 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning Language Models for Context-Specific SQL Query Generation
Dec 04, 2023

The ability to generate SQL queries from natural language has significant implications for making data accessible to non-specialists. This paper presents a novel approach to fine-tuning open-source large language models (LLMs) for the task of transforming natural language into SQL queries within the retail domain. We introduce models specialized in generating SQL queries, trained on synthetic datasets tailored to the Snowflake SQL and GoogleSQL dialects. Our methodology involves generating a context-specific dataset using GPT-4, then fine-tuning three open-source LLMs(Starcoder Plus, Code-Llama, and Mistral) employing the LoRa technique to optimize for resource constraints. The fine-tuned models demonstrate superior performance in zero-shot settings compared to the baseline GPT-4, with Code-Llama achieving the highest accuracy rates, at 81.58% for Snowflake SQL and 82.66% for GoogleSQL. These results underscore the effectiveness of fine-tuning LLMs on domain-specific tasks and suggest a promising direction for enhancing the accessibility of relational databases through natural language interfaces.
Towards mapping the contemporary art world with ArtLM: an art-specific NLP model
Dec 22, 2022With an increasing amount of data in the art world, discovering artists and artworks suitable to collectors' tastes becomes a challenge. It is no longer enough to use visual information, as contextual information about the artist has become just as important in contemporary art. In this work, we present a generic Natural Language Processing framework (called ArtLM) to discover the connections among contemporary artists based on their biographies. In this approach, we first continue to pre-train the existing general English language models with a large amount of unlabelled art-related data. We then fine-tune this new pre-trained model with our biography pair dataset manually annotated by a team of professionals in the art industry. With extensive experiments, we demonstrate that our ArtLM achieves 85.6% accuracy and 84.0% F1 score and outperforms other baseline models. We also provide a visualisation and a qualitative analysis of the artist network built from ArtLM's outputs.
Docent: A content-based recommendation system to discover contemporary art
Jul 12, 2022
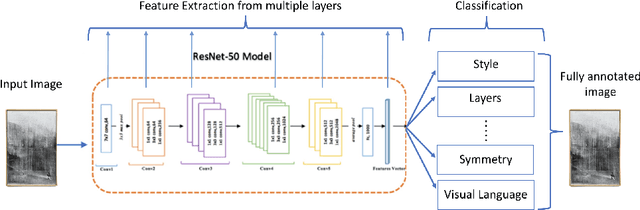
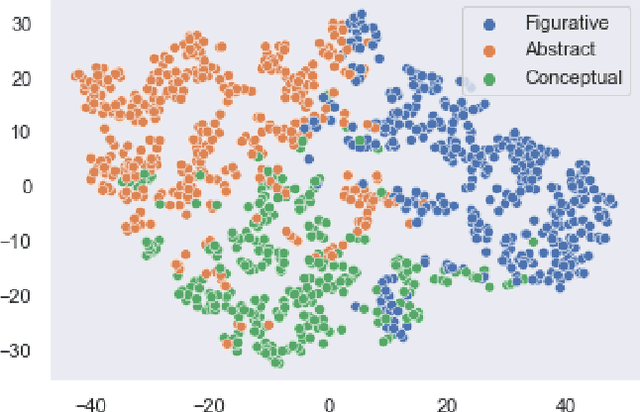
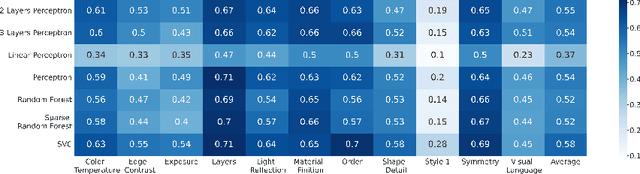
Recommendation systems have been widely used in various domains such as music, films, e-shopping etc. After mostly avoiding digitization, the art world has recently reached a technological turning point due to the pandemic, making online sales grow significantly as well as providing quantitative online data about artists and artworks. In this work, we present a content-based recommendation system on contemporary art relying on images of artworks and contextual metadata of artists. We gathered and annotated artworks with advanced and art-specific information to create a completely unique database that was used to train our models. With this information, we built a proximity graph between artworks. Similarly, we used NLP techniques to characterize the practices of the artists and we extracted information from exhibitions and other event history to create a proximity graph between artists. The power of graph analysis enables us to provide an artwork recommendation system based on a combination of visual and contextual information from artworks and artists. After an assessment by a team of art specialists, we get an average final rating of 75% of meaningful artworks when compared to their professional evaluations.