 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe TreeBanker: a Tool for Supervised Training of Parsed Corpora
Jul 02, 1997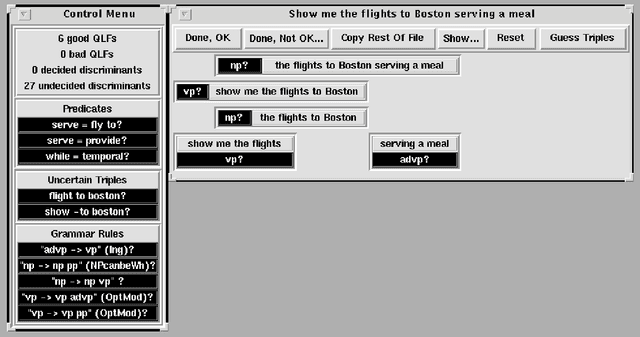
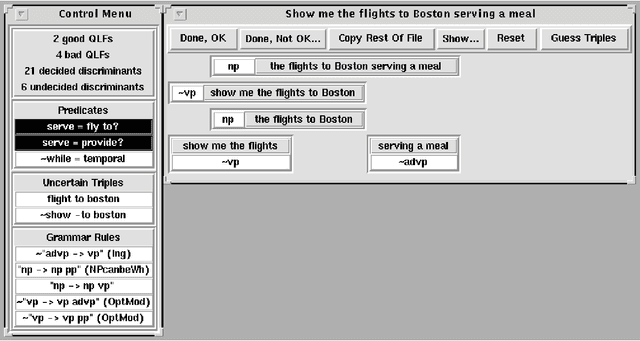
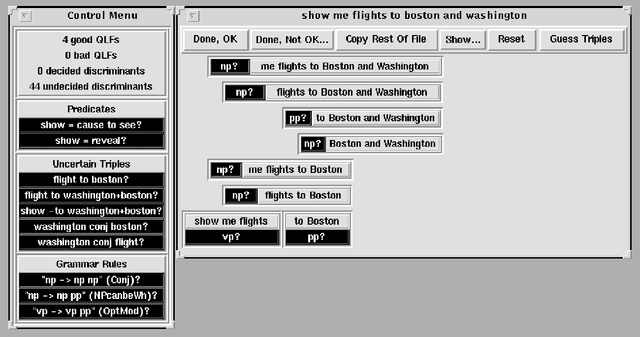
I describe the TreeBanker, a graphical tool for the supervised training involved in domain customization of the disambiguation component of a speech- or language-understanding system. The TreeBanker presents a user, who need not be a system expert, with a range of properties that distinguish competing analyses for an utterance and that are relatively easy to judge. This allows training on a corpus to be completed in far less time, and with far less expertise, than would be needed if analyses were inspected directly: it becomes possible for a corpus of about 20,000 sentences of the complexity of those in the ATIS corpus to be judged in around three weeks of work by a linguistically aware non-expert.
* 7 pages, needs aclap.sty. Replacement just corrects Figure 3
Translation Methodology in the Spoken Language Translator: An Evaluation
May 27, 1997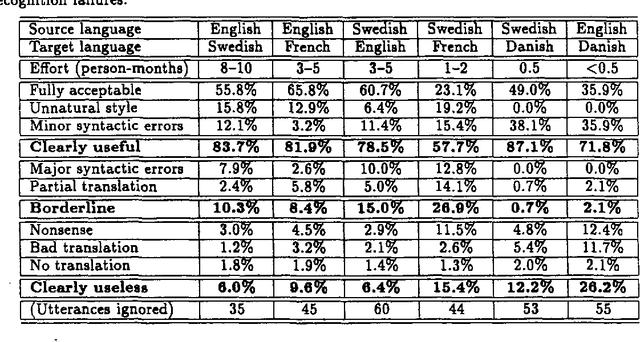

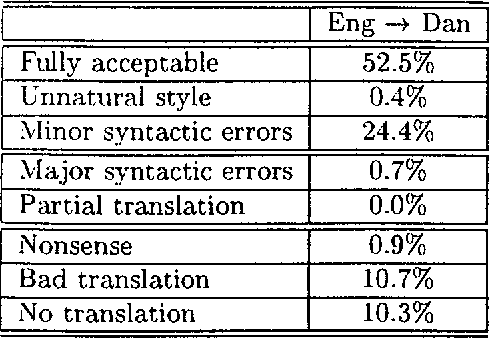
In this paper we describe how the translation methodology adopted for the Spoken Language Translator (SLT) addresses the characteristics of the speech translation task in a context where it is essential to achieve easy customization to new languages and new domains. We then discuss the issues that arise in any attempt to evaluate a speech translator, and present the results of such an evaluation carried out on SLT for several language pairs.
