 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Deep Learning-based Features Extracted from CT scans to Predict Outcomes in COVID-19 Patients
May 10, 2022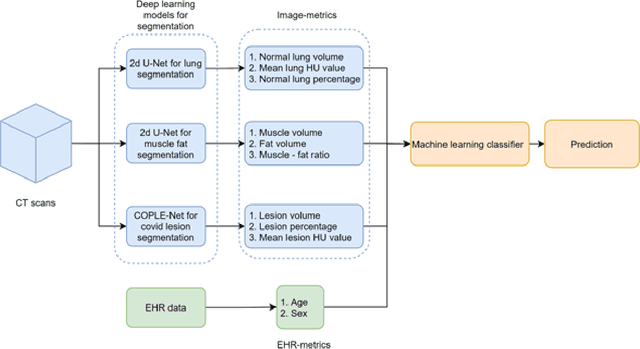

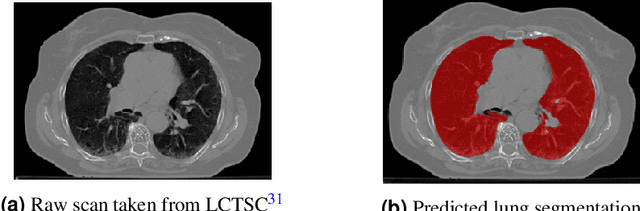
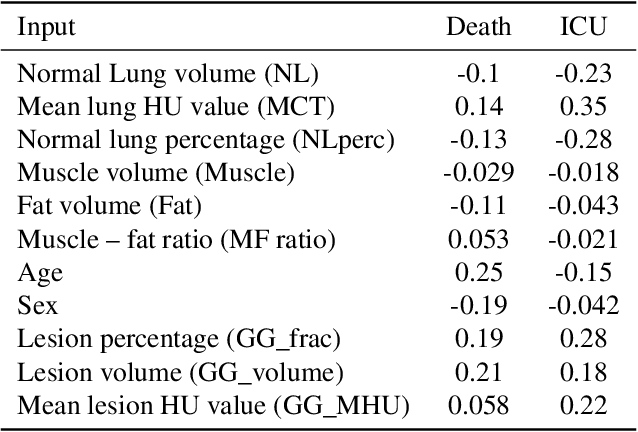
The COVID-19 pandemic has had a considerable impact on day-to-day life. Tackling the disease by providing the necessary resources to the affected is of paramount importance. However, estimation of the required resources is not a trivial task given the number of factors which determine the requirement. This issue can be addressed by predicting the probability that an infected patient requires Intensive Care Unit (ICU) support and the importance of each of the factors that influence it. Moreover, to assist the doctors in determining the patients at high risk of fatality, the probability of death is also calculated. For determining both the patient outcomes (ICU admission and death), a novel methodology is proposed by combining multi-modal features, extracted from Computed Tomography (CT) scans and Electronic Health Record (EHR) data. Deep learning models are leveraged to extract quantitative features from CT scans. These features combined with those directly read from the EHR database are fed into machine learning models to eventually output the probabilities of patient outcomes. This work demonstrates both the ability to apply a broad set of deep learning methods for general quantification of Chest CT scans and the ability to link these quantitative metrics to patient outcomes. The effectiveness of the proposed method is shown by testing it on an internally curated dataset, achieving a mean area under Receiver operating characteristic curve (AUC) of 0.77 on ICU admission prediction and a mean AUC of 0.73 on death prediction using the best performing classifiers.
Bipartite Graph Matching for Keyframe Summary Evaluation
Dec 19, 2017
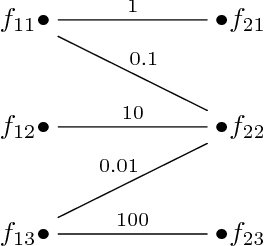


A keyframe summary, or "static storyboard", is a collection of frames from a video designed to summarise its semantic content. Many algorithms have been proposed to extract such summaries automatically. How best to evaluate these outputs is an important but little-discussed question. We review the current methods for matching frames between two summaries in the formalism of graph theory. Our analysis revealed different behaviours of these methods, which we illustrate with a number of case studies. Based on the results, we recommend a greedy matching algorithm due to Kannappan et al.
On the Evaluation of Video Keyframe Summaries using User Ground Truth
Dec 19, 2017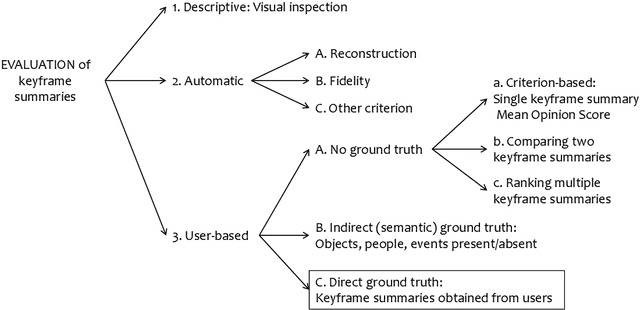

