered (1) observation errors in the design uniformly bounded by some $\bar \delta$, and (2) zero mean independent observation errors. Under the first assumption, the rates of convergence of the proposed estimators depend explicitly on $\bar \delta$, while the second assumption has been applied when an estimator for the second moment of the observational error is available. This work proposes and studies two new estimators which, compared to other procedures for regression models with errors in the design, exploit an additional $l_{\infty}$-norm regularization. The first estimator is applicable when both (1) and (2) hold but does not require an estimator for the second moment of the observational error. The second estimator is applicable under (2) and requires an estimator for the second moment of the observation error. Importantly, we impose no assumption on the accuracy of this pilot estimator, in contrast to the previously known procedures. As the recent proposals, we allow the number of covariates to be much larger than the sample size. We establish the rates of convergence of the estimators and compare them with the bounds obtained for related estimators in the literature. These comparisons show interesting insights on the interplay of the assumptions and the achievable rates of convergence.