 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariable importance without impossible data
May 31, 2022
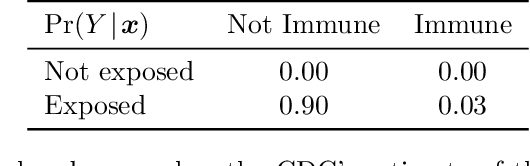

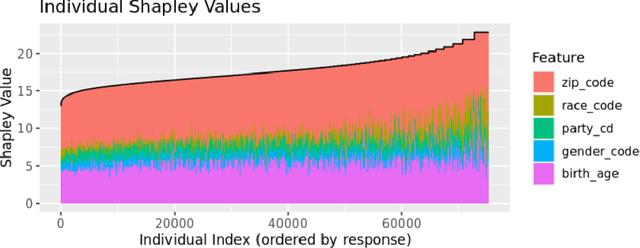
The most popular methods for measuring importance of the variables in a black box prediction algorithm make use of synthetic inputs that combine predictor variables from multiple subjects. These inputs can be unlikely, physically impossible, or even logically impossible. As a result, the predictions for such cases can be based on data very unlike any the black box was trained on. We think that users cannot trust an explanation of the decision of a prediction algorithm when the explanation uses such values. Instead we advocate a method called Cohort Shapley that is grounded in economic game theory and unlike most other game theoretic methods, it uses only actually observed data to quantify variable importance. Cohort Shapley works by narrowing the cohort of subjects judged to be similar to a target subject on one or more features. A feature is important if using it to narrow the cohort makes a large difference to the cohort mean. We illustrate it on an algorithmic fairness problem where it is essential to attribute importance to protected variables that the model was not trained on. For every subject and every predictor variable, we can compute the importance of that predictor to the subject's predicted response or to their actual response. These values can be aggregated, for example over all Black subjects, and we propose a Bayesian bootstrap to quantify uncertainty in both individual and aggregate Shapley values.
What makes you unique?
May 17, 2021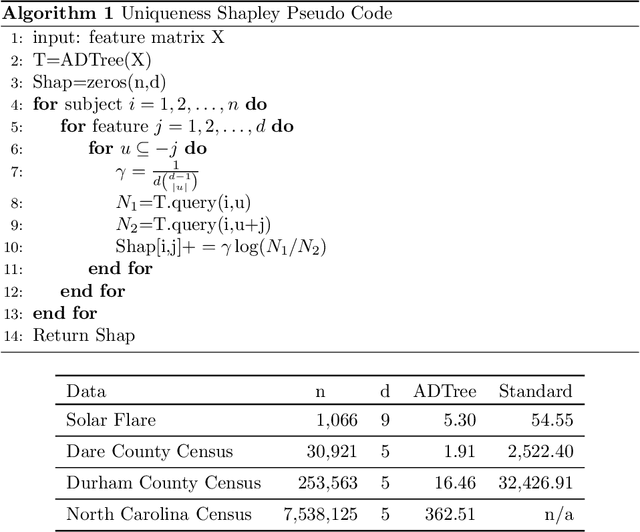
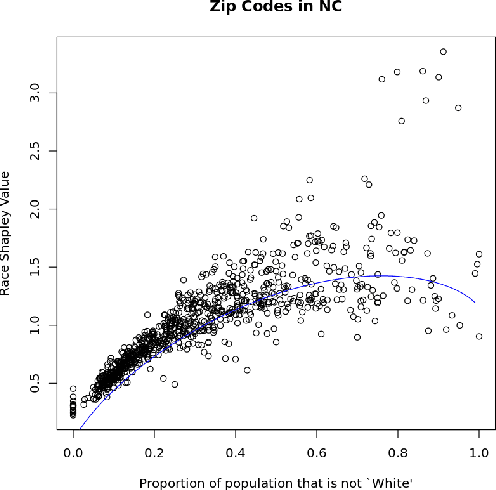

This paper proposes a uniqueness Shapley measure to compare the extent to which different variables are able to identify a subject. Revealing the value of a variable on subject $t$ shrinks the set of possible subjects that $t$ could be. The extent of the shrinkage depends on which other variables have also been revealed. We use Shapley value to combine all of the reductions in log cardinality due to revealing a variable after some subset of the other variables has been revealed. This uniqueness Shapley measure can be aggregated over subjects where it becomes a weighted sum of conditional entropies. Aggregation over subsets of subjects can address questions like how identifying is age for people of a given zip code. Such aggregates have a corresponding expression in terms of cross entropies. We use uniqueness Shapley to investigate the differential effects of revealing variables from the North Carolina voter registration rolls and in identifying anomalous solar flares. An enormous speedup (approaching 2000 fold in one example) is obtained by using the all dimension trees of Moore and Lee (1998) to store the cardinalities we need.
Cohort Shapley value for algorithmic fairness
May 15, 2021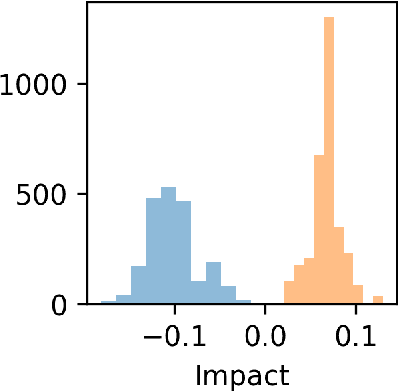

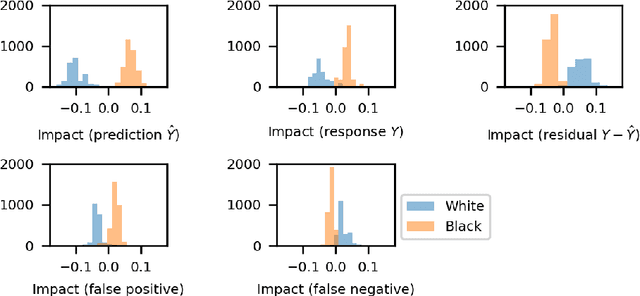

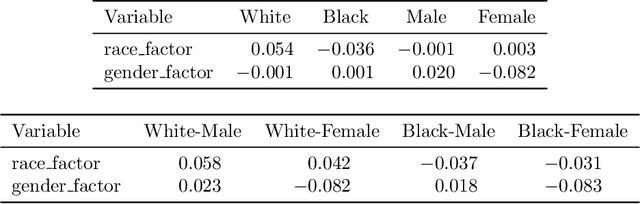
Cohort Shapley value is a model-free method of variable importance grounded in game theory that does not use any unobserved and potentially impossible feature combinations. We use it to evaluate algorithmic fairness, using the well known COMPAS recidivism data as our example. This approach allows one to identify for each individual in a data set the extent to which they were adversely or beneficially affected by their value of a protected attribute such as their race. The method can do this even if race was not one of the original predictors and even if it does not have access to a proprietary algorithm that has made the predictions. The grounding in game theory lets us define aggregate variable importance for a data set consistently with its per subject definitions. We can investigate variable importance for multiple quantities of interest in the fairness literature including false positive predictions.