 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatching with Text Data: An Experimental Evaluation of Methods for Matching Documents and of Measuring Match Quality
Oct 03, 2018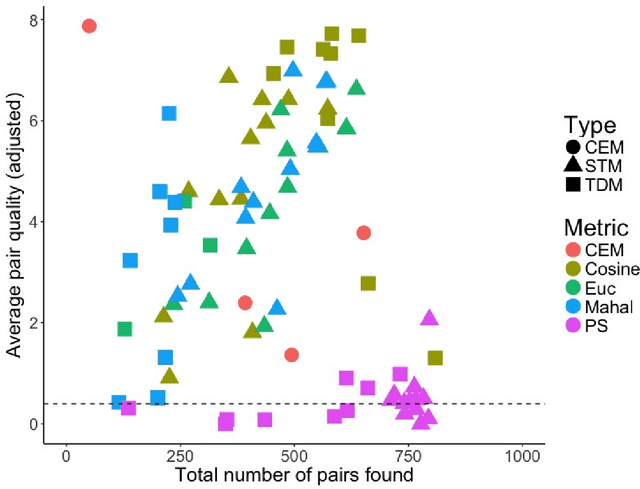
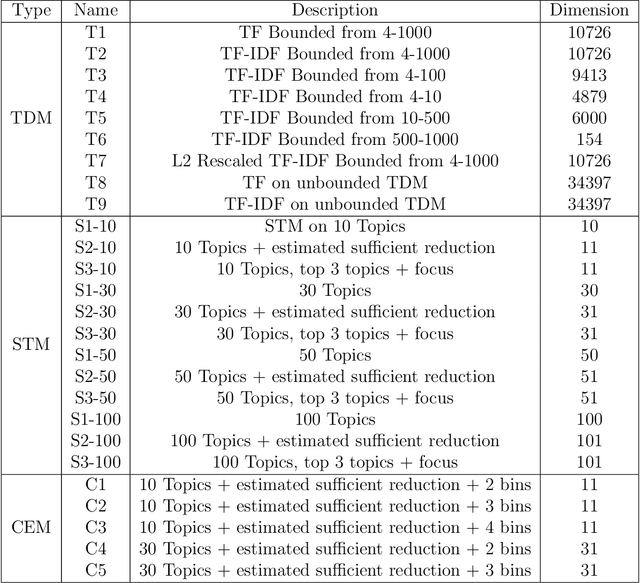
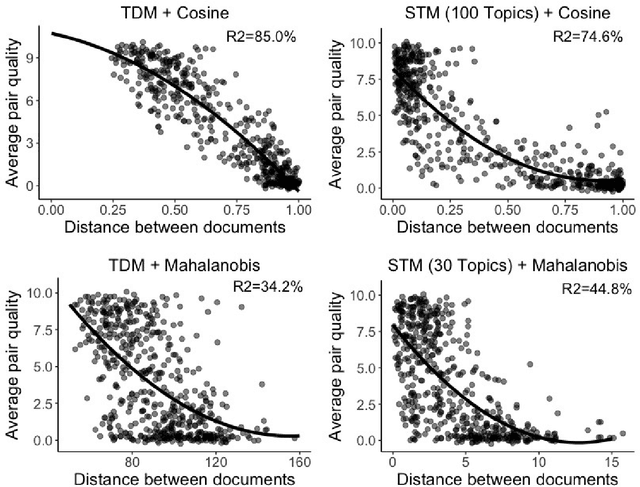
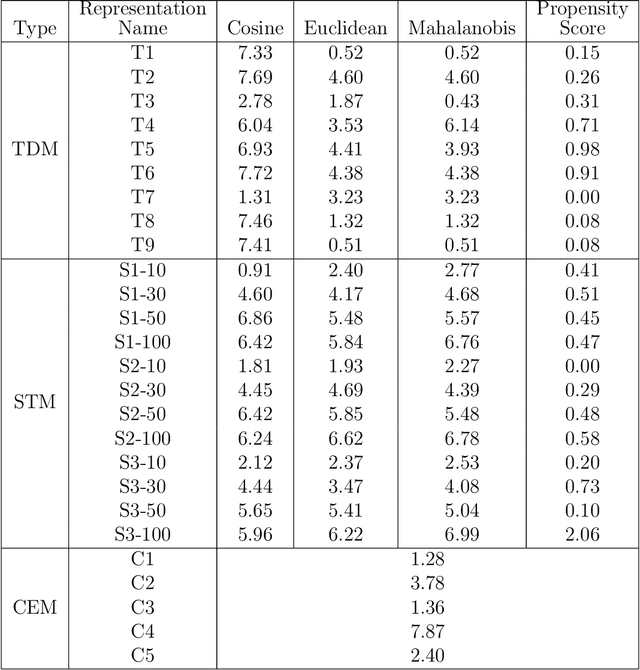
Matching for causal inference is a well-studied problem, but standard methods fail when the units to match are text documents: the high-dimensional and rich nature of the data renders exact matching infeasible, causes propensity scores to produce incomparable matches, and makes assessing match quality difficult. In this paper, we characterize a framework for matching text documents that decomposes existing methods into: (1) the choice of text representation, and (2) the choice of distance metric. We investigate how different choices within this framework affect both the quantity and quality of matches identified through a systematic multifactor evaluation experiment using human subjects. Altogether we evaluate over 100 unique text matching methods along with 5 comparison methods taken from the literature. Our experimental results identify methods that generate matches with higher subjective match quality than current state-of-the-art techniques. We enhance the precision of these results by developing a predictive model to estimate the match quality of pairs of text documents as a function of our various distance scores. This model, which we find successfully mimics human judgment, also allows for approximate and unsupervised evaluation of new procedures. We then employ the identified best method to illustrate the utility of text matching in two applications. First, we engage with a substantive debate in the study of media bias by using text matching to control for topic selection when comparing news articles from thirteen news sources. We then show how conditioning on text data leads to more precise causal inferences in an observational study examining the effects of a medical intervention.
Prior matters: simple and general methods for evaluating and improving topic quality in topic modeling
Oct 14, 2017



Latent Dirichlet Allocation (LDA) models trained without stopword removal often produce topics with high posterior probabilities on uninformative words, obscuring the underlying corpus content. Even when canonical stopwords are manually removed, uninformative words common in that corpus will still dominate the most probable words in a topic. In this work, we first show how the standard topic quality measures of coherence and pointwise mutual information act counter-intuitively in the presence of common but irrelevant words, making it difficult to even quantitatively identify situations in which topics may be dominated by stopwords. We propose an additional topic quality metric that targets the stopword problem, and show that it, unlike the standard measures, correctly correlates with human judgements of quality. We also propose a simple-to-implement strategy for generating topics that are evaluated to be of much higher quality by both human assessment and our new metric. This approach, a collection of informative priors easily introduced into most LDA-style inference methods, automatically promotes terms with domain relevance and demotes domain-specific stop words. We demonstrate this approach's effectiveness in three very different domains: Department of Labor accident reports, online health forum posts, and NIPS abstracts. Overall we find that current practices thought to solve this problem do not do so adequately, and that our proposal offers a substantial improvement for those interested in interpreting their topics as objects in their own right.
