 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiDAR Snowfall Simulation for Robust 3D Object Detection
Mar 28, 2022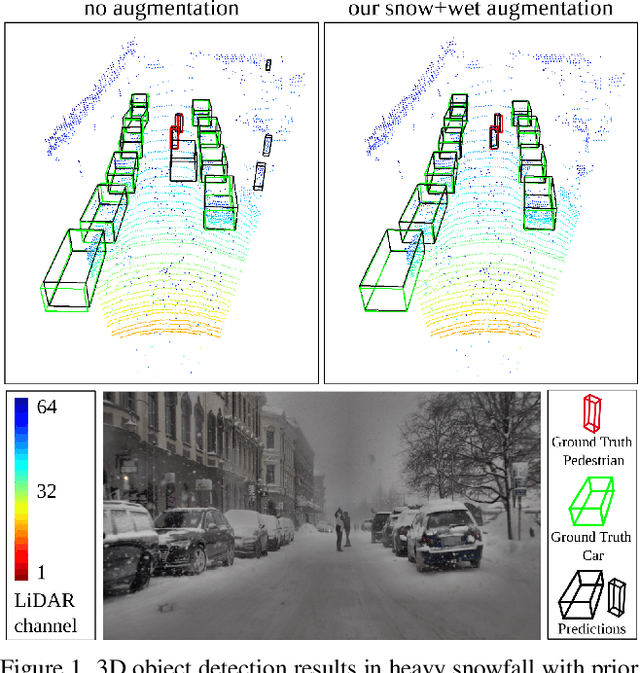
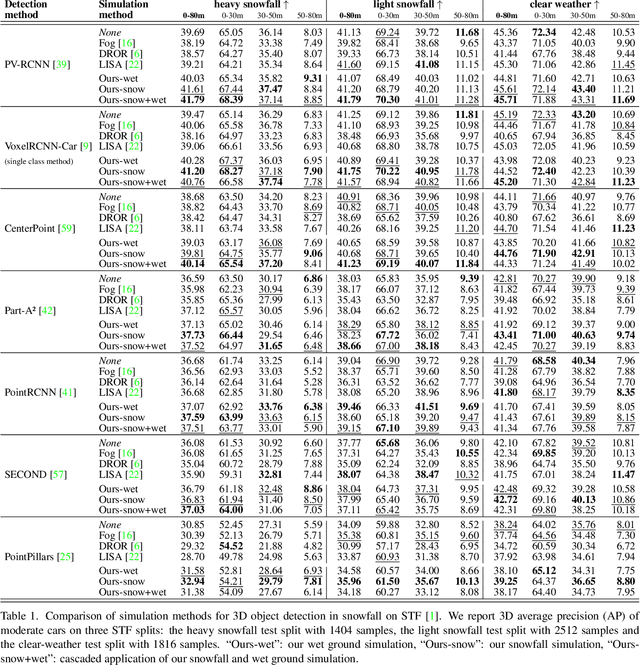
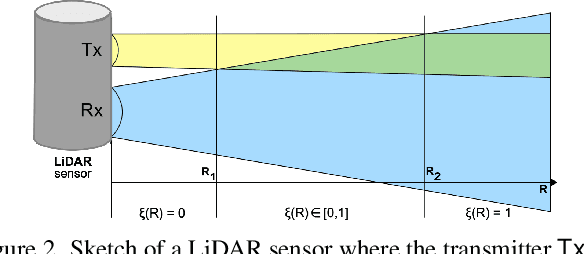
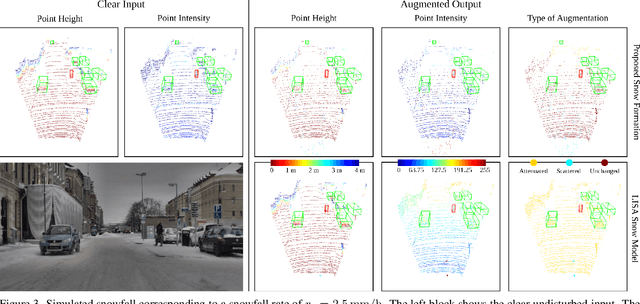
3D object detection is a central task for applications such as autonomous driving, in which the system needs to localize and classify surrounding traffic agents, even in the presence of adverse weather. In this paper, we address the problem of LiDAR-based 3D object detection under snowfall. Due to the difficulty of collecting and annotating training data in this setting, we propose a physically based method to simulate the effect of snowfall on real clear-weather LiDAR point clouds. Our method samples snow particles in 2D space for each LiDAR line and uses the induced geometry to modify the measurement for each LiDAR beam accordingly. Moreover, as snowfall often causes wetness on the ground, we also simulate ground wetness on LiDAR point clouds. We use our simulation to generate partially synthetic snowy LiDAR data and leverage these data for training 3D object detection models that are robust to snowfall. We conduct an extensive evaluation using several state-of-the-art 3D object detection methods and show that our simulation consistently yields significant performance gains on the real snowy STF dataset compared to clear-weather baselines and competing simulation approaches, while not sacrificing performance in clear weather. Our code is available at www.github.com/SysCV/LiDAR_snow_sim.
