 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMax-Margin Works while Large Margin Fails: Generalization without Uniform Convergence
Jun 16, 2022
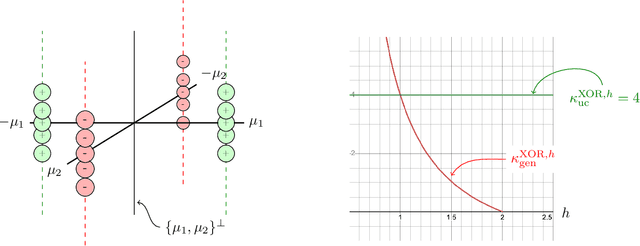
A major challenge in modern machine learning is theoretically understanding the generalization properties of overparameterized models. Many existing tools rely on \em uniform convergence \em (UC), a property that, when it holds, guarantees that the test loss will be close to the training loss, uniformly over a class of candidate models. Nagarajan and Kolter (2019) show that in certain simple linear and neural-network settings, any uniform convergence bound will be vacuous, leaving open the question of how to prove generalization in settings where UC fails. Our main contribution is proving novel generalization bounds in two such settings, one linear, and one non-linear. We study the linear classification setting of Nagarajan and Kolter, and a quadratic ground truth function learned via a two-layer neural network in the non-linear regime. We prove a new type of margin bound showing that above a certain signal-to-noise threshold, any near-max-margin classifier will achieve almost no test loss in these two settings. Our results show that near-max-margin is important: while any model that achieves at least a $(1 - \epsilon)$-fraction of the max-margin generalizes well, a classifier achieving half of the max-margin may fail terribly. We additionally strengthen the UC impossibility results of Nagarajan and Kolter, proving that \em one-sided \em UC bounds and classical margin bounds will fail on near-max-margin classifiers. Our analysis provides insight on why memorization can coexist with generalization: we show that in this challenging regime where generalization occurs but UC fails, near-max-margin classifiers simultaneously contain some generalizable components and some overfitting components that memorize the data. The presence of the overfitting components is enough to preclude UC, but the near-extremal margin guarantees that sufficient generalizable components are present.
Asynchronous Distributed Optimization with Randomized Delays
Oct 02, 2020


In this work, we study asynchronous finite sum minimization in a distributed-data setting with a central parameter server. While asynchrony is well understood in parallel settings where the data is accessible by all machines, little is known for the distributed-data setting. We introduce a variant of SAGA called ADSAGA for the distributed-data setting where each machine stores a partition of the data. We show that with independent exponential work times -- a common assumption in distributed optimization -- ADSAGA converges in $\tilde{O}\left(\left(n + \sqrt{m}\kappa\right)\log(1/\epsilon)\right)$ iterations, where $n$ is the number of component functions, $m$ is the number of machines, and $\kappa$ is a condition number. We empirically compare the iteration complexity of ADSAGA to existing parallel and distributed algorithms, including synchronous mini-batch algorithms.
Approximate Gradient Coding with Optimal Decoding
Jun 17, 2020
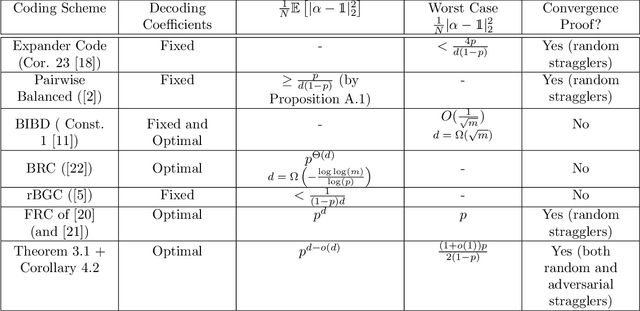

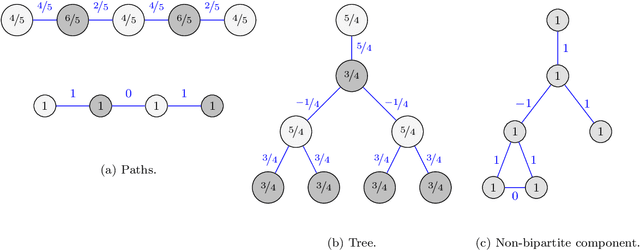
In distributed optimization problems, a technique called gradient coding, which involves replicating data points, has been used to mitigate the effect of straggling machines. Recent work has studied approximate gradient coding, which concerns coding schemes where the replication factor of the data is too low to recover the full gradient exactly. Our work is motivated by the challenge of creating approximate gradient coding schemes that simultaneously work well in both the adversarial and stochastic models. To that end, we introduce novel approximate gradient codes based on expander graphs, in which each machine receives exactly two blocks of data points. We analyze the decoding error both in the random and adversarial straggler setting, when optimal decoding coefficients are used. We show that in the random setting, our schemes achieve an error to the gradient that decays exponentially in the replication factor. In the adversarial setting, the error is nearly a factor of two smaller than any existing code with similar performance in the random setting. We show convergence bounds both in the random and adversarial setting for gradient descent under standard assumptions using our codes. In the random setting, our convergence rate improves upon block-box bounds. In the adversarial setting, we show that gradient descent can converge down to a noise floor that scales linearly with the adversarial error to the gradient. We demonstrate empirically that our schemes achieve near-optimal error in the random setting and converge faster than algorithms which do not use the optimal decoding coefficients.
Strategic Classification
Nov 22, 2015
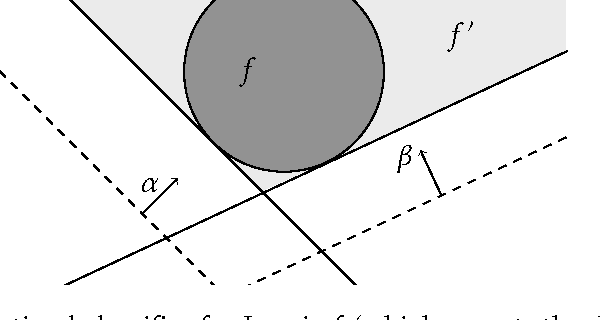
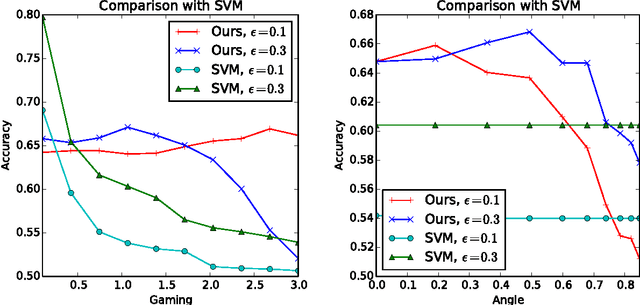
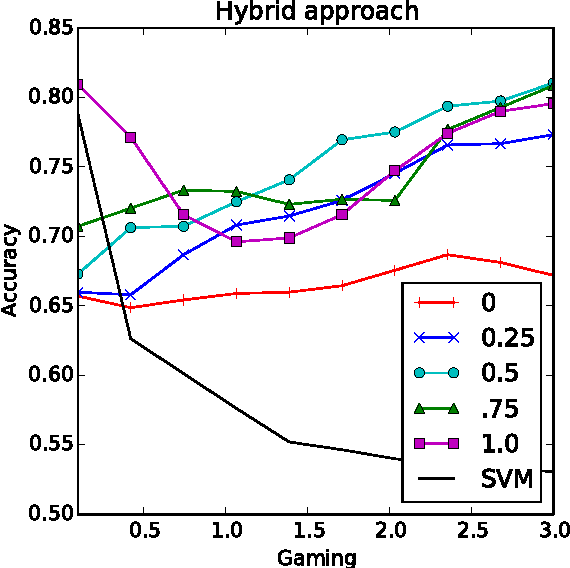
Machine learning relies on the assumption that unseen test instances of a classification problem follow the same distribution as observed training data. However, this principle can break down when machine learning is used to make important decisions about the welfare (employment, education, health) of strategic individuals. Knowing information about the classifier, such individuals may manipulate their attributes in order to obtain a better classification outcome. As a result of this behavior---often referred to as gaming---the performance of the classifier may deteriorate sharply. Indeed, gaming is a well-known obstacle for using machine learning methods in practice; in financial policy-making, the problem is widely known as Goodhart's law. In this paper, we formalize the problem, and pursue algorithms for learning classifiers that are robust to gaming. We model classification as a sequential game between a player named "Jury" and a player named "Contestant." Jury designs a classifier, and Contestant receives an input to the classifier, which he may change at some cost. Jury's goal is to achieve high classification accuracy with respect to Contestant's original input and some underlying target classification function. Contestant's goal is to achieve a favorable classification outcome while taking into account the cost of achieving it. For a natural class of cost functions, we obtain computationally efficient learning algorithms which are near-optimal. Surprisingly, our algorithms are efficient even on concept classes that are computationally hard to learn. For general cost functions, designing an approximately optimal strategy-proof classifier, for inverse-polynomial approximation, is NP-hard.
Fast matrix completion without the condition number
Jul 15, 2014
We give the first algorithm for Matrix Completion whose running time and sample complexity is polynomial in the rank of the unknown target matrix, linear in the dimension of the matrix, and logarithmic in the condition number of the matrix. To the best of our knowledge, all previous algorithms either incurred a quadratic dependence on the condition number of the unknown matrix or a quadratic dependence on the dimension of the matrix in the running time. Our algorithm is based on a novel extension of Alternating Minimization which we show has theoretical guarantees under standard assumptions even in the presence of noise.