 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategic Classification
Paper and Code
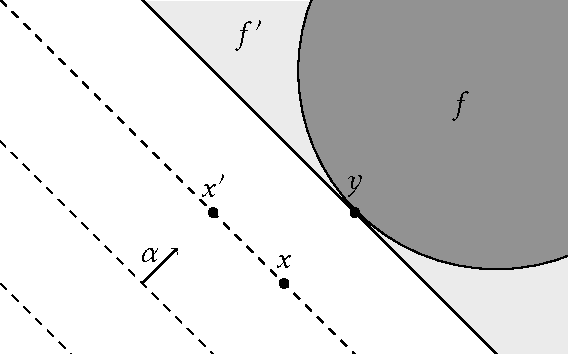
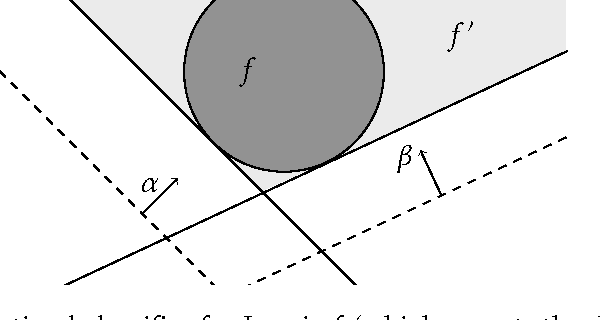
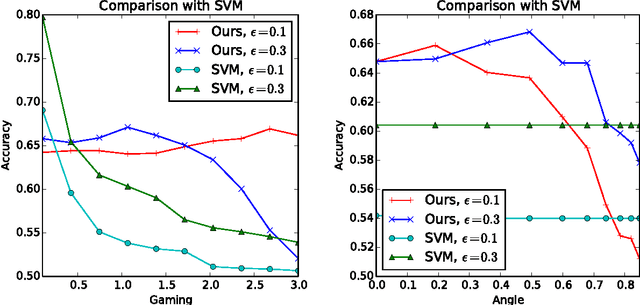
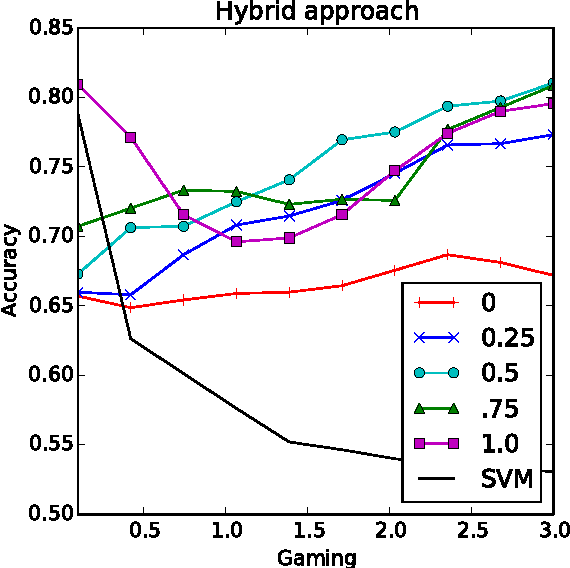
Machine learning relies on the assumption that unseen test instances of a classification problem follow the same distribution as observed training data. However, this principle can break down when machine learning is used to make important decisions about the welfare (employment, education, health) of strategic individuals. Knowing information about the classifier, such individuals may manipulate their attributes in order to obtain a better classification outcome. As a result of this behavior---often referred to as gaming---the performance of the classifier may deteriorate sharply. Indeed, gaming is a well-known obstacle for using machine learning methods in practice; in financial policy-making, the problem is widely known as Goodhart's law. In this paper, we formalize the problem, and pursue algorithms for learning classifiers that are robust to gaming. We model classification as a sequential game between a player named "Jury" and a player named "Contestant." Jury designs a classifier, and Contestant receives an input to the classifier, which he may change at some cost. Jury's goal is to achieve high classification accuracy with respect to Contestant's original input and some underlying target classification function. Contestant's goal is to achieve a favorable classification outcome while taking into account the cost of achieving it. For a natural class of cost functions, we obtain computationally efficient learning algorithms which are near-optimal. Surprisingly, our algorithms are efficient even on concept classes that are computationally hard to learn. For general cost functions, designing an approximately optimal strategy-proof classifier, for inverse-polynomial approximation, is NP-hard.