Fog Simulation on Real LiDAR Point Clouds for 3D Object Detection in Adverse Weather
Aug 16, 2021
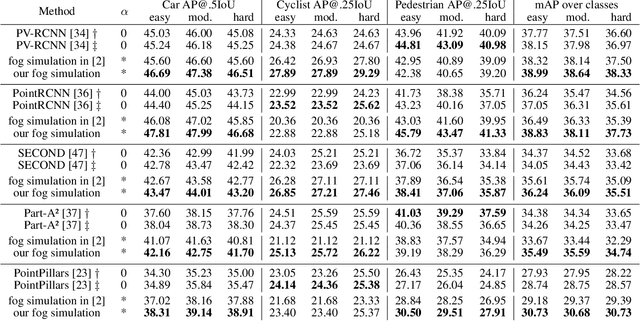


This work addresses the challenging task of LiDAR-based 3D object detection in foggy weather. Collecting and annotating data in such a scenario is very time, labor and cost intensive. In this paper, we tackle this problem by simulating physically accurate fog into clear-weather scenes, so that the abundant existing real datasets captured in clear weather can be repurposed for our task. Our contributions are twofold: 1) We develop a physically valid fog simulation method that is applicable to any LiDAR dataset. This unleashes the acquisition of large-scale foggy training data at no extra cost. These partially synthetic data can be used to improve the robustness of several perception methods, such as 3D object detection and tracking or simultaneous localization and mapping, on real foggy data. 2) Through extensive experiments with several state-of-the-art detection approaches, we show that our fog simulation can be leveraged to significantly improve the performance for 3D object detection in the presence of fog. Thus, we are the first to provide strong 3D object detection baselines on the Seeing Through Fog dataset. Our code is available at www.trace.ethz.ch/lidar_fog_simulation.
Quantifying Data Augmentation for LiDAR based 3D Object Detection
Apr 03, 2020


In this work, we shed light on different data augmentation techniques commonly used in Light Detection and Ranging (LiDAR) based 3D Object Detection. We, therefore, utilize a state of the art voxel-based 3D Object Detection pipeline called PointPillars and carry out our experiments on the well established KITTI dataset. We investigate a variety of global and local augmentation techniques, where global augmentation techniques are applied to the entire point cloud of a scene and local augmentation techniques are only applied to points belonging to individual objects in the scene. Our findings show that both types of data augmentation can lead to performance increases, but it also turns out, that some augmentation techniques, such as individual object translation, for example, can be counterproductive and can hurt overall performance. We show that when we apply our findings to the data augmentation policy of PointPillars we can easily increase its performance by up to 2%. In order to provide reproducibility, our code will be publicly available at www.trace.ethz.ch/3D_Object_Detection.