Recycling Lingware in a Multilingual MT System
May 07, 1997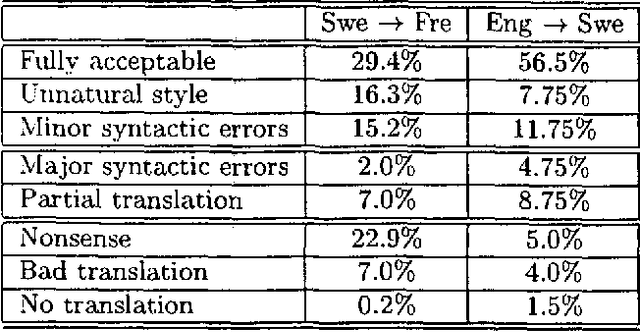
We describe two methods relevant to multi-lingual machine translation systems, which can be used to port linguistic data (grammars, lexicons and transfer rules) between systems used for processing related languages. The methods are fully implemented within the Spoken Language Translator system, and were used to create versions of the system for two new language pairs using only a month of expert effort.
Hybrid language processing in the Spoken Language Translator
Jan 02, 1997The paper presents an overview of the Spoken Language Translator (SLT) system's hybrid language-processing architecture, focussing on the way in which rule-based and statistical methods are combined to achieve robust and efficient performance within a linguistically motivated framework. In general, we argue that rules are desirable in order to encode domain-independent linguistic constraints and achieve high-quality grammatical output, while corpus-derived statistics are needed if systems are to be efficient and robust; further, that hybrid architectures are superior from the point of view of portability to architectures which only make use of one type of information. We address the topics of ``multi-engine'' strategies for robust translation; robust bottom-up parsing using pruning and grammar specialization; rational development of linguistic rule-sets using balanced domain corpora; and efficient supervised training by interactive disambiguation. All work described is fully implemented in the current version of the SLT-2 system.
Adapting the Core Language Engine to French and Spanish
May 10, 1996We describe how substantial domain-independent language-processing systems for French and Spanish were quickly developed by manually adapting an existing English-language system, the SRI Core Language Engine. We explain the adaptation process in detail, and argue that it provides a fairly general recipe for converting a grammar-based system for English into a corresponding one for a Romance language.
Fast Parsing using Pruning and Grammar Specialization
Apr 26, 1996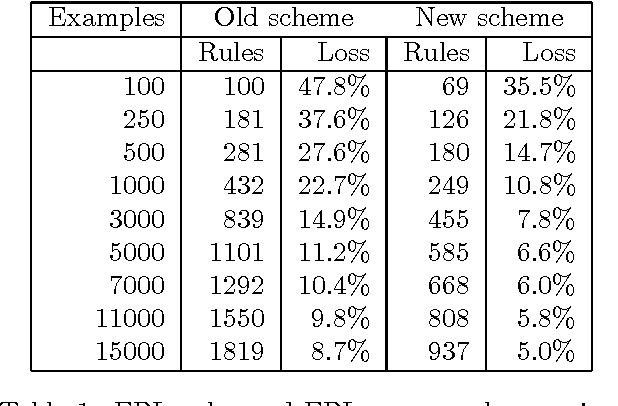
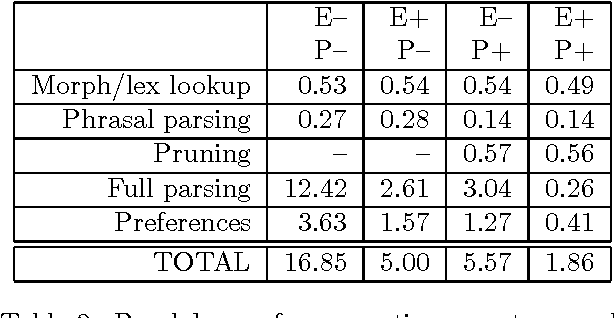
We show how a general grammar may be automatically adapted for fast parsing of utterances from a specific domain by means of constituent pruning and grammar specialization based on explanation-based learning. These methods together give an order of magnitude increase in speed, and the coverage loss entailed by grammar specialization is reduced to approximately half that reported in previous work. Experiments described here suggest that the loss of coverage has been reduced to the point where it no longer causes significant performance degradation in the context of a real application.
