 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparison of the XTAG and CLE Grammars for English
Paper and Code
Jun 09, 2000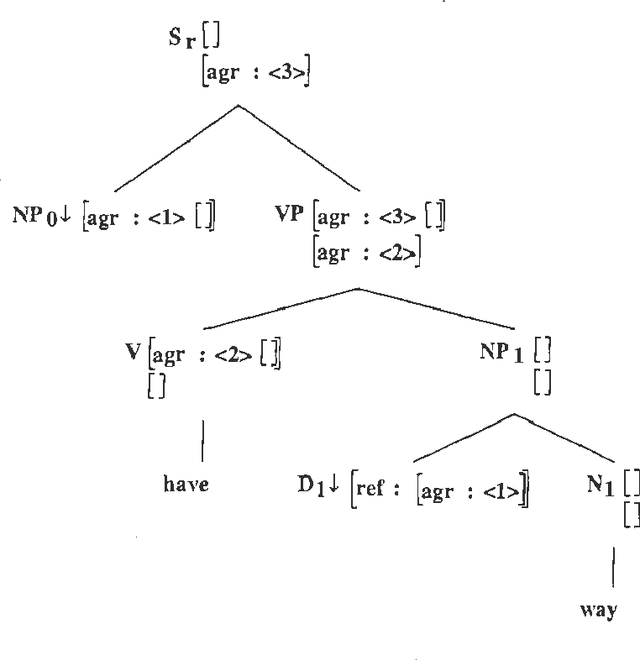
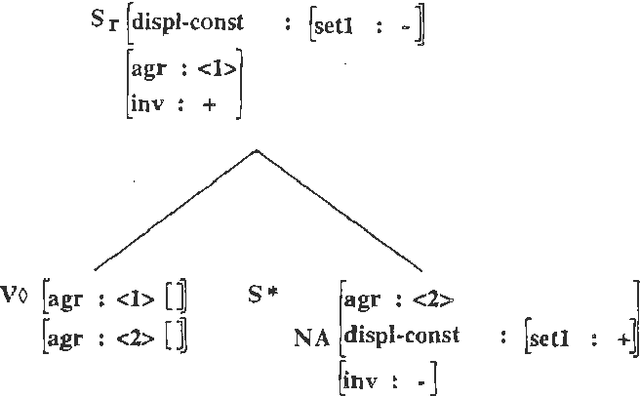
When people develop something intended as a large broad-coverage grammar, they usually have a more specific goal in mind. Sometimes this goal is covering a corpus; sometimes the developers have theoretical ideas they wish to investigate; most often, work is driven by a combination of these two main types of goal. What tends to happen after a while is that the community of people working with the grammar starts thinking of some phenomena as ``central'', and makes serious efforts to deal with them; other phenomena are labelled ``marginal'', and ignored. Before long, the distinction between ``central'' and ``marginal'' becomes so ingrained that it is automatic, and people virtually stop thinking about the ``marginal'' phenomena. In practice, the only way to bring the marginal things back into focus is to look at what other people are doing and compare it with one's own work. In this paper, we will take two large grammars, XTAG and the CLE, and examine each of them from the other's point of view. We will find in both cases not only that important things are missing, but that the perspective offered by the other grammar suggests simple and practical ways of filling in the holes. It turns out that there is a pleasing symmetry to the picture. XTAG has a very good treatment of complement structure, which the CLE to some extent lacks; conversely, the CLE offers a powerful and general account of adjuncts, which the XTAG grammar does not fully duplicate. If we examine the way in which each grammar does the thing it is good at, we find that the relevant methods are quite easy to port to the other framework, and in fact only involve generalization and systematization of existing mechanisms.