 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA sensitivity analysis to quantify the impact of neuroimaging preprocessing strategies on subsequent statistical analyses
Apr 24, 2024Even though novel imaging techniques have been successful in studying brain structure and function, the measured biological signals are often contaminated by multiple sources of noise, arising due to e.g. head movements of the individual being scanned, limited spatial/temporal resolution, or other issues specific to each imaging technology. Data preprocessing (e.g. denoising) is therefore critical. Preprocessing pipelines have become increasingly complex over the years, but also more flexible, and this flexibility can have a significant impact on the final results and conclusions of a given study. This large parameter space is often referred to as multiverse analyses. Here, we provide conceptual and practical tools for statistical analyses that can aggregate multiple pipeline results along with a new sensitivity analysis testing for hypotheses across pipelines such as "no effect across all pipelines" or "at least one pipeline with no effect". The proposed framework is generic and can be applied to any multiverse scenario, but we illustrate its use based on positron emission tomography data.
Machine learning of neuroimaging to diagnose cognitive impairment and dementia: a systematic review and comparative analysis
Apr 11, 2018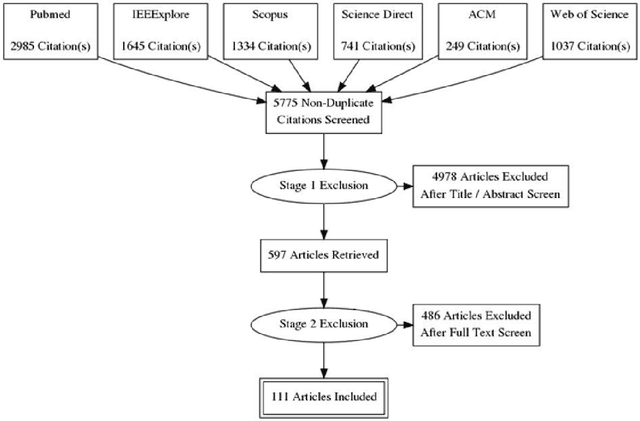
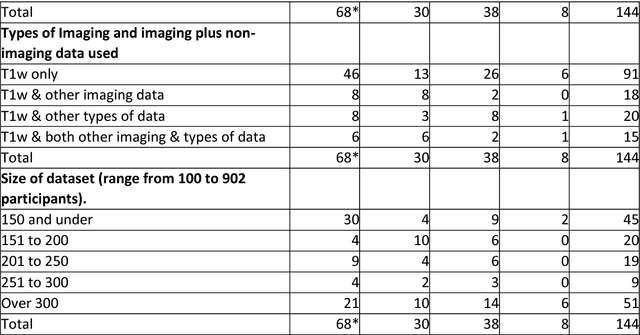
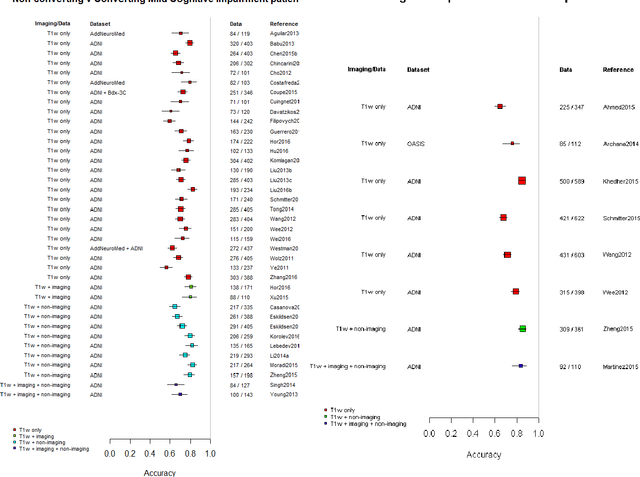
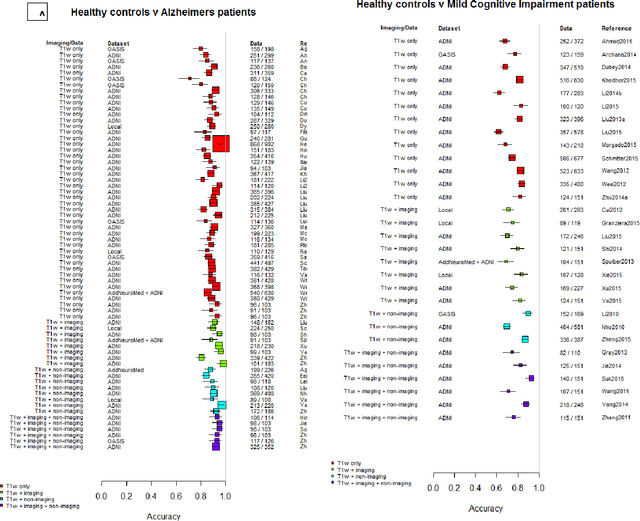
INTRODUCTION: Advanced machine learning methods might help to identify dementia risk from neuroimaging, but their accuracy to date is unclear. METHODS: We systematically reviewed the literature, 2006 to late 2016, for machine learning studies differentiating healthy ageing through to dementia of various types, assessing study quality, and comparing accuracy at different disease boundaries. RESULTS: Of 111 relevant studies, most assessed Alzheimer's disease (AD) vs healthy controls, used ADNI data, support vector machines and only T1-weighted sequences. Accuracy was highest for differentiating AD from healthy controls, and poor for differentiating healthy controls vs MCI vs AD, or MCI converters vs non-converters. Accuracy increased using combined data types, but not by data source, sample size or machine learning method. DISCUSSION: Machine learning does not differentiate clinically-relevant disease categories yet. More diverse datasets, combinations of different types of data, and close clinical integration of machine learning would help to advance the field.