 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoherent 3D Scene Diffusion From a Single RGB Image
Dec 13, 2024



We present a novel diffusion-based approach for coherent 3D scene reconstruction from a single RGB image. Our method utilizes an image-conditioned 3D scene diffusion model to simultaneously denoise the 3D poses and geometries of all objects within the scene. Motivated by the ill-posed nature of the task and to obtain consistent scene reconstruction results, we learn a generative scene prior by conditioning on all scene objects simultaneously to capture the scene context and by allowing the model to learn inter-object relationships throughout the diffusion process. We further propose an efficient surface alignment loss to facilitate training even in the absence of full ground-truth annotation, which is common in publicly available datasets. This loss leverages an expressive shape representation, which enables direct point sampling from intermediate shape predictions. By framing the task of single RGB image 3D scene reconstruction as a conditional diffusion process, our approach surpasses current state-of-the-art methods, achieving a 12.04% improvement in AP3D on SUN RGB-D and a 13.43% increase in F-Score on Pix3D.
Panoptic 3D Scene Reconstruction From a Single RGB Image
Nov 03, 2021
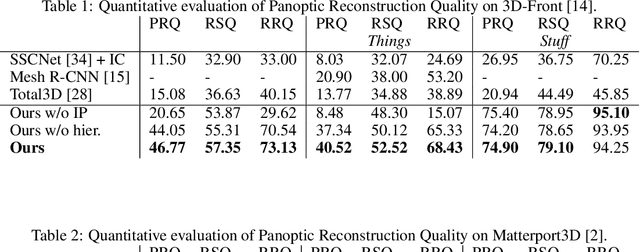
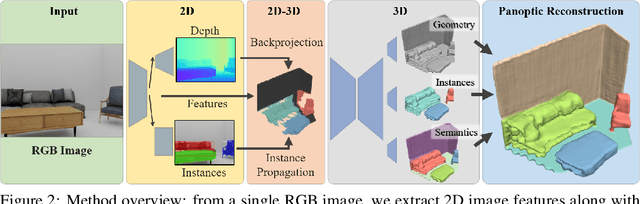
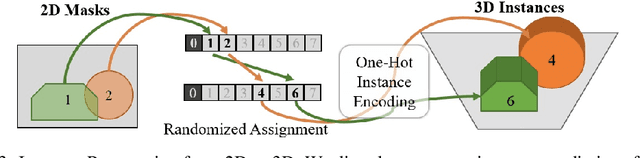
Understanding 3D scenes from a single image is fundamental to a wide variety of tasks, such as for robotics, motion planning, or augmented reality. Existing works in 3D perception from a single RGB image tend to focus on geometric reconstruction only, or geometric reconstruction with semantic segmentation or instance segmentation. Inspired by 2D panoptic segmentation, we propose to unify the tasks of geometric reconstruction, 3D semantic segmentation, and 3D instance segmentation into the task of panoptic 3D scene reconstruction - from a single RGB image, predicting the complete geometric reconstruction of the scene in the camera frustum of the image, along with semantic and instance segmentations. We thus propose a new approach for holistic 3D scene understanding from a single RGB image which learns to lift and propagate 2D features from an input image to a 3D volumetric scene representation. We demonstrate that this holistic view of joint scene reconstruction, semantic, and instance segmentation is beneficial over treating the tasks independently, thus outperforming alternative approaches.
Joint Embedding of 3D Scan and CAD Objects
Aug 19, 2019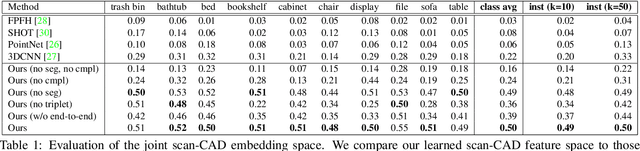
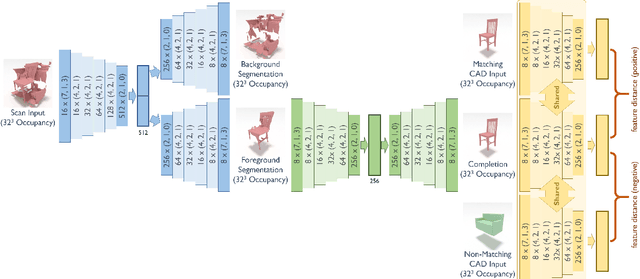