Conducting sparse feature selection on arbitrarily long phrases in text corpora with a focus on interpretability
Jul 23, 2016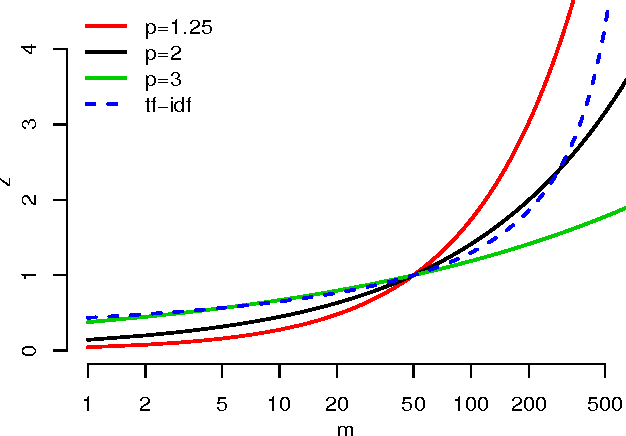

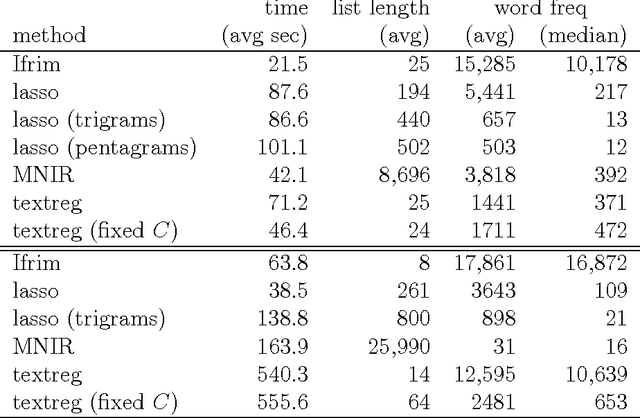
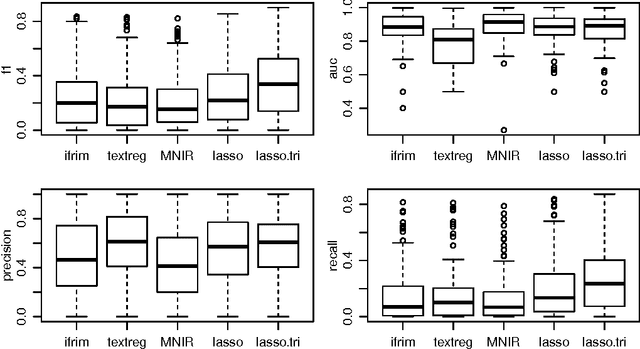
We propose a general framework for topic-specific summarization of large text corpora, and illustrate how it can be used for analysis in two quite different contexts: an OSHA database of fatality and catastrophe reports (to facilitate surveillance for patterns in circumstances leading to injury or death) and legal decisions on workers' compensation claims (to explore relevant case law). Our summarization framework, built on sparse classification methods, is a compromise between simple word frequency based methods currently in wide use, and more heavyweight, model-intensive methods such as Latent Dirichlet Allocation (LDA). For a particular topic of interest (e.g., mental health disability, or chemical reactions), we regress a labeling of documents onto the high-dimensional counts of all the other words and phrases in the documents. The resulting small set of phrases found as predictive are then harvested as the summary. Using a branch-and-bound approach, this method can be extended to allow for phrases of arbitrary length, which allows for potentially rich summarization. We discuss how focus on the purpose of the summaries can inform choices of regularization parameters and model constraints. We evaluate this tool by comparing computational time and summary statistics of the resulting word lists to three other methods in the literature. We also present a new R package, textreg. Overall, we argue that sparse methods have much to offer text analysis, and is a branch of research that should be considered further in this context.
Concise comparative summaries (CCS) of large text corpora with a human experiment
Apr 29, 2014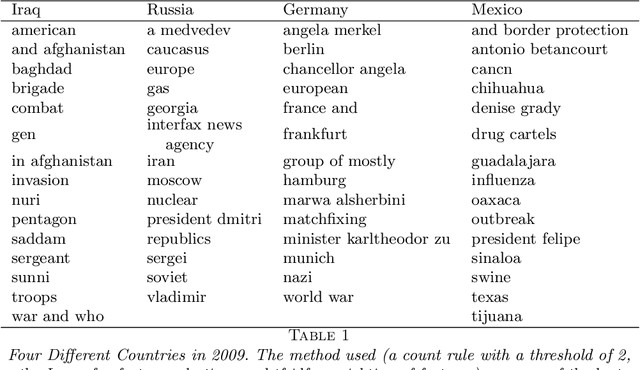
