 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Selection from High-Dimensional Data with Very Low Sample Size: A Cautionary Tale
Aug 27, 2020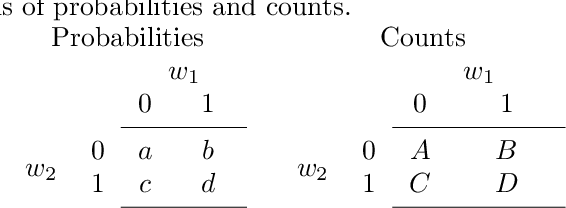



In classification problems, the purