 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanetary Terrain Datasets and Benchmarks for Rover Path Planning
Dec 24, 2025
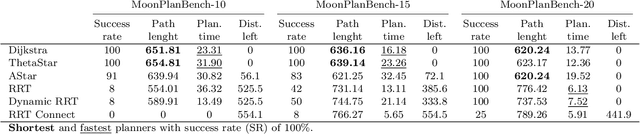
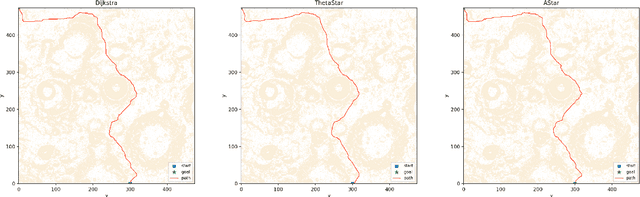
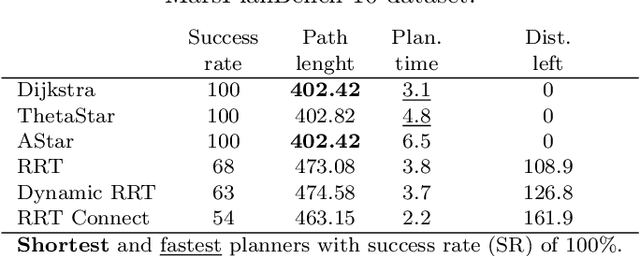
Planetary rover exploration is attracting renewed interest with several upcoming space missions to the Moon and Mars. However, a substantial amount of data from prior missions remain underutilized for path planning and autonomous navigation research. As a result, there is a lack of space mission-based planetary datasets, standardized benchmarks, and evaluation protocols. In this paper, we take a step towards coordinating these three research directions in the context of planetary rover path planning. We propose the first two large planar benchmark datasets, MarsPlanBench and MoonPlanBench, derived from high-resolution digital terrain images of Mars and the Moon. In addition, we set up classical and learned path planning algorithms, in a unified framework, and evaluate them on our proposed datasets and on a popular planning benchmark. Through comprehensive experiments, we report new insights on the performance of representative path planning algorithms on planetary terrains, for the first time to the best of our knowledge. Our results show that classical algorithms can achieve up to 100% global path planning success rates on average across challenging terrains such as Moon's north and south poles. This suggests, for instance, why these algorithms are used in practice by NASA. Conversely, learning-based models, although showing promising results in less complex environments, still struggle to generalize to planetary domains. To serve as a starting point for fundamental path planning research, our code and datasets will be released at: https://github.com/mchancan/PlanetaryPathBench.
RB5 Low-Cost Explorer: Implementing Autonomous Long-Term Exploration on Low-Cost Robotic Hardware
Feb 14, 2024

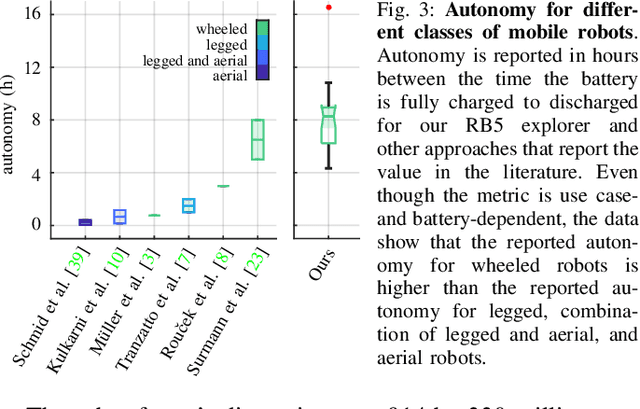

This systems paper presents the implementation and design of RB5, a wheeled robot for autonomous long-term exploration with fewer and cheaper sensors. Requiring just an RGB-D camera and low-power computing hardware, the system consists of an experimental platform with rocker-bogie suspension. It operates in unknown and GPS-denied environments and on indoor and outdoor terrains. The exploration consists of a methodology that extends frontier- and sampling-based exploration with a path-following vector field and a state-of-the-art SLAM algorithm. The methodology allows the robot to explore its surroundings at lower update frequencies, enabling the use of lower-performing and lower-cost hardware while still retaining good autonomous performance. The approach further consists of a methodology to interact with a remotely located human operator based on an inexpensive long-range and low-power communication technology from the internet-of-things domain (i.e., LoRa) and a customized communication protocol. The results and the feasibility analysis show the possible applications and limitations of the approach.
Energy-Aware Ergodic Search: Continuous Exploration for Multi-Agent Systems with Battery Constraints
Oct 14, 2023

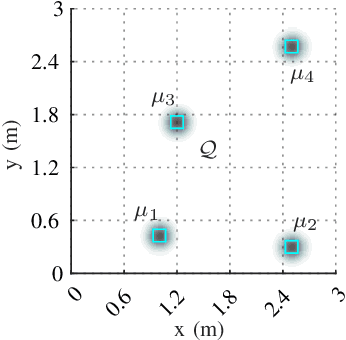

Autonomous exploration without interruption is important in scenarios such as search and rescue and precision agriculture, where consistent presence is needed to detect events over large areas. Ergodic search already derives continuous coverage trajectories in these scenarios so that a robot spends more time in areas with high information density. However, existing literature on ergodic search does not consider the robot's energy constraints, limiting how long a robot can explore. In fact, if the robots are battery-powered, it is physically not possible to continuously explore on a single battery charge. Our paper tackles this challenge by integrating ergodic search methods with energy-aware coverage. We trade off battery usage and coverage quality, maintaining uninterrupted exploration of a given space by at least one agent. Our approach derives an abstract battery model for future state-of-charge estimation and extends canonical ergodic search to ergodic search under battery constraints. Empirical data from simulations and real-world experiments demonstrate the effectiveness of our energy-aware ergodic search, which ensures continuous and uninterrupted exploration and guarantees spatial coverage.
Sequential Place Learning: Heuristic-Free High-Performance Long-Term Place Recognition
Mar 02, 2021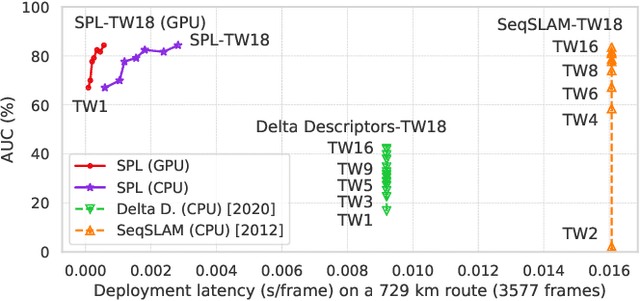
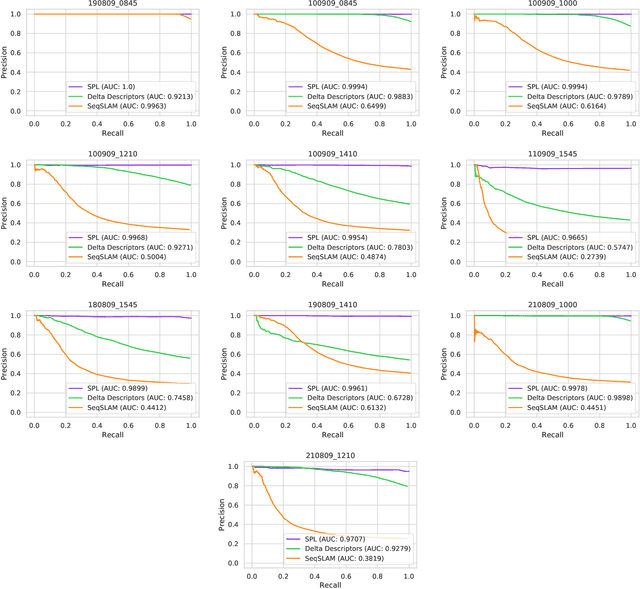
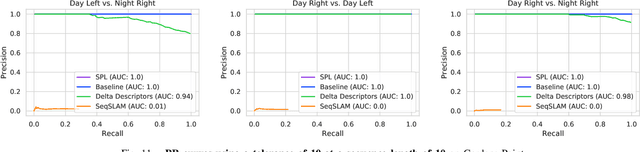
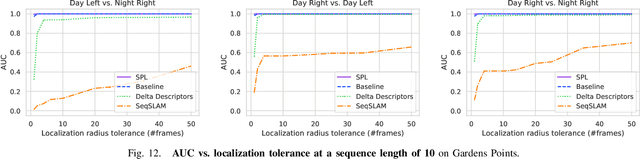
Sequential matching using hand-crafted heuristics has been standard practice in route-based place recognition for enhancing pairwise similarity results for nearly a decade. However, precision-recall performance of these algorithms dramatically degrades when searching on short temporal window (TW) lengths, while demanding high compute and storage costs on large robotic datasets for autonomous navigation research. Here, influenced by biological systems that robustly navigate spacetime scales even without vision, we develop a joint visual and positional representation learning technique, via a sequential process, and design a learning-based CNN+LSTM architecture, trainable via backpropagation through time, for viewpoint- and appearance-invariant place recognition. Our approach, Sequential Place Learning (SPL), is based on a CNN function that visually encodes an environment from a single traversal, thus reducing storage capacity, while an LSTM temporally fuses each visual embedding with corresponding positional data -- obtained from any source of motion estimation -- for direct sequential inference. Contrary to classical two-stage pipelines, e.g., match-then-temporally-filter, our network directly eliminates false-positive rates while jointly learning sequence matching from a single monocular image sequence, even using short TWs. Hence, we demonstrate that our model outperforms 15 classical methods while setting new state-of-the-art performance standards on 4 challenging benchmark datasets, where one of them can be considered solved with recall rates of 100% at 100% precision, correctly matching all places under extreme sunlight-darkness changes. In addition, we show that SPL can be up to 70x faster to deploy than classical methods on a 729 km route comprising 35,768 consecutive frames. Extensive experiments demonstrate the... Baseline code available at https://github.com/mchancan/deepseqslam
DeepSeqSLAM: A Trainable CNN+RNN for Joint Global Description and Sequence-based Place Recognition
Nov 17, 2020
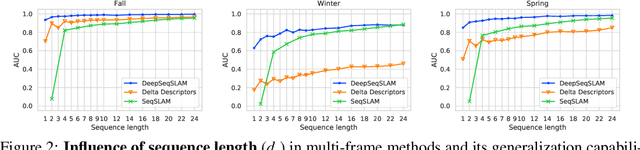


Sequence-based place recognition methods for all-weather navigation are well-known for producing state-of-the-art results under challenging day-night or summer-winter transitions. These systems, however, rely on complex handcrafted heuristics for sequential matching - which are applied on top of a pre-computed pairwise similarity matrix between reference and query image sequences of a single route - to further reduce false-positive rates compared to single-frame retrieval methods. As a result, performing multi-frame place recognition can be extremely slow for deployment on autonomous vehicles or evaluation on large datasets, and fail when using relatively short parameter values such as a sequence length of 2 frames. In this paper, we propose DeepSeqSLAM: a trainable CNN+RNN architecture for jointly learning visual and positional representations from a single monocular image sequence of a route. We demonstrate our approach on two large benchmark datasets, Nordland and Oxford RobotCar - recorded over 728 km and 10 km routes, respectively, each during 1 year with multiple seasons, weather, and lighting conditions. On Nordland, we compare our method to two state-of-the-art sequence-based methods across the entire route under summer-winter changes using a sequence length of 2 and show that our approach can get over 72% AUC compared to 27% AUC for Delta Descriptors and 2% AUC for SeqSLAM; while drastically reducing the deployment time from around 1 hour to 1 minute against both. The framework code and video are available at https://mchancan.github.io/deepseqslam
* 9 pages, 6 figures, 2 tables
Robot Perception enables Complex Navigation Behavior via Self-Supervised Learning
Jun 16, 2020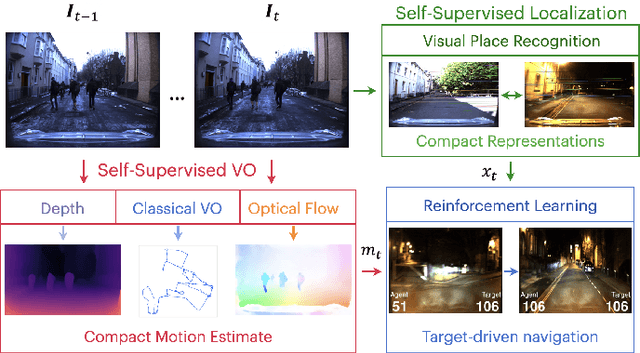


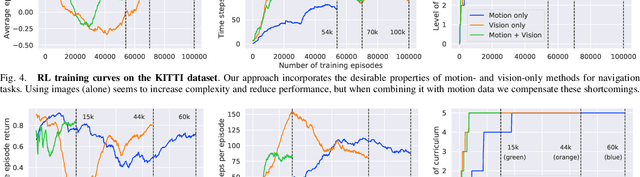
Learning visuomotor control policies in robotic systems is a fundamental problem when aiming for long-term behavioral autonomy. Recent supervised-learning-based vision and motion perception systems, however, are often separately built with limited capabilities, while being restricted to few behavioral skills such as passive visual odometry (VO) or mobile robot visual localization. Here we propose an approach to unify those successful robot perception systems for active target-driven navigation tasks via reinforcement learning (RL). Our method temporally incorporates compact motion and visual perception data - directly obtained using self-supervision from a single image sequence - to enable complex goal-oriented navigation skills. We demonstrate our approach on two real-world driving dataset, KITTI and Oxford RobotCar, using the new interactive CityLearn framework. The results show that our method can accurately generalize to extreme environmental changes such as day to night cycles with up to an 80% success rate, compared to 30% for a vision-only navigation systems.
MVP: Unified Motion and Visual Self-Supervised Learning for Large-Scale Robotic Navigation
Mar 02, 2020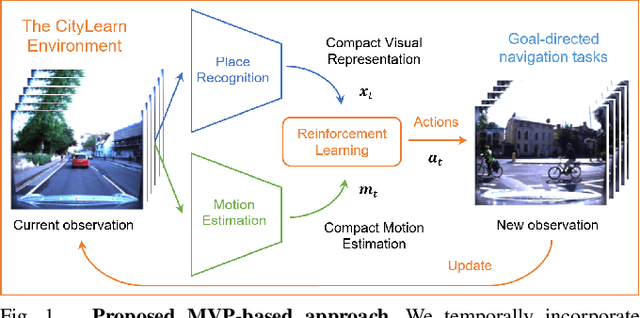
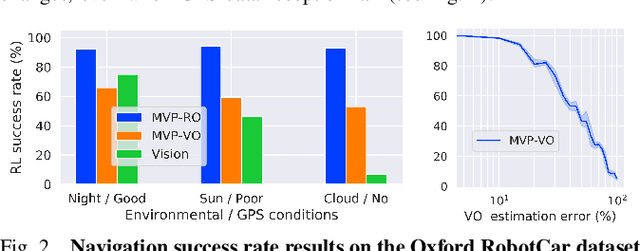

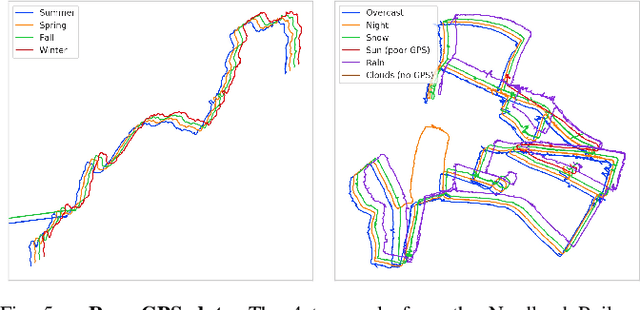
Autonomous navigation emerges from both motion and local visual perception in real-world environments. However, most successful robotic motion estimation methods (e.g. VO, SLAM, SfM) and vision systems (e.g. CNN, visual place recognition-VPR) are often separately used for mapping and localization tasks. Conversely, recent reinforcement learning (RL) based methods for visual navigation rely on the quality of GPS data reception, which may not be reliable when directly using it as ground truth across multiple, month-spaced traversals in large environments. In this paper, we propose a novel motion and visual perception approach, dubbed MVP, that unifies these two sensor modalities for large-scale, target-driven navigation tasks. Our MVP-based method can learn faster, and is more accurate and robust to both extreme environmental changes and poor GPS data than corresponding vision-only navigation methods. MVP temporally incorporates compact image representations, obtained using VPR, with optimized motion estimation data, including but not limited to those from VO or optimized radar odometry (RO), to efficiently learn self-supervised navigation policies via RL. We evaluate our method on two large real-world datasets, Oxford Robotcar and Nordland Railway, over a range of weather (e.g. overcast, night, snow, sun, rain, clouds) and seasonal (e.g. winter, spring, fall, summer) conditions using the new CityLearn framework; an interactive environment for efficiently training navigation agents. Our experimental results, on traversals of the Oxford RobotCar dataset with no GPS data, show that MVP can achieve 53% and 93% navigation success rate using VO and RO, respectively, compared to 7% for a vision-only method. We additionally report a trade-off between the RL success rate and the motion estimation precision.
A Compact Neural Architecture for Visual Place Recognition
Oct 15, 2019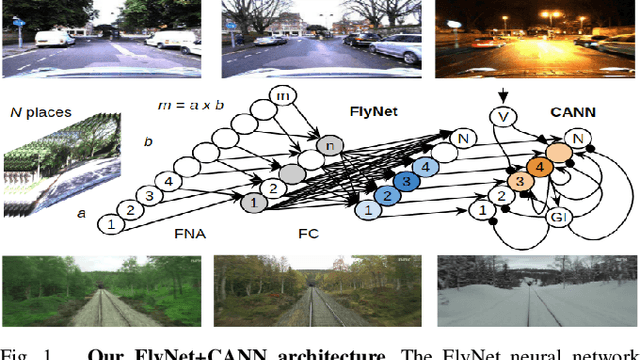
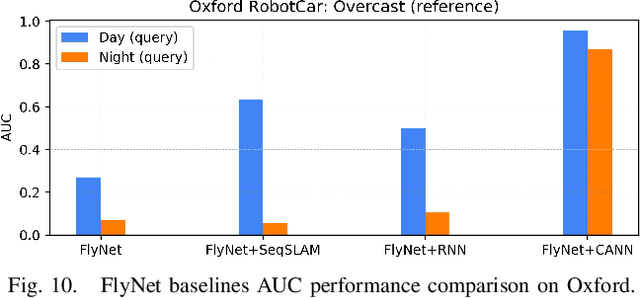
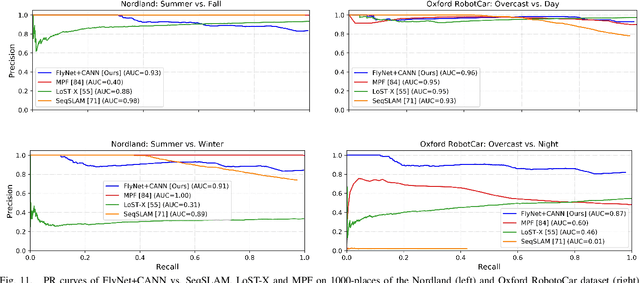
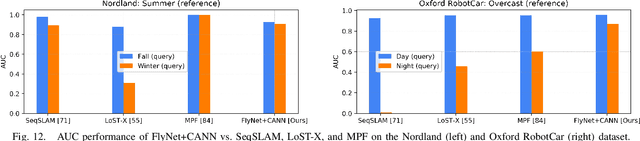
State-of-the-art algorithms for visual place recognition can be broadly split into two categories: computationally expensive deep-learning/image retrieval based techniques with minimal biological plausibility, and computationally cheap, biologically inspired models that yield poor performance in real-world environments. In this paper we present a new compact and high-performing system that bridges this divide for the first time. Our approach comprises two key components: FlyNet, a compact, sparse two-layer neural network inspired by fruit fly brain architectures, and a one-dimensional continuous attractor neural network (CANN). Our FlyNet+CANN network combines the compact pattern recognition capabilities of the FlyNet model with the powerful temporal filtering capabilities of an equally compact CANN, replicating entirely in a neural network implementation the functionality that yields high performance in algorithmic localization approaches like SeqSLAM. We evaluate our approach and compare it to three state-of-the-art methods on two benchmark real-world datasets with small viewpoint changes and extreme appearance variations including different times of day (afternoon to night) where it achieves an AUC performance of 87%, compared to 60% for Multi-Process Fusion, 46% for LoST-X and 1% for SeqSLAM, while being 6.5, 310, and 1.5 times faster respectively.
From Visual Place Recognition to Navigation: Learning Sample-Efficient Control Policies across Diverse Real World Environments
Oct 10, 2019

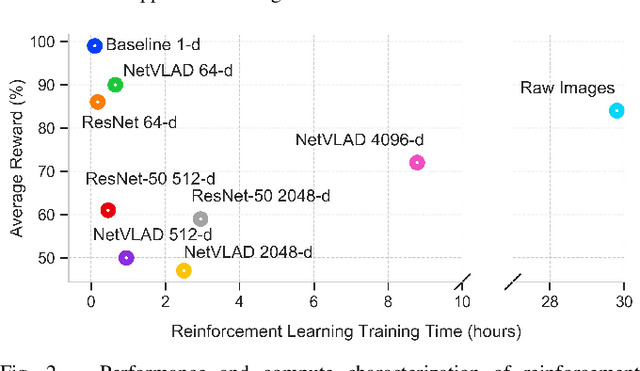

Visual navigation tasks in real world environments often require both self-motion and place recognition feedback. While deep reinforcement learning has shown success in solving these perception and decision-making problems in an end-to-end manner, these algorithms require large amounts of experience to learn navigation policies from high-dimensional inputs, which is generally impractical for real robots due to sample complexity. In this paper, we address these problems with two main contributions. We first leverage place recognition and deep learning techniques combined with goal destination feedback to generate compact, bimodal images representations that can then be used to effectively learn control policies at kilometer scale from a small amount of experience. Second, we present an interactive and realistic framework, called CityLearn, that enables for the first time the training of navigation algorithms across city-sized, real-world environments with extreme environmental changes. CityLearn features over 10 benchmark real-world datasets often used in place recognition research with more than 100 recorded traversals and across 60 cities around the world. We evaluate our approach in two CityLearn environments where our navigation policy is trained using a single traversal. Results show our method can be over 2 orders of magnitude faster than when using raw images and can also generalize across extreme visual changes including day to night and summer to winter transitions.