 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExhaustive search for sparse variable selection in linear regression
Jul 07, 2017
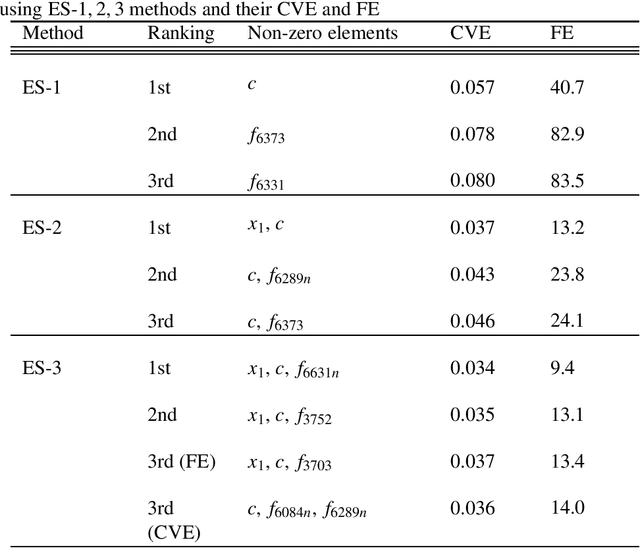
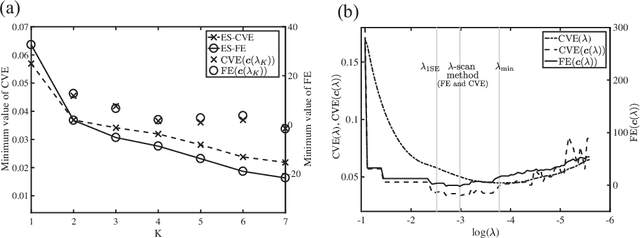

We propose a K-sparse exhaustive search (ES-K) method and a K-sparse approximate exhaustive search method (AES-K) for selecting variables in linear regression. With these methods, K-sparse combinations of variables are tested exhaustively assuming that the optimal combination of explanatory variables is K-sparse. By collecting the results of exhaustively computing ES-K, various approximate methods for selecting sparse variables can be summarized as density of states. With this density of states, we can compare different methods for selecting sparse variables such as relaxation and sampling. For large problems where the combinatorial explosion of explanatory variables is crucial, the AES-K method enables density of states to be effectively reconstructed by using the replica-exchange Monte Carlo method and the multiple histogram method. Applying the ES-K and AES-K methods to type Ia supernova data, we confirmed the conventional understanding in astronomy when an appropriate K is given beforehand. However, we found the difficulty to determine K from the data. Using virtual measurement and analysis, we argue that this is caused by data shortage.
Approximate cross-validation formula for Bayesian linear regression
Oct 25, 2016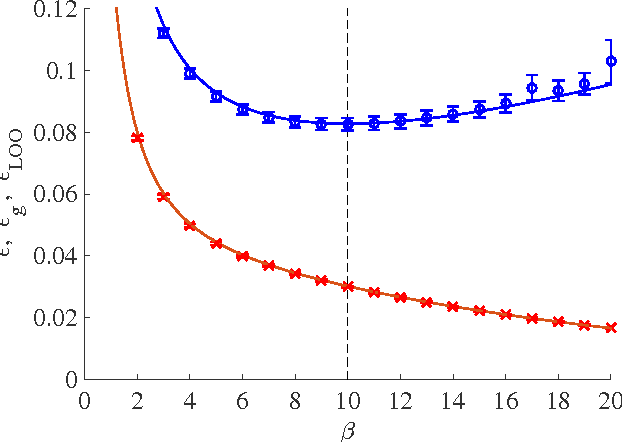


Cross-validation (CV) is a technique for evaluating the ability of statistical models/learning systems based on a given data set. Despite its wide applicability, the rather heavy computational cost can prevent its use as the system size grows. To resolve this difficulty in the case of Bayesian linear regression, we develop a formula for evaluating the leave-one-out CV error approximately without actually performing CV. The usefulness of the developed formula is tested by statistical mechanical analysis for a synthetic model. This is confirmed by application to a real-world supernova data set as well.