 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty quantification for White Matter Hyperintensity segmentation detects silent failures and improves automated Fazekas quantification
Nov 26, 2024White Matter Hyperintensities (WMH) are key neuroradiological markers of small vessel disease present in brain MRI. Assessment of WMH is important in research and clinics. However, WMH are challenging to segment due to their high variability in shape, location, size, poorly defined borders, and similar intensity profile to other pathologies (e.g stroke lesions) and artefacts (e.g head motion). In this work, we apply the most effective techniques for uncertainty quantification (UQ) in segmentation to the WMH segmentation task across multiple test-time data distributions. We find a combination of Stochastic Segmentation Networks with Deep Ensembles yields the highest Dice and lowest Absolute Volume Difference % (AVD) score on in-domain and out-of-distribution data. We demonstrate the downstream utility of UQ, proposing a novel method for classification of the clinical Fazekas score using spatial features extracted for WMH segmentation and UQ maps. We show that incorporating WMH uncertainty information improves Fazekas classification performance and calibration, with median class balanced accuracy for classification models with (UQ and spatial WMH features)/(spatial WMH features)/(WMH volume only) of 0.71/0.66/0.60 in the Deep WMH and 0.82/0.77/0.73 in the Periventricular WMH regions respectively. We demonstrate that stochastic UQ techniques with high sample diversity can improve the detection of poor quality segmentations. Finally, we qualitatively analyse the semantic information captured by UQ techniques and demonstrate that uncertainty can highlight areas where there is ambiguity between WMH and stroke lesions, while identifying clusters of small WMH in deep white matter unsegmented by the model.
Machine learning of neuroimaging to diagnose cognitive impairment and dementia: a systematic review and comparative analysis
Apr 11, 2018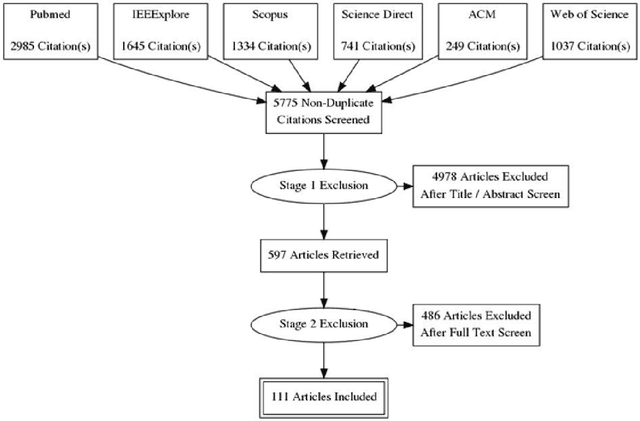
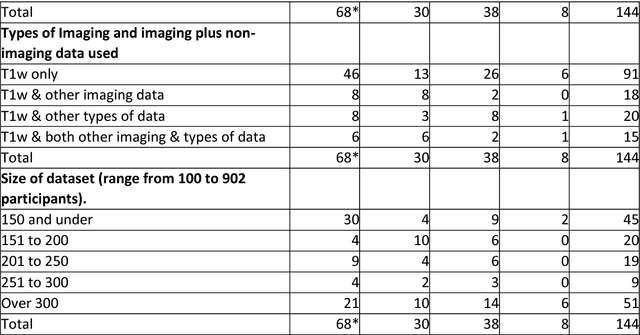
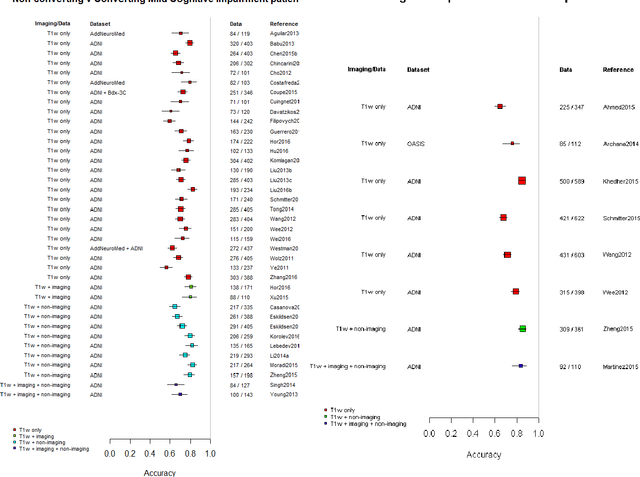
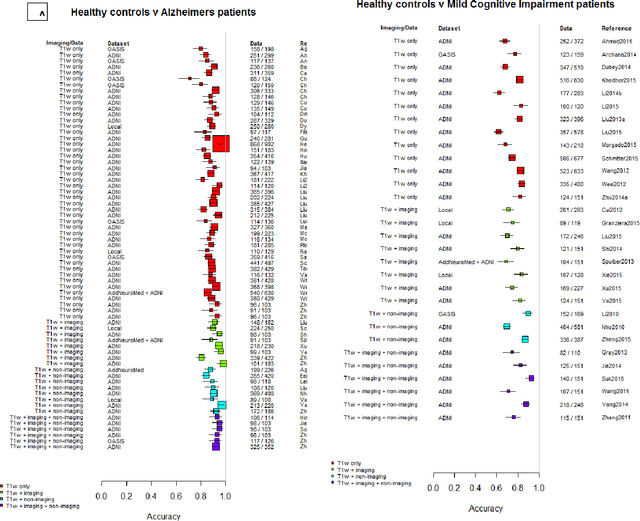
INTRODUCTION: Advanced machine learning methods might help to identify dementia risk from neuroimaging, but their accuracy to date is unclear. METHODS: We systematically reviewed the literature, 2006 to late 2016, for machine learning studies differentiating healthy ageing through to dementia of various types, assessing study quality, and comparing accuracy at different disease boundaries. RESULTS: Of 111 relevant studies, most assessed Alzheimer's disease (AD) vs healthy controls, used ADNI data, support vector machines and only T1-weighted sequences. Accuracy was highest for differentiating AD from healthy controls, and poor for differentiating healthy controls vs MCI vs AD, or MCI converters vs non-converters. Accuracy increased using combined data types, but not by data source, sample size or machine learning method. DISCUSSION: Machine learning does not differentiate clinically-relevant disease categories yet. More diverse datasets, combinations of different types of data, and close clinical integration of machine learning would help to advance the field.