 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemote sensing colour image semantic segmentation of trails created by large herbivorous Mammals
Apr 16, 2025Detection of spatial areas where biodiversity is at risk is of paramount importance for the conservation and monitoring of ecosystems. Large terrestrial mammalian herbivores are keystone species as their activity not only has deep effects on soils, plants, and animals, but also shapes landscapes, as large herbivores act as allogenic ecosystem engineers. One key landscape feature that indicates intense herbivore activity and potentially impacts biodiversity is the formation of grazing trails. Grazing trails are formed by the continuous trampling activity of large herbivores that can produce complex networks of tracks of bare soil. Here, we evaluated different algorithms based on machine learning techniques to identify grazing trails. Our goal is to automatically detect potential areas with intense herbivory activity, which might be beneficial for conservation and management plans. We have applied five semantic segmentation methods combined with fourteen encoders aimed at mapping grazing trails on aerial images. Our results indicate that in most cases the chosen methodology successfully mapped the trails, although there were a few instances where the actual trail structure was underestimated. The UNet architecture with the MambaOut encoder was the best architecture for mapping trails. The proposed approach could be applied to develop tools for mapping and monitoring temporal changes in these landscape structures to support habitat conservation and land management programs. This is the first time, to the best of our knowledge, that competitive image segmentation results are obtained for the detection and delineation of trails of large herbivorous mammals.
Feature Selection from High-Dimensional Data with Very Low Sample Size: A Cautionary Tale
Aug 27, 2020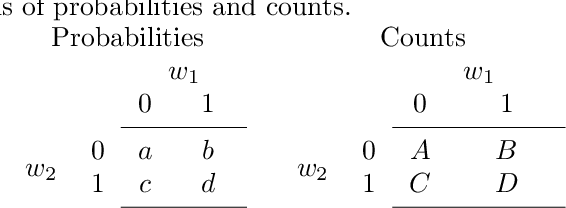



In classification problems, the purpose of feature selection is to identify a small, highly discriminative subset of the original feature set. In many applications, the dataset may have thousands of features and only a few dozens of samples (sometimes termed `wide'). This study is a cautionary tale demonstrating why feature selection in such cases may lead to undesirable results. In view to highlight the sample size issue, we derive the required sample size for declaring two features different. Using an example, we illustrate the heavy dependency between feature set and classifier, which poses a question to classifier-agnostic feature selection methods. However, the choice of a good selector-classifier pair is hampered by the low correlation between estimated and true error rate, as illustrated by another example. While previous studies raising similar issues validate their message with mostly synthetic data, here we carried out an experiment with 20 real datasets. We created an exaggerated scenario whereby we cut a very small portion of the data (10 instances per class) for feature selection and used the rest of the data for testing. The results reinforce the caution and suggest that it may be better to refrain from feature selection from very wide datasets rather than return misleading output to the user.
