 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcise comparative summaries (CCS) of large text corpora with a human experiment
Paper and Code
Apr 29, 2014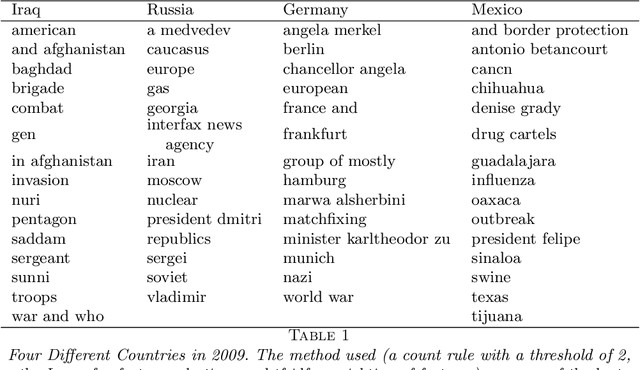
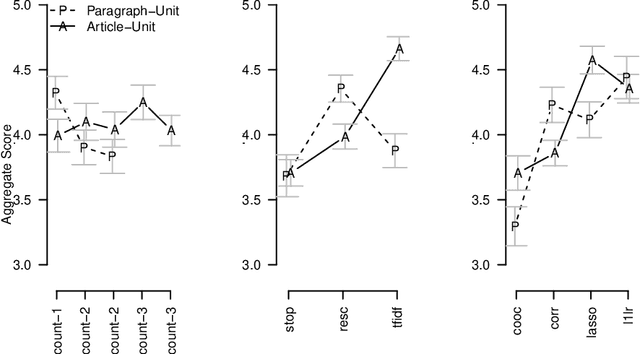
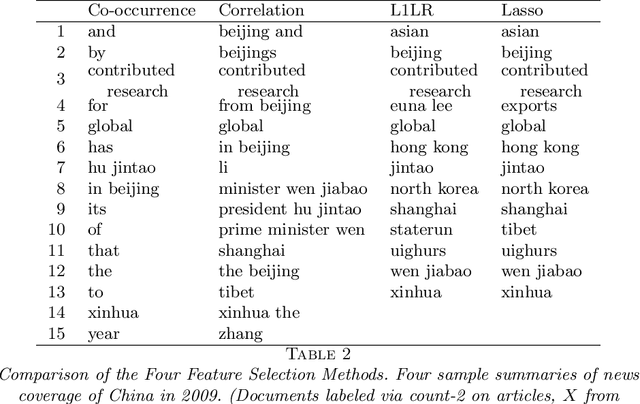
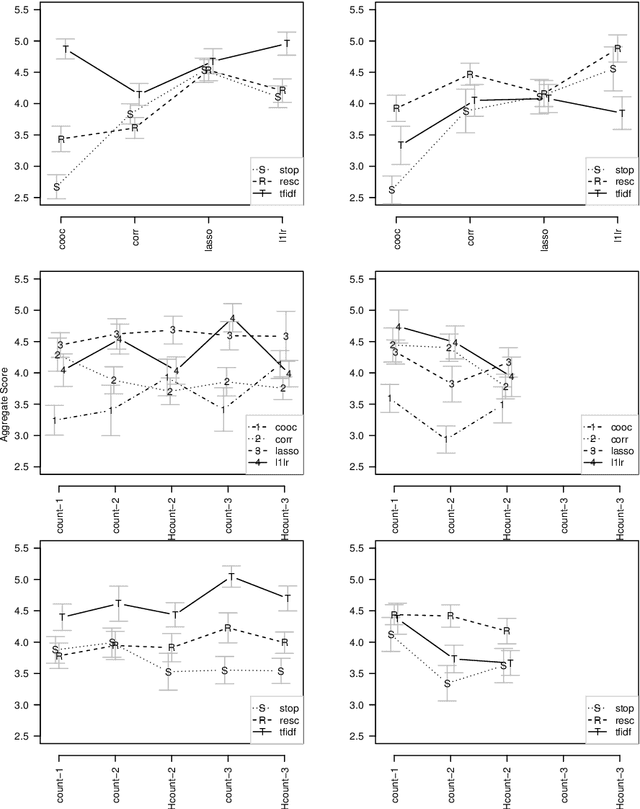
In this paper we propose a general framework for topic-specific summarization of large text corpora and illustrate how it can be used for the analysis of news databases. Our framework, concise comparative summarization (CCS), is built on sparse classification methods. CCS is a lightweight and flexible tool that offers a compromise between simple word frequency based methods currently in wide use and more heavyweight, model-intensive methods such as latent Dirichlet allocation (LDA). We argue that sparse methods have much to offer for text analysis and hope CCS opens the door for a new branch of research in this important field. For a particular topic of interest (e.g., China or energy), CSS automatically labels documents as being either on- or off-topic (usually via keyword search), and then uses sparse classification methods to predict these labels with the high-dimensional counts of all the other words and phrases in the documents. The resulting small set of phrases found as predictive are then harvested as the summary. To validate our tool, we, using news articles from the New York Times international section, designed and conducted a human survey to compare the different summarizers with human understanding. We demonstrate our approach with two case studies, a media analysis of the framing of "Egypt" in the New York Times throughout the Arab Spring and an informal comparison of the New York Times' and Wall Street Journal's coverage of "energy." Overall, we find that the Lasso with $L^2$ normalization can be effectively and usefully used to summarize large corpora, regardless of document size.