 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHelping Domain Experts Build Speech Translation Systems
Oct 07, 2015

We present a new platform, "Regulus Lite", which supports rapid development and web deployment of several types of phrasal speech translation systems using a minimal formalism. A distinguishing feature is that most development work can be performed directly by domain experts. We motivate the need for platforms of this type and discuss three specific cases: medical speech translation, speech-to-sign-language translation and voice questionnaires. We briefly describe initial experiences in developing practical systems.
Compiling Language Models from a Linguistically Motivated Unification Grammar
Jun 09, 2000
Systems now exist which are able to compile unification grammars into language models that can be included in a speech recognizer, but it is so far unclear whether non-trivial linguistically principled grammars can be used for this purpose. We describe a series of experiments which investigate the question empirically, by incrementally constructing a grammar and discovering what problems emerge when successively larger versions are compiled into finite state graph representations and used as language models for a medium-vocabulary recognition task.
A Compact Architecture for Dialogue Management Based on Scripts and Meta-Outputs
Jun 09, 2000We describe an architecture for spoken dialogue interfaces to semi-autonomous systems that transforms speech signals through successive representations of linguistic, dialogue, and domain knowledge. Each step produces an output, and a meta-output describing the transformation, with an executable program in a simple scripting language as the final result. The output/meta-output distinction permits perspicuous treatment of diverse tasks such as resolving pronouns, correcting user misconceptions, and optimizing scripts.
A Comparison of the XTAG and CLE Grammars for English
Jun 09, 2000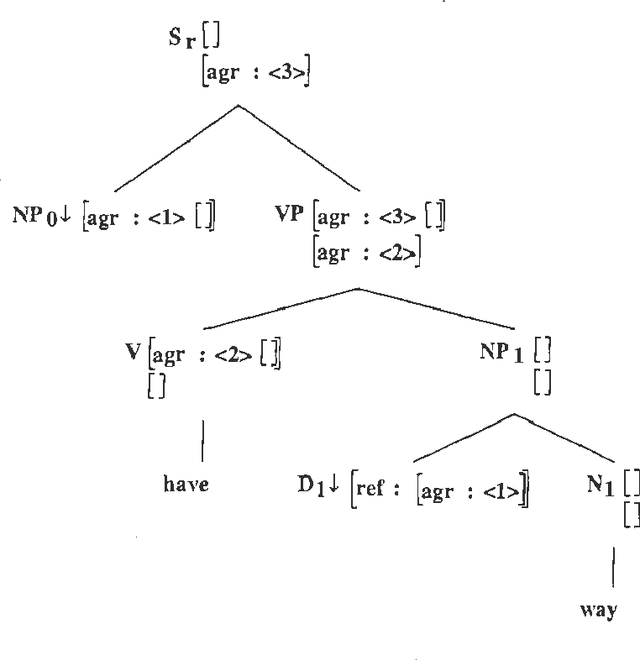
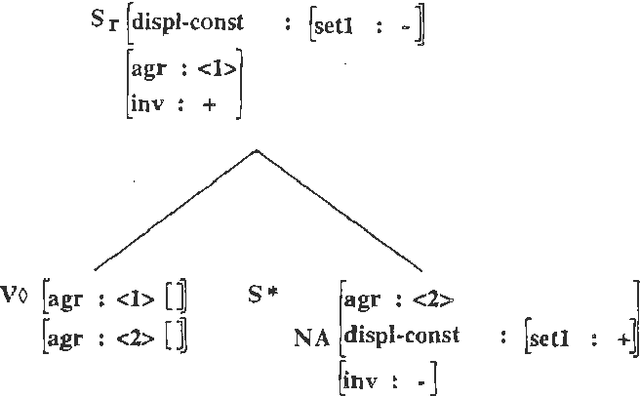
When people develop something intended as a large broad-coverage grammar, they usually have a more specific goal in mind. Sometimes this goal is covering a corpus; sometimes the developers have theoretical ideas they wish to investigate; most often, work is driven by a combination of these two main types of goal. What tends to happen after a while is that the community of people working with the grammar starts thinking of some phenomena as ``central'', and makes serious efforts to deal with them; other phenomena are labelled ``marginal'', and ignored. Before long, the distinction between ``central'' and ``marginal'' becomes so ingrained that it is automatic, and people virtually stop thinking about the ``marginal'' phenomena. In practice, the only way to bring the marginal things back into focus is to look at what other people are doing and compare it with one's own work. In this paper, we will take two large grammars, XTAG and the CLE, and examine each of them from the other's point of view. We will find in both cases not only that important things are missing, but that the perspective offered by the other grammar suggests simple and practical ways of filling in the holes. It turns out that there is a pleasing symmetry to the picture. XTAG has a very good treatment of complement structure, which the CLE to some extent lacks; conversely, the CLE offers a powerful and general account of adjuncts, which the XTAG grammar does not fully duplicate. If we examine the way in which each grammar does the thing it is good at, we find that the relevant methods are quite easy to port to the other framework, and in fact only involve generalization and systematization of existing mechanisms.
Accuracy, Coverage, and Speed: What Do They Mean to Users?