Bounds for the VC Dimension of 1NN Prototype Sets
Feb 07, 2019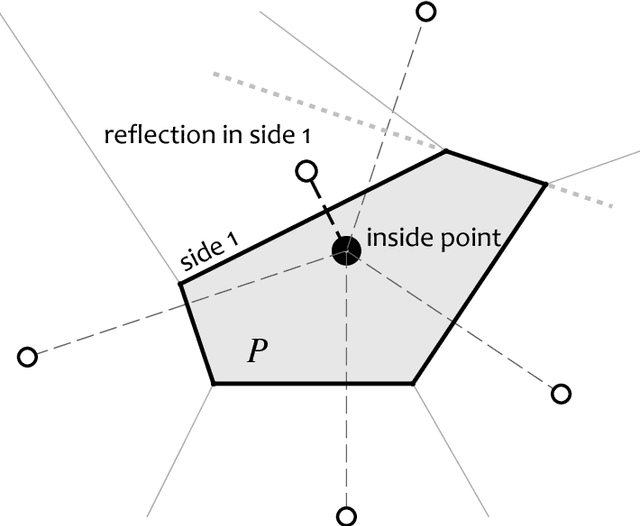
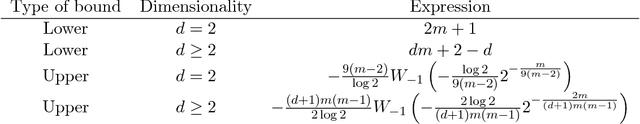
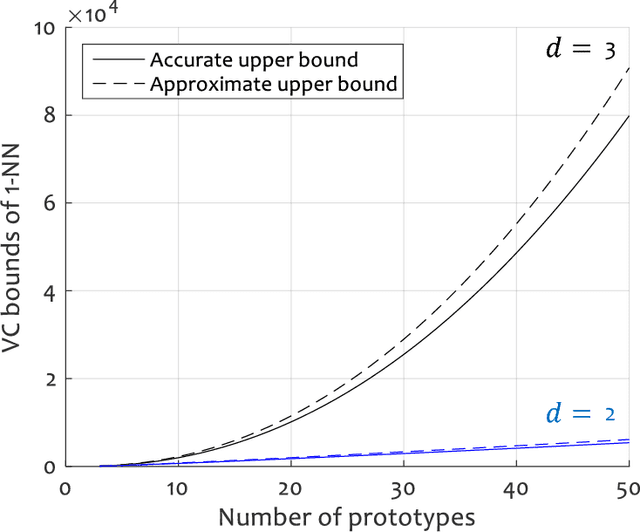
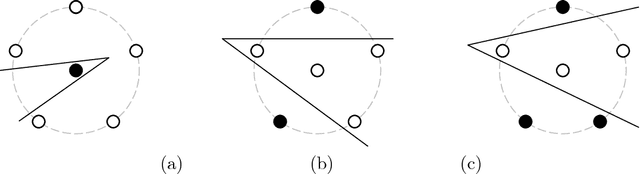
In Statistical Learning, the Vapnik-Chervonenkis (VC) dimension is an important combinatorial property of classifiers. To our knowledge, no theoretical results yet exist for the VC dimension of edited nearest-neighbour (1NN) classifiers with reference set of fixed size. Related theoretical results are scattered in the literature and their implications have not been made explicit. We collect some relevant results and use them to provide explicit lower and upper bounds for the VC dimension of 1NN classifiers with a prototype set of fixed size. We discuss the implications of these bounds for the size of training set needed to learn such a classifier to a given accuracy. Further, we provide a new lower bound for the two-dimensional case, based on a new geometrical argument.
Instance Selection Improves Geometric Mean Accuracy: A Study on Imbalanced Data Classification
Apr 19, 2018


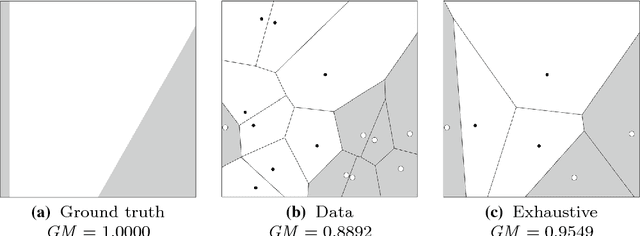
A natural way of handling imbalanced data is to attempt to equalise the class frequencies and train the classifier of choice on balanced data. For two-class imbalanced problems, the classification success is typically measured by the geometric mean (GM) of the true positive and true negative rates. Here we prove that GM can be improved upon by instance selection, and give the theoretical conditions for such an improvement. We demonstrate that GM is non-monotonic with respect to the number of retained instances, which discourages systematic instance selection. We also show that balancing the distribution frequencies is inferior to a direct maximisation of GM. To verify our theoretical findings, we carried out an experimental study of 12 instance selection methods for imbalanced data, using 66 standard benchmark data sets. The results reveal possible room for new instance selection methods for imbalanced data.
Bipartite Graph Matching for Keyframe Summary Evaluation
Dec 19, 2017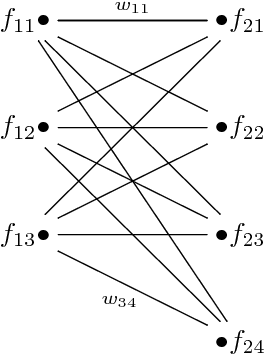
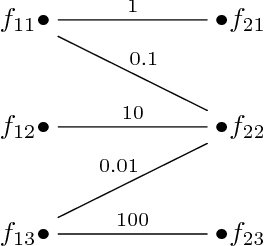


A keyframe summary, or "static storyboard", is a collection of frames from a video designed to summarise its semantic content. Many algorithms have been proposed to extract such summaries automatically. How best to evaluate these outputs is an important but little-discussed question. We review the current methods for matching frames between two summaries in the formalism of graph theory. Our analysis revealed different behaviours of these methods, which we illustrate with a number of case studies. Based on the results, we recommend a greedy matching algorithm due to Kannappan et al.