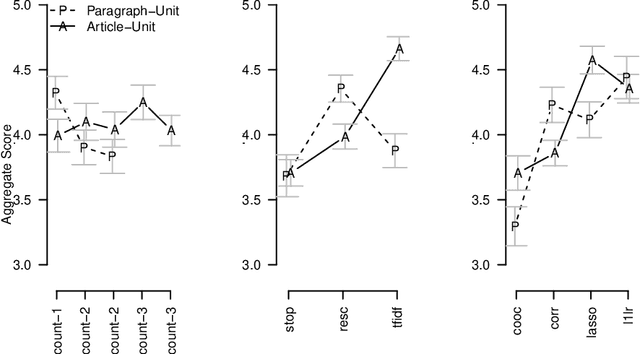
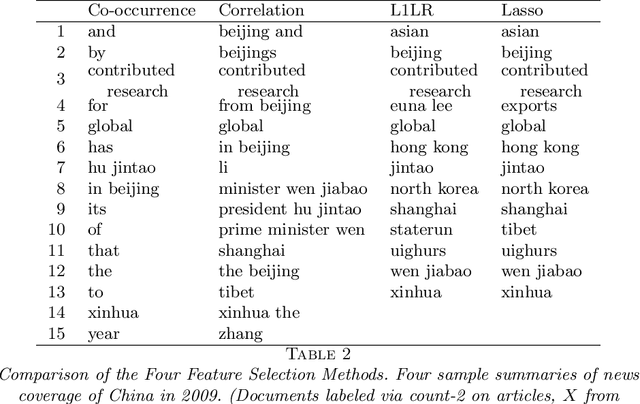
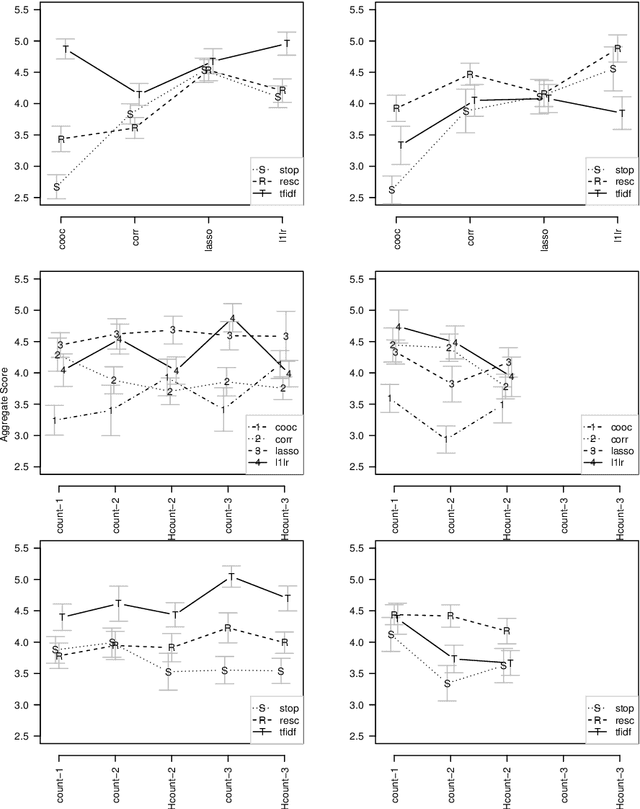
In this paper we propose a general framework for topic-specific summarization of large text corpora and illustrate how it can be used for the analysis of news databases. Our framework, concise comparative summarization (CCS), is built on sparse classification methods. CCS is a lightweight and flexible tool that offers a compromise between simple word frequency based methods currently in wide use and more heavyweight, model-intensive methods such as latent Dirichlet allocation (LDA). We argue that sparse methods have much to offer for text analysis and hope CCS opens the door for a new branch of research in this important field. For a particular topic of interest (e.g., China or energy), CSS automatically labels documents as being either on- or off-topic (usually via keyword search), and then uses sparse classification methods to predict these labels with the high-dimensional counts of all the other words and phrases in the documents. The resulting small set of phrases found as predictive are then harvested as the summary. To validate our tool, we, using news articles from the New York Times international section, designed and conducted a human survey to compare the different summarizers with human understanding. We demonstrate our approach with two case studies, a media analysis of the framing of "Egypt" in the New York Times throughout the Arab Spring and an informal comparison of the New York Times' and Wall Street Journal's coverage of "energy." Overall, we find that the Lasso with $L^2$ normalization can be effectively and usefully used to summarize large corpora, regardless of document size.
* Published in at http://dx.doi.org/10.1214/13-AOAS698 the Annals of Applied Statistics (http://www.imstat.org/aoas/) by the Institute of Mathematical Statistics (http://www.imstat.org)