Jun 09, 2000Speech is becoming increasingly popular as an interface modality, especially in hands- and eyes-busy situations where the use of a keyboard or mouse is difficult. However, despite the fact that many have hailed speech as being inherently usable (since everyone already knows how to talk), most users of speech input are left feeling disappointed by the quality of the interaction. Clearly, there is much work to be done on the design of usable spoken interfaces. We believe that there are two major problems in the design of speech interfaces, namely, (a) the people who are currently working on the design of speech interfaces are, for the most part, not interface designers and therefore do not have as much experience with usability issues as we in the CHI community do, and (b) speech, as an interface modality, has vastly different properties than other modalities, and therefore requires different usability measures.
Turning Speech Into Scripts
Jun 09, 2000We describe an architecture for implementing spoken natural language dialogue interfaces to semi-autonomous systems, in which the central idea is to transform the input speech signal through successive levels of representation corresponding roughly to linguistic knowledge, dialogue knowledge, and domain knowledge. The final representation is an executable program in a simple scripting language equivalent to a subset of Cshell. At each stage of the translation process, an input is transformed into an output, producing as a byproduct a "meta-output" which describes the nature of the transformation performed. We show how consistent use of the output/meta-output distinction permits a simple and perspicuous treatment of apparently diverse topics including resolution of pronouns, correction of user misconceptions, and optimization of scripts. The methods described have been concretely realized in a prototype speech interface to a simulation of the Personal Satellite Assistant.
* Working notes from AAAI Spring Symposium
Translation Methodology in the Spoken Language Translator: An Evaluation
May 27, 1997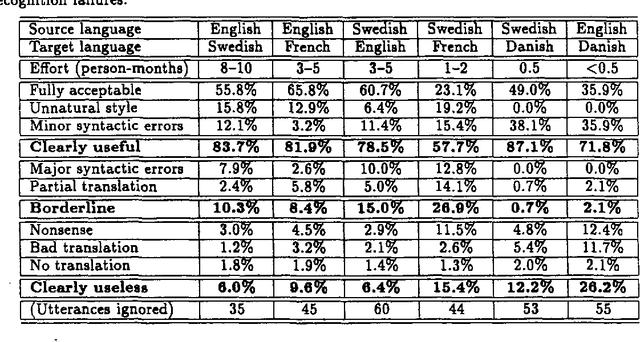

In this paper we describe how the translation methodology adopted for the Spoken Language Translator (SLT) addresses the characteristics of the speech translation task in a context where it is essential to achieve easy customization to new languages and new domains. We then discuss the issues that arise in any attempt to evaluate a speech translator, and present the results of such an evaluation carried out on SLT for several language pairs.
Recycling Lingware in a Multilingual MT System
May 07, 1997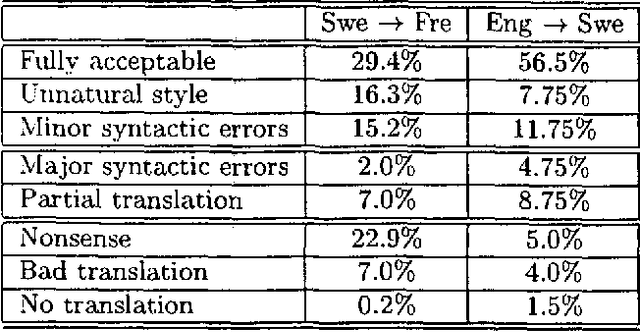
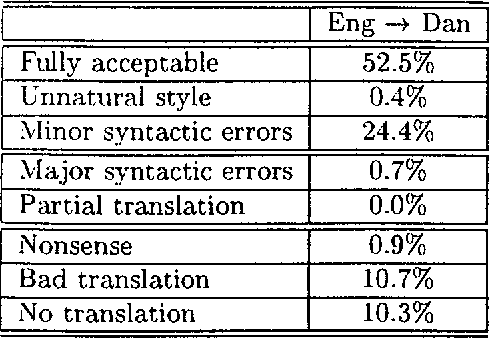
We describe two methods relevant to multi-lingual machine translation systems, which can be used to port linguistic data (grammars, lexicons and transfer rules) between systems used for processing related languages. The methods are fully implemented within the Spoken Language Translator system, and were used to create versions of the system for two new language pairs using only a month of expert effort.
Hybrid language processing in the Spoken Language Translator
Jan 02, 1997The paper presents an overview of the Spoken Language Translator (SLT) system's hybrid language-processing architecture, focussing on the way in which rule-based and statistical methods are combined to achieve robust and efficient performance within a linguistically motivated framework. In general, we argue that rules are desirable in order to encode domain-independent linguistic constraints and achieve high-quality grammatical output, while corpus-derived statistics are needed if systems are to be efficient and robust; further, that hybrid architectures are superior from the point of view of portability to architectures which only make use of one type of information. We address the topics of ``multi-engine'' strategies for robust translation; robust bottom-up parsing using pruning and grammar specialization; rational development of linguistic rule-sets using balanced domain corpora; and efficient supervised training by interactive disambiguation. All work described is fully implemented in the current version of the SLT-2 system.
Adapting the Core Language Engine to French and Spanish
May 10, 1996We describe how substantial domain-independent language-processing systems for French and Spanish were quickly developed by manually adapting an existing English-language system, the SRI Core Language Engine. We explain the adaptation process in detail, and argue that it provides a fairly general recipe for converting a grammar-based system for English into a corresponding one for a Romance language.