 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizing from References using a Multi-Task Reference and Goal-Driven RL Framework
Feb 23, 2026Learning agile humanoid behaviors from human motion offers a powerful route to natural, coordinated control, but existing approaches face a persistent trade-off: reference-tracking policies are often brittle outside the demonstration dataset, while purely task-driven Reinforcement Learning (RL) can achieve adaptability at the cost of motion quality. We introduce a unified multi-task RL framework that bridges this gap by treating reference motion as a prior for behavioral shaping rather than a deployment-time constraint. A single goal-conditioned policy is trained jointly on two tasks that share the same observation and action spaces, but differ in their initialization schemes, command spaces, and reward structures: (i) a reference-guided imitation task in which reference trajectories define dense imitation rewards but are not provided as policy inputs, and (ii) a goal-conditioned generalization task in which goals are sampled independently of any reference and where rewards reflect only task success. By co-optimizing these objectives within a shared formulation, the policy acquires structured, human-like motor skills from dense reference supervision while learning to adapt these skills to novel goals and initial conditions. This is achieved without adversarial objectives, explicit trajectory tracking, phase variables, or reference-dependent inference. We evaluate the method on a challenging box-based parkour playground that demands diverse athletic behaviors (e.g., jumping and climbing), and show that the learned controller transfers beyond the reference distribution while preserving motion naturalness. Finally, we demonstrate long-horizon behavior generation by composing multiple learned skills, illustrating the flexibility of the learned polices in complex scenarios.
ZEST: Zero-shot Embodied Skill Transfer for Athletic Robot Control
Jan 30, 2026Achieving robust, human-like whole-body control on humanoid robots for agile, contact-rich behaviors remains a central challenge, demanding heavy per-skill engineering and a brittle process of tuning controllers. We introduce ZEST (Zero-shot Embodied Skill Transfer), a streamlined motion-imitation framework that trains policies via reinforcement learning from diverse sources -- high-fidelity motion capture, noisy monocular video, and non-physics-constrained animation -- and deploys them to hardware zero-shot. ZEST generalizes across behaviors and platforms while avoiding contact labels, reference or observation windows, state estimators, and extensive reward shaping. Its training pipeline combines adaptive sampling, which focuses training on difficult motion segments, and an automatic curriculum using a model-based assistive wrench, together enabling dynamic, long-horizon maneuvers. We further provide a procedure for selecting joint-level gains from approximate analytical armature values for closed-chain actuators, along with a refined model of actuators. Trained entirely in simulation with moderate domain randomization, ZEST demonstrates remarkable generality. On Boston Dynamics' Atlas humanoid, ZEST learns dynamic, multi-contact skills (e.g., army crawl, breakdancing) from motion capture. It transfers expressive dance and scene-interaction skills, such as box-climbing, directly from videos to Atlas and the Unitree G1. Furthermore, it extends across morphologies to the Spot quadruped, enabling acrobatics, such as a continuous backflip, through animation. Together, these results demonstrate robust zero-shot deployment across heterogeneous data sources and embodiments, establishing ZEST as a scalable interface between biological movements and their robotic counterparts.
Fall Prediction for Bipedal Robots: The Standing Phase
Sep 25, 2023This paper presents a novel approach to fall prediction for bipedal robots, specifically targeting the detection of potential falls while standing caused by abrupt, incipient, and intermittent faults. Leveraging a 1D convolutional neural network (CNN), our method aims to maximize lead time for fall prediction while minimizing false positive rates. The proposed algorithm uniquely integrates the detection of various fault types and estimates the lead time for potential falls. Our contributions include the development of an algorithm capable of detecting abrupt, incipient, and intermittent faults in full-sized robots, its implementation using both simulation and hardware data for a humanoid robot, and a method for estimating lead time. Evaluation metrics, including false positive rate, lead time, and response time, demonstrate the efficacy of our approach. Particularly, our model achieves impressive lead times and response times across different fault scenarios with a false positive rate of 0. The findings of this study hold significant implications for enhancing the safety and reliability of bipedal robotic systems.
