Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompiling Language Models from a Linguistically Motivated Unification Grammar
Paper and Code
Jun 09, 2000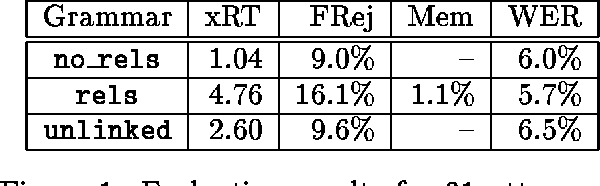
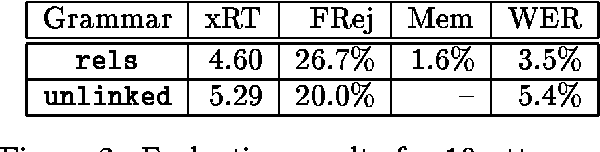
Systems now exist which are able to compile unification grammars into language models that can be included in a speech recognizer, but it is so far unclear whether non-trivial linguistically principled grammars can be used for this purpose. We describe a series of experiments which investigate the question empirically, by incrementally constructing a grammar and discovering what problems emerge when successively larger versions are compiled into finite state graph representations and used as language models for a medium-vocabulary recognition task.
* To be published in COLING 2000
View paper on