 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel free Shapley values for high dimensional data
Nov 15, 2022



A model-agnostic variable importance method can be used with arbitrary prediction functions. Here we present some model-free methods that do not require access to the prediction function. This is useful when that function is proprietary and not available, or just extremely expensive. It is also useful when studying residuals from a model. The cohort Shapley (CS) method is model-free but has exponential cost in the dimension of the input space. A supervised on-manifold Shapley method from Frye et al. (2020) is also model free but requires as input a second black box model that has to be trained for the Shapley value problem. We introduce an integrated gradient version of cohort Shapley, called IGCS, with cost $\mathcal{O}(nd)$. We show that over the vast majority of the relevant unit cube that the IGCS value function is close to a multilinear function for which IGCS matches CS. We use some area under the curve (AUC) measures to quantify the performance of IGCS. On a problem from high energy physics we verify that IGCS has nearly the same AUCs as CS. We also use it on a problem from computational chemistry in 1024 variables. We see there that IGCS attains much higher AUCs than we get from Monte Carlo sampling. The code is publicly available at https://github.com/cohortshapley/cohortintgrad.
Variable importance without impossible data
May 31, 2022
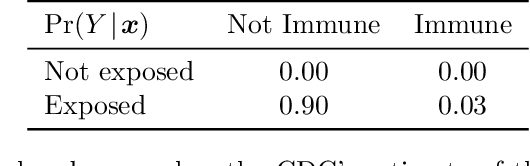

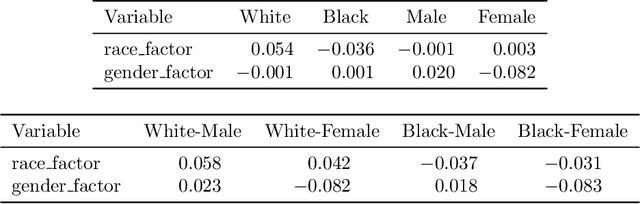
The most popular methods for measuring importance of the variables in a black box prediction algorithm make use of synthetic inputs that combine predictor variables from multiple subjects. These inputs can be unlikely, physically impossible, or even logically impossible. As a result, the predictions for such cases can be based on data very unlike any the black box was trained on. We think that users cannot trust an explanation of the decision of a prediction algorithm when the explanation uses such values. Instead we advocate a method called Cohort Shapley that is grounded in economic game theory and unlike most other game theoretic methods, it uses only actually observed data to quantify variable importance. Cohort Shapley works by narrowing the cohort of subjects judged to be similar to a target subject on one or more features. A feature is important if using it to narrow the cohort makes a large difference to the cohort mean. We illustrate it on an algorithmic fairness problem where it is essential to attribute importance to protected variables that the model was not trained on. For every subject and every predictor variable, we can compute the importance of that predictor to the subject's predicted response or to their actual response. These values can be aggregated, for example over all Black subjects, and we propose a Bayesian bootstrap to quantify uncertainty in both individual and aggregate Shapley values.
Deletion and Insertion Tests in Regression Models
May 25, 2022



A basic task in explainable AI (XAI) is to identify the most important features behind a prediction made by a black box function $f$. The insertion and deletion tests of \cite{petsiuk2018rise} are used to judge the quality of algorithms that rank pixels from most to least important for a classification. Motivated by regression problems we establish a formula for their area under the curve (AUC) criteria in terms of certain main effects and interactions in an anchored decomposition of $f$. We find an expression for the expected value of the AUC under a random ordering of inputs to $f$ and propose an alternative area above a straight line for the regression setting. We use this criterion to compare feature importances computed by integrated gradients (IG) to those computed by Kernel SHAP (KS). Exact computation of KS grows exponentially with dimension, while that of IG grows linearly with dimension. In two data sets including binary variables we find that KS is superior to IG in insertion and deletion tests, but only by a very small amount. Our comparison problems include some binary inputs that pose a challenge to IG because it must use values between the possible variable levels. We show that IG will match KS when $f$ is an additive function plus a multilinear function of the variables. This includes a multilinear interpolation over the binary variables that would cause IG to have exponential cost in a naive implementation.
What makes you unique?
May 17, 2021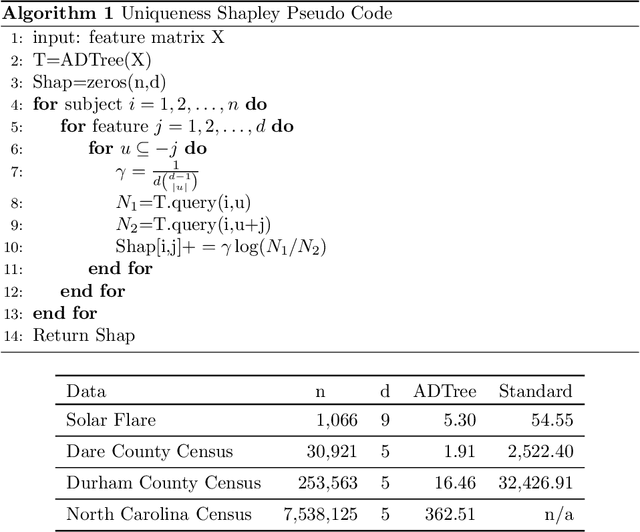
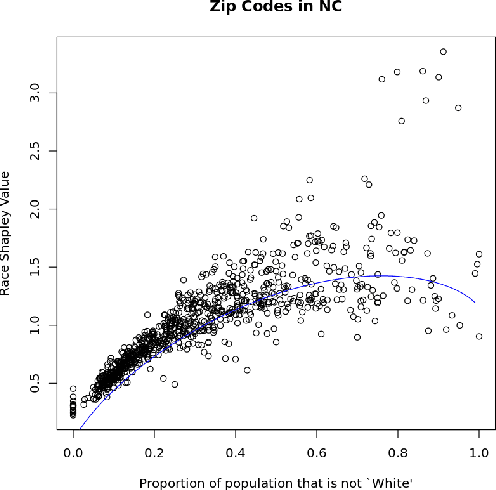