Rapid Development of Morphological Descriptions for Full Language Processing Systems
Feb 08, 1995



I describe a compiler and development environment for feature-augmented two-level morphology rules integrated into a full NLP system. The compiler is optimized for a class of languages including many or most European ones, and for rapid development and debugging of descriptions of new languages. The key design decision is to compose morphophonological and morphosyntactic information, but not the lexicon, when compiling the description. This results in typical compilation times of about a minute, and has allowed a reasonably full, feature-based description of French inflectional morphology to be developed in about a month by a linguist new to the system.
The Speech-Language Interface in the Spoken Language Translator
Nov 23, 1994The Spoken Language Translator is a prototype for practically useful systems capable of translating continuous spoken language within restricted domains. The prototype system translates air travel (ATIS) queries from spoken English to spoken Swedish and to French. It is constructed, with as few modifications as possible, from existing pieces of speech and language processing software. The speech recognizer and language understander are connected by a fairly conventional pipelined N-best interface. This paper focuses on the ways in which the language processor makes intelligent use of the sentence hypotheses delivered by the recognizer. These ways include (1) producing modified hypotheses to reflect the possible presence of repairs in the uttered word sequence; (2) fast parsing with a version of the grammar automatically specialized to the more frequent constructions in the training corpus; and (3) allowing syntactic and semantic factors to interact with acoustic ones in the choice of a meaning structure for translation, so that the acoustically preferred hypothesis is not always selected even if it is within linguistic coverage.
CLARE: A Contextual Reasoning and Cooperative Response Framework for the Core Language Engine
Nov 01, 1994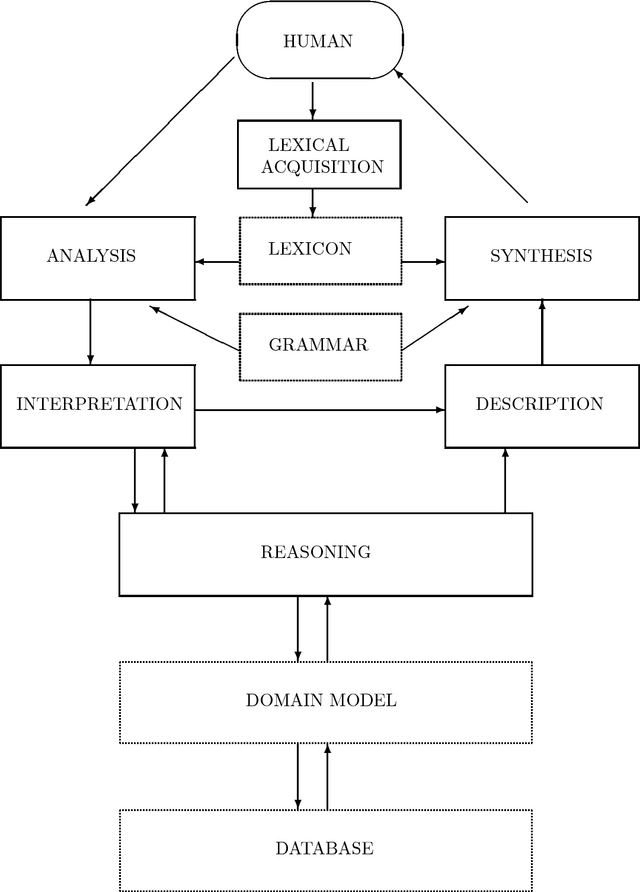

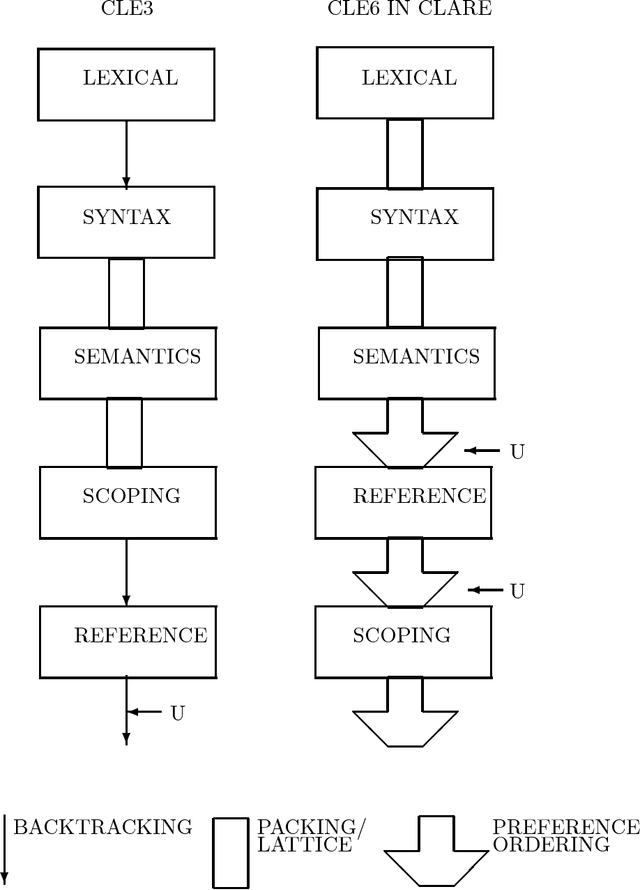
