 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Language Models by Clustering Training Sentences
Paper and Code
Oct 04, 1994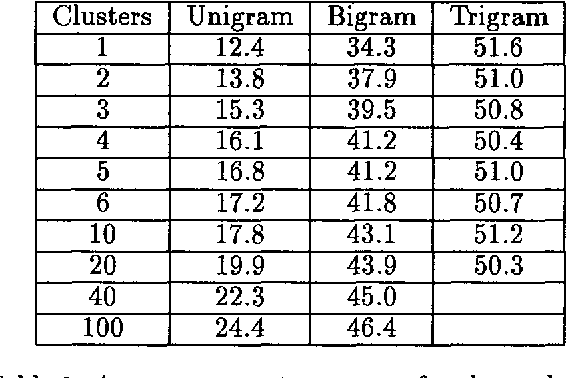
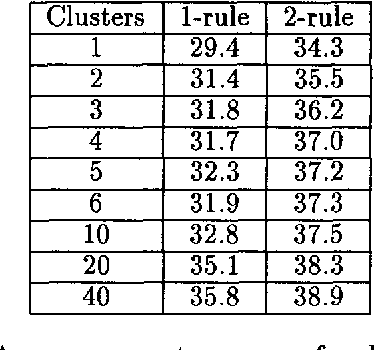
Many of the kinds of language model used in speech understanding suffer from imperfect modeling of intra-sentential contextual influences. I argue that this problem can be addressed by clustering the sentences in a training corpus automatically into subcorpora on the criterion of entropy reduction, and calculating separate language model parameters for each cluster. This kind of clustering offers a way to represent important contextual effects and can therefore significantly improve the performance of a model. It also offers a reasonably automatic means to gather evidence on whether a more complex, context-sensitive model using the same general kind of linguistic information is likely to reward the effort that would be required to develop it: if clustering improves the performance of a model, this proves the existence of further context dependencies, not exploited by the unclustered model. As evidence for these claims, I present results showing that clustering improves some models but not others for the ATIS domain. These results are consistent with other findings for such models, suggesting that the existence or otherwise of an improvement brought about by clustering is indeed a good pointer to whether it is worth developing further the unclustered model.