Semantic Understanding of Foggy Scenes with Purely Synthetic Data
Oct 09, 2019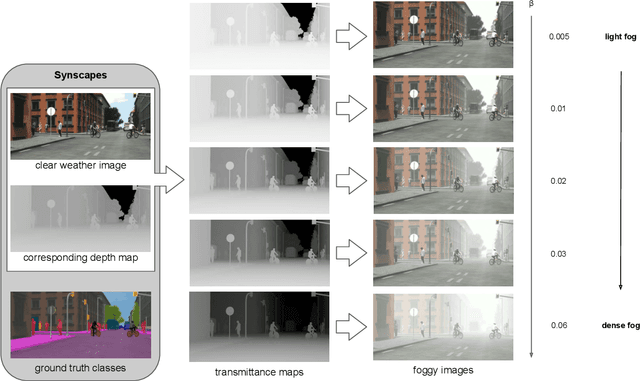


This work addresses the problem of semantic scene understanding under foggy road conditions. Although marked progress has been made in semantic scene understanding over the recent years, it is mainly concentrated on clear weather outdoor scenes. Extending semantic segmentation methods to adverse weather conditions like fog is crucially important for outdoor applications such as self-driving cars. In this paper, we propose a novel method, which uses purely synthetic data to improve the performance on unseen real-world foggy scenes captured in the streets of Zurich and its surroundings. Our results highlight the potential and power of photo-realistic synthetic images for training and especially fine-tuning deep neural nets. Our contributions are threefold, 1) we created a purely synthetic, high-quality foggy dataset of 25,000 unique outdoor scenes, that we call Foggy Synscapes and plan to release publicly 2) we show that with this data we outperform previous approaches on real-world foggy test data 3) we show that a combination of our data and previously used data can even further improve the performance on real-world foggy data.
Texture Underfitting for Domain Adaptation
Aug 29, 2019
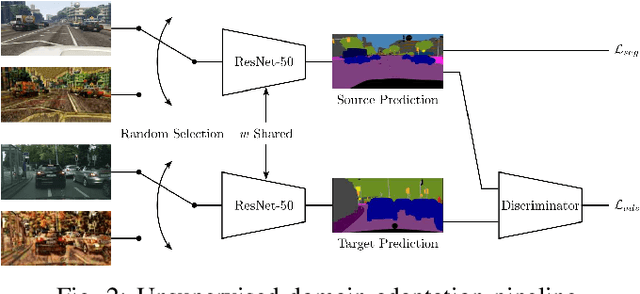
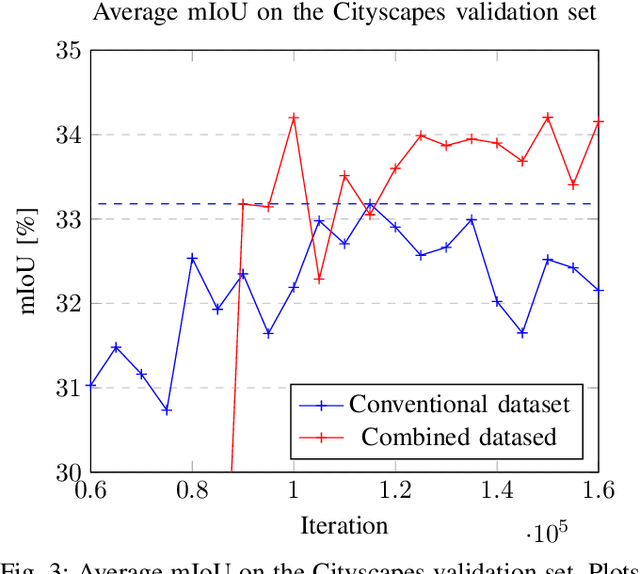
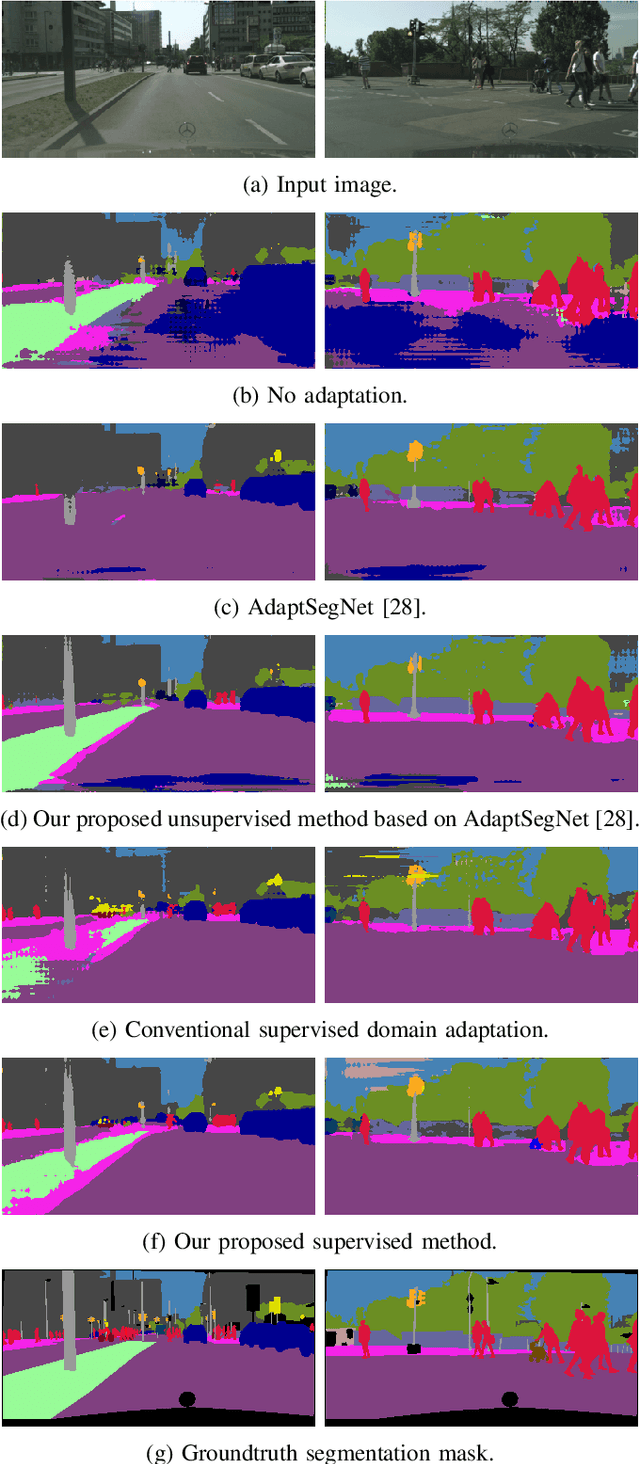
Comprehensive semantic segmentation is one of the key components for robust scene understanding and a requirement to enable autonomous driving. Driven by large scale datasets, convolutional neural networks show impressive results on this task. However, a segmentation algorithm generalizing to various scenes and conditions would require an enormously diverse dataset, making the labour intensive data acquisition and labeling process prohibitively expensive. Under the assumption of structural similarities between segmentation maps, domain adaptation promises to resolve this challenge by transferring knowledge from existing, potentially simulated datasets to new environments where no supervision exists. While the performance of this approach is contingent on the concept that neural networks learn a high level understanding of scene structure, recent work suggests that neural networks are biased towards overfitting to texture instead of learning structural and shape information. Considering the ideas underlying semantic segmentation, we employ random image stylization to augment the training dataset and propose a training procedure that facilitates texture underfitting to improve the performance of domain adaptation. In experiments with supervised as well as unsupervised methods for the task of synthetic-to-real domain adaptation, we show that our approach outperforms conventional training methods.
Simulating Structure-from-Motion
Oct 03, 2017



The implementation of a Structure-from-Motion (SfM) pipeline from a synthetically generated scene as well as the investigation of the faithfulness of diverse reconstructions is the subject of this project. A series of different SfM reconstructions are implemented and their camera pose estimations are being contrasted with their respective ground truth locations. Finally, injection of ground truth location data into the rendered images in order to reduce the estimation error of the camera poses is studied as well.