Optimizing Lead Time in Fall Detection for a Planar Bipedal Robot
Mar 27, 2023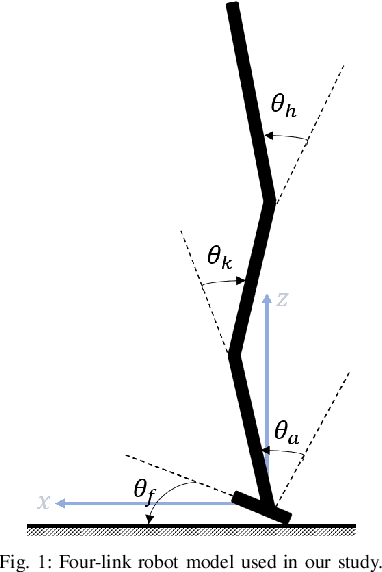

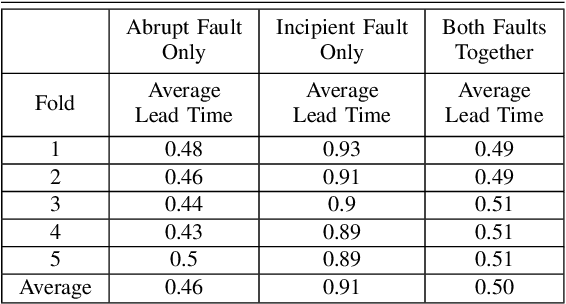

For legged robots to operate in complex terrains, they must be robust to the disturbances and uncertainties they encounter. This paper contributes to enhancing robustness through the design of fall detection/prediction algorithms that will provide sufficient lead time for corrective motions to be taken. Falls can be caused by abrupt (fast-acting), incipient (slow-acting), or intermittent (non-continuous) faults. Early fall detection is a challenging task due to the masking effects of controllers (through their disturbance attenuation actions), the inverse relationship between lead time and false positive rates, and the temporal behavior of the faults/underlying factors. In this paper, we propose a fall detection algorithm that is capable of detecting both incipient and abrupt faults while maximizing lead time and meeting desired thresholds on the false positive and negative rates.
Feedback Control of an Exoskeleton for Paraplegics: Toward Robustly Stable Hands-free Dynamic Walking
May 21, 2018
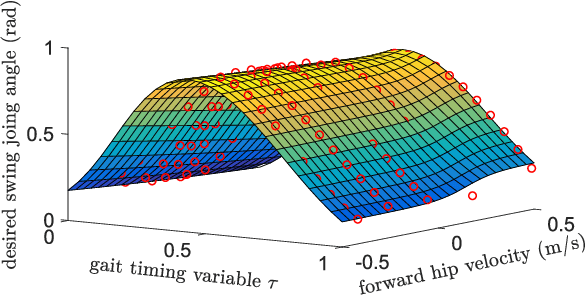
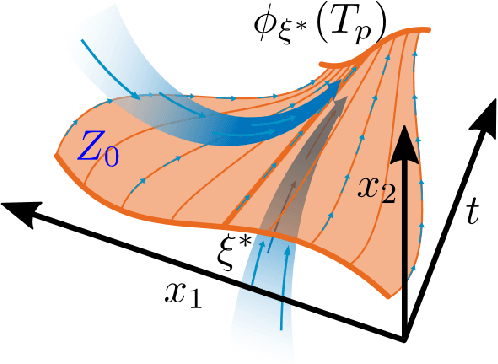
This manuscript presents control of a high-DOF fully actuated lower-limb exoskeleton for paraplegic individuals. The key novelty is the ability for the user to walk without the use of crutches or other external means of stabilization. We harness the power of modern optimization techniques and supervised machine learning to develop a smooth feedback control policy that provides robust velocity regulation and perturbation rejection. Preliminary evaluation of the stability and robustness of the proposed approach is demonstrated through the Gazebo simulation environment. In addition, preliminary experimental results with (complete) paraplegic individuals are included for the previous version of the controller.