 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatching with Text Data: An Experimental Evaluation of Methods for Matching Documents and of Measuring Match Quality
Oct 03, 2018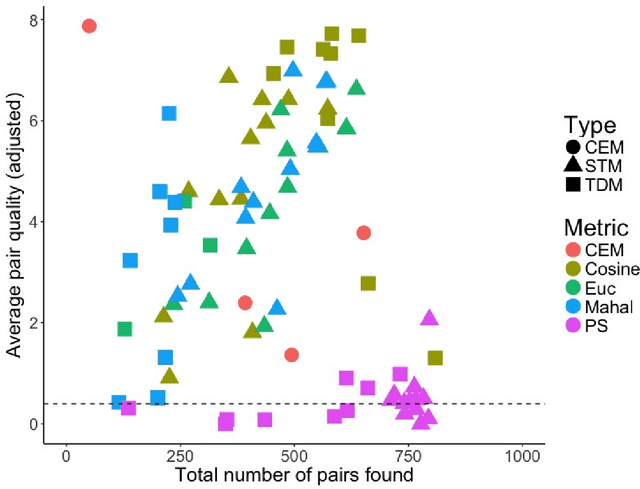
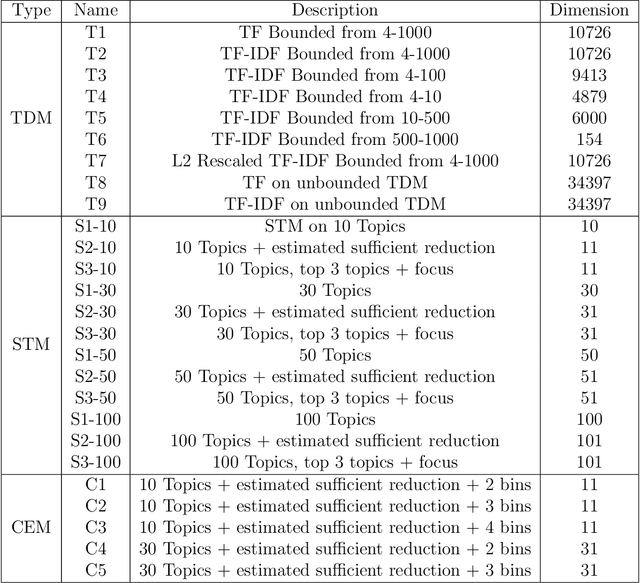
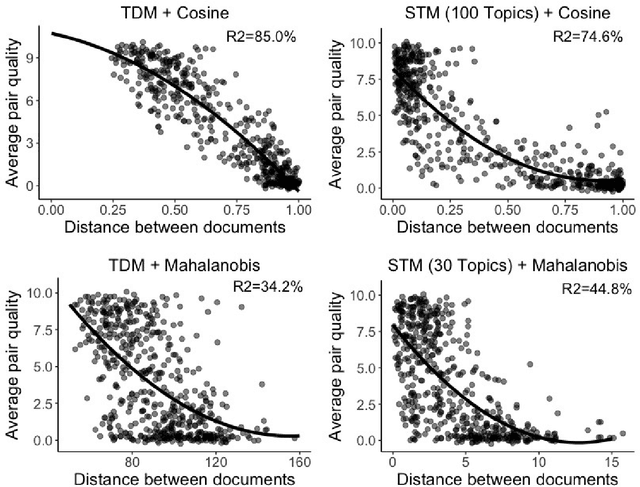
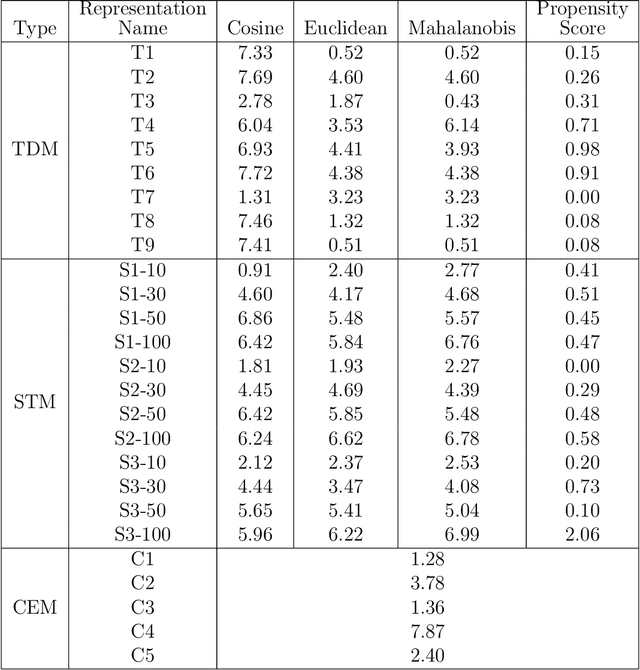
Matching for causal inference is a well-studied problem, but standard methods fail when the units to match are text documents: the high-dimensional and rich nature of the data renders exact matching infeasible, causes propensity scores to produce incomparable matches, and makes assessing match quality difficult. In this paper, we characterize a framework for matching text documents that decomposes existing methods into: (1) the choice of text representation, and (2) the choice of distance metric. We investigate how different choices within this framework affect both the quantity and quality of matches identified through a systematic multifactor evaluation experiment using human subjects. Altogether we evaluate over 100 unique text matching methods along with 5 comparison methods taken from the literature. Our experimental results identify methods that generate matches with higher subjective match quality than current state-of-the-art techniques. We enhance the precision of these results by developing a predictive model to estimate the match quality of pairs of text documents as a function of our various distance scores. This model, which we find successfully mimics human judgment, also allows for approximate and unsupervised evaluation of new procedures. We then employ the identified best method to illustrate the utility of text matching in two applications. First, we engage with a substantive debate in the study of media bias by using text matching to control for topic selection when comparing news articles from thirteen news sources. We then show how conditioning on text data leads to more precise causal inferences in an observational study examining the effects of a medical intervention.
