 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariable importance without impossible data
Paper and Code

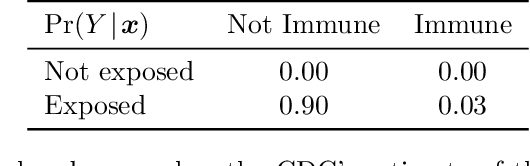

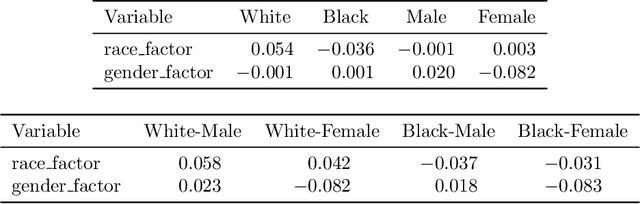
The most popular methods for measuring importance of the variables in a black box prediction algorithm make use of synthetic inputs that combine predictor variables from multiple subjects. These inputs can be unlikely, physically impossible, or even logically impossible. As a result, the predictions for such cases can be based on data very unlike any the black box was trained on. We think that users cannot trust an explanation of the decision of a prediction algorithm when the explanation uses such values. Instead we advocate a method called Cohort Shapley that is grounded in economic game theory and unlike most other game theoretic methods, it uses only actually observed data to quantify variable importance. Cohort Shapley works by narrowing the cohort of subjects judged to be similar to a target subject on one or more features. A feature is important if using it to narrow the cohort makes a large difference to the cohort mean. We illustrate it on an algorithmic fairness problem where it is essential to attribute importance to protected variables that the model was not trained on. For every subject and every predictor variable, we can compute the importance of that predictor to the subject's predicted response or to their actual response. These values can be aggregated, for example over all Black subjects, and we propose a Bayesian bootstrap to quantify uncertainty in both individual and aggregate Shapley values.