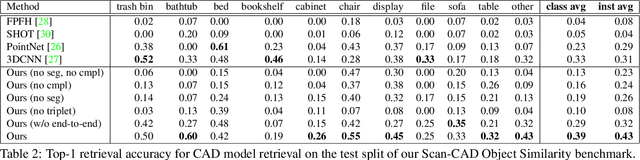
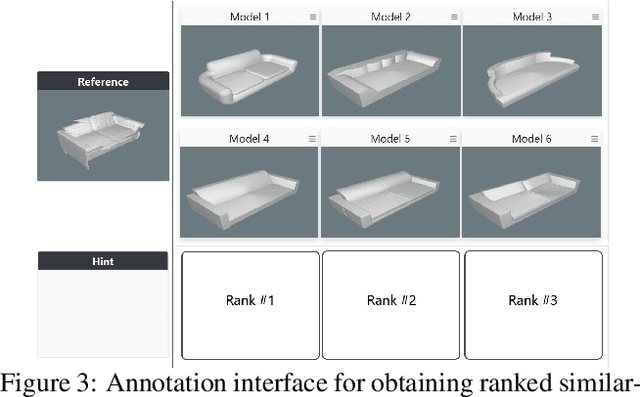
3D scan geometry and CAD models often contain complementary information towards understanding environments, which could be leveraged through establishing a mapping between the two domains. However, this is a challenging task due to strong, lower-level differences between scan and CAD geometry. We propose a novel approach to learn a joint embedding space between scan and CAD geometry, where semantically similar objects from both domains lie close together. To achieve this, we introduce a new 3D CNN-based approach to learn a joint embedding space representing object similarities across these domains. To learn a shared space where scan objects and CAD models can interlace, we propose a stacked hourglass approach to separate foreground and background from a scan object, and transform it to a complete, CAD-like representation to produce a shared embedding space. This embedding space can then be used for CAD model retrieval; to further enable this task, we introduce a new dataset of ranked scan-CAD similarity annotations, enabling new, fine-grained evaluation of CAD model retrieval to cluttered, noisy, partial scans. Our learned joint embedding outperforms current state of the art for CAD model retrieval by 12% in instance retrieval accuracy.
Scan2CAD: Learning CAD Model Alignment in RGB-D Scans
Nov 27, 2018
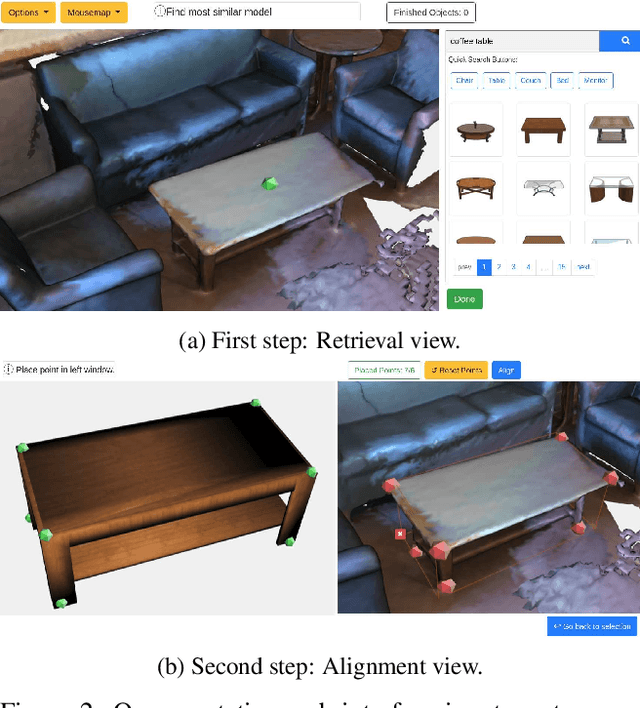
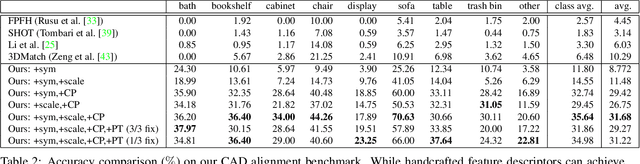
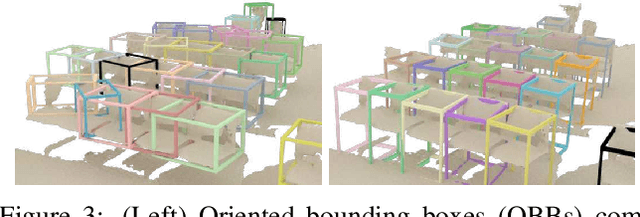
We present Scan2CAD, a novel data-driven method that learns to align clean 3D CAD models from a shape database to the noisy and incomplete geometry of a commodity RGB-D scan. For a 3D reconstruction of an indoor scene, our method takes as input a set of CAD models, and predicts a 9DoF pose that aligns each model to the underlying scan geometry. To tackle this problem, we create a new scan-to-CAD alignment dataset based on 1506 ScanNet scans with 97607 annotated keypoint pairs between 14225 CAD models from ShapeNet and their counterpart objects in the scans. Our method selects a set of representative keypoints in a 3D scan for which we find correspondences to the CAD geometry. To this end, we design a novel 3D CNN architecture that learns a joint embedding between real and synthetic objects, and from this predicts a correspondence heatmap. Based on these correspondence heatmaps, we formulate a variational energy minimization that aligns a given set of CAD models to the reconstruction. We evaluate our approach on our newly introduced Scan2CAD benchmark where we outperform both handcrafted feature descriptor as well as state-of-the-art CNN based methods by 21.39%.