Machine Learning for Public Administration Research, with Application to Organizational Reputation
Sep 11, 2018
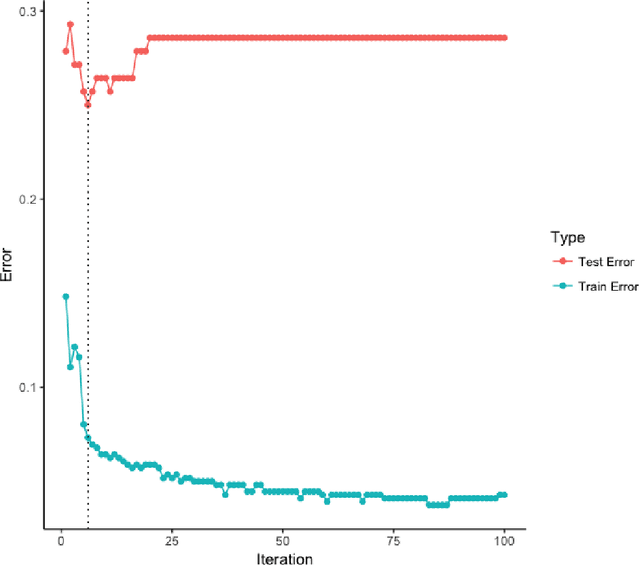

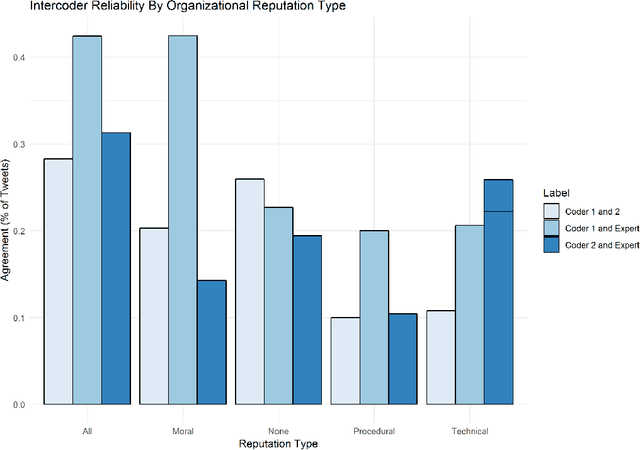
Machine learning methods have gained a great deal of popularity in recent years among public administration scholars and practitioners. These techniques open the door to the analysis of text, image and other types of data that allow us to test foundational theories of public administration and to develop new theories. Despite the excitement surrounding machine learning methods, clarity regarding their proper use and potential pitfalls is lacking. This paper attempts to fill this gap in the literature through providing a machine learning "guide to practice" for public administration scholars and practitioners. Here, we take a foundational view of machine learning and describe how these methods can enrich public administration research and practice through their ability develop new measures, tap into new sources of data and conduct statistical inference and causal inference in a principled manner. We then turn our attention to the pitfalls of using these methods such as unvalidated measures and lack of interpretability. Finally, we demonstrate how machine learning techniques can help us learn about organizational reputation in federal agencies through an illustrated example using tweets from 13 executive federal agencies.
Photographic home styles in Congress: a computer vision approach
Dec 05, 2016
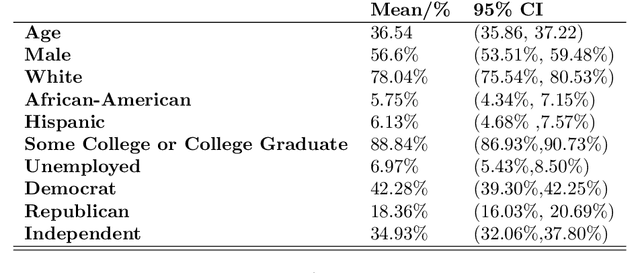


While members of Congress now routinely communicate with constituents using images on a variety of internet platforms, little is known about how images are used as a means of strategic political communication. This is due primarily to computational limitations which have prevented large-scale, systematic analyses of image features. New developments in computer vision, however, are bringing the systematic study of images within reach. Here, we develop a framework for understanding visual political communication by extending Fenno's analysis of home style (Fenno 1978) to images and introduce "photographic" home styles. Using approximately 192,000 photographs collected from MCs Facebook profiles, we build machine learning software with convolutional neural networks and conduct an image manipulation experiment to explore how the race of people that MCs pose with shape photographic home styles. We find evidence that electoral pressures shape photographic home styles and demonstrate that Democratic and Republican members of Congress use images in very different ways.