On the Evaluation of Video Keyframe Summaries using User Ground Truth
Dec 19, 2017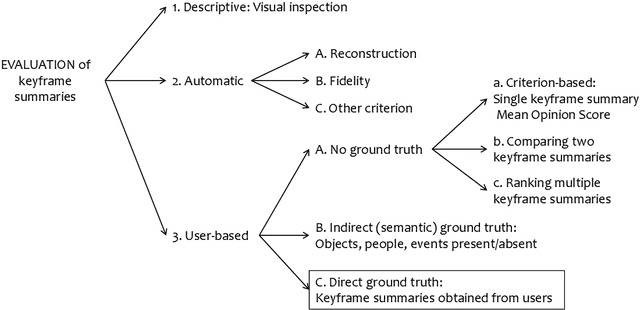

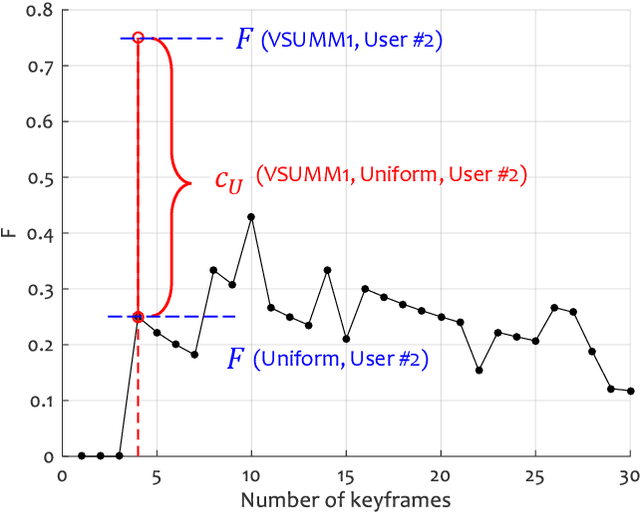
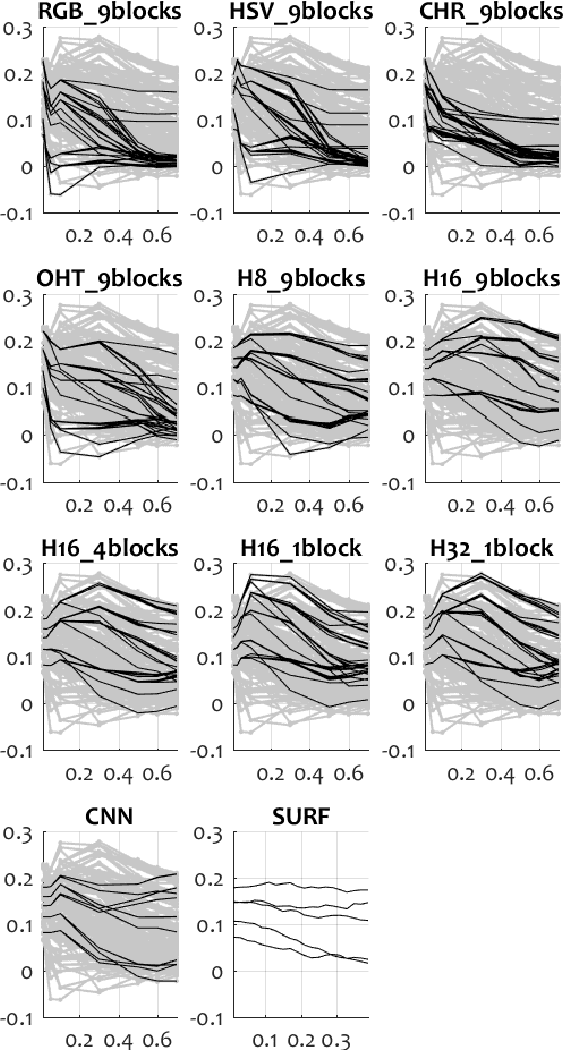
Given the great interest in creating keyframe summaries from video, it is surprising how little has been done to formalise their evaluation and comparison. User studies are often carried out to demonstrate that a proposed method generates a more appealing summary than one or two rival methods. But larger comparison studies cannot feasibly use such user surveys. Here we propose a discrimination capacity measure as a formal way to quantify the improvement over the uniform baseline, assuming that one or more ground truth summaries are available. Using the VSUMM video collection, we examine 10 video feature types, including CNN and SURF, and 6 methods for matching frames from two summaries. Our results indicate that a simple frame representation through hue histograms suffices for the purposes of comparing keyframe summaries. We subsequently propose a formal protocol for comparing summaries when ground truth is available.