This report describes the research, design and implementation work carried out in building the CLARE system at SRI International, Cambridge, England. CLARE was designed as a natural language processing system with facilities for reasoning and understanding in context and for generating cooperative responses. The project involved both further development of SRI's Core Language Engine (Alshawi, 1992, MIT Press) natural language processor and the design and implementation of new components for reasoning and response generation. The CLARE system has advanced the state of the art in a wide variety of areas, both through the use of novel techniques developed on the project, and by extending the coverage or scale of known techniques. The language components are application-independent and provide interfaces for the development of new types of application.
Improving Language Models by Clustering Training Sentences
Oct 04, 1994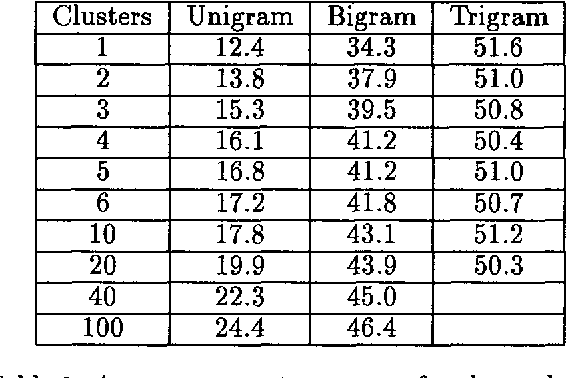
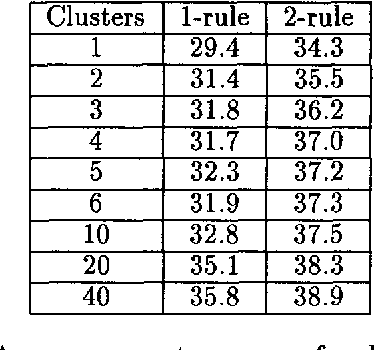
Many of the kinds of language model used in speech understanding suffer from imperfect modeling of intra-sentential contextual influences. I argue that this problem can be addressed by clustering the sentences in a training corpus automatically into subcorpora on the criterion of entropy reduction, and calculating separate language model parameters for each cluster. This kind of clustering offers a way to represent important contextual effects and can therefore significantly improve the performance of a model. It also offers a reasonably automatic means to gather evidence on whether a more complex, context-sensitive model using the same general kind of linguistic information is likely to reward the effort that would be required to develop it: if clustering improves the performance of a model, this proves the existence of further context dependencies, not exploited by the unclustered model. As evidence for these claims, I present results showing that clustering improves some models but not others for the ATIS domain. These results are consistent with other findings for such models, suggesting that the existence or otherwise of an improvement brought about by clustering is indeed a good pointer to whether it is worth developing further the unclustered model.