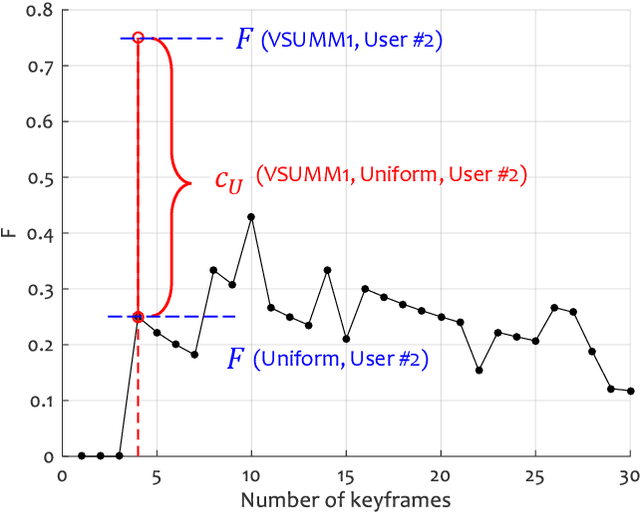
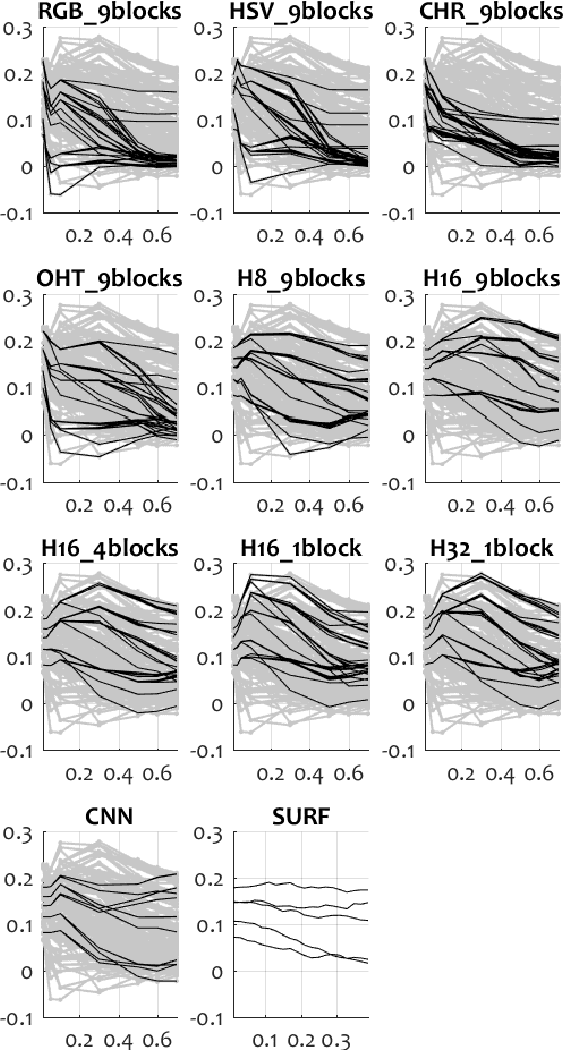
Given the great interest in creating keyframe summaries from video, it is surprising how little has been done to formalise their evaluation and comparison. User studies are often carried out to demonstrate that a proposed method generates a more appealing summary than one or two rival methods. But larger comparison studies cannot feasibly use such user surveys. Here we propose a discrimination capacity measure as a formal way to quantify the improvement over the uniform baseline, assuming that one or more ground truth summaries are available. Using the VSUMM video collection, we examine 10 video feature types, including CNN and SURF, and 6 methods for matching frames from two summaries. Our results indicate that a simple frame representation through hue histograms suffices for the purposes of comparing keyframe summaries. We subsequently propose a formal protocol for comparing summaries when ground truth is available.