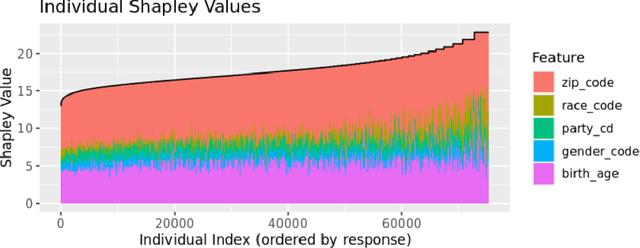
This paper proposes a uniqueness Shapley measure to compare the extent to which different variables are able to identify a subject. Revealing the value of a variable on subject $t$ shrinks the set of possible subjects that $t$ could be. The extent of the shrinkage depends on which other variables have also been revealed. We use Shapley value to combine all of the reductions in log cardinality due to revealing a variable after some subset of the other variables has been revealed. This uniqueness Shapley measure can be aggregated over subjects where it becomes a weighted sum of conditional entropies. Aggregation over subsets of subjects can address questions like how identifying is age for people of a given zip code. Such aggregates have a corresponding expression in terms of cross entropies. We use uniqueness Shapley to investigate the differential effects of revealing variables from the North Carolina voter registration rolls and in identifying anomalous solar flares. An enormous speedup (approaching 2000 fold in one example) is obtained by using the all dimension trees of Moore and Lee (1998) to store the cardinalities we need.
Cohort Shapley value for algorithmic fairness
May 15, 2021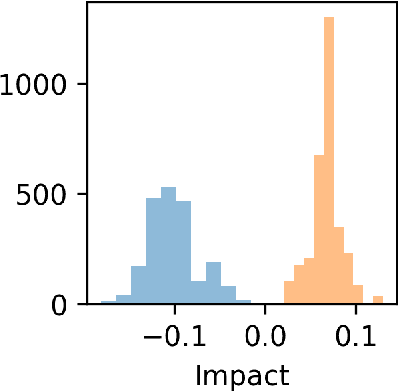

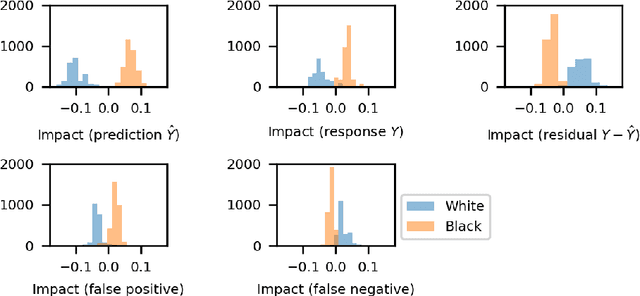

Cohort Shapley value is a model-free method of variable importance grounded in game theory that does not use any unobserved and potentially impossible feature combinations. We use it to evaluate algorithmic fairness, using the well known COMPAS recidivism data as our example. This approach allows one to identify for each individual in a data set the extent to which they were adversely or beneficially affected by their value of a protected attribute such as their race. The method can do this even if race was not one of the original predictors and even if it does not have access to a proprietary algorithm that has made the predictions. The grounding in game theory lets us define aggregate variable importance for a data set consistently with its per subject definitions. We can investigate variable importance for multiple quantities of interest in the fairness literature including false positive predictions.
Explaining black box decisions by Shapley cohort refinement
Nov 01, 2019


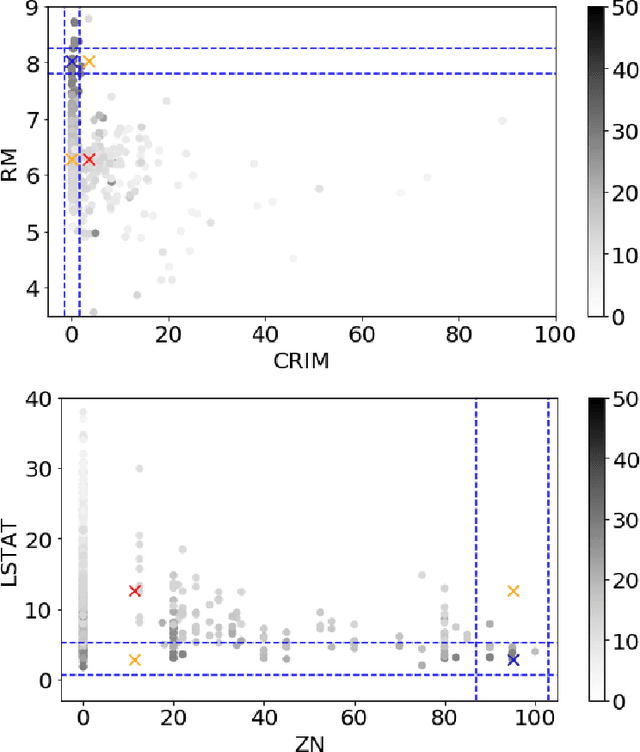
We introduce a variable importance measure to explain the importance of individual variables to a decision made by a black box function. Our measure is based on the Shapley value from cooperative game theory. Measures of variable importance usually work by changing the value of one or more variables with the others held fixed and then recomputing the function of interest. That approach is problematic because it can create very unrealistic combinations of predictors that never appear in practice or that were never present when the prediction function was being created. Our cohort refinement Shapley approach measures variable importance without using any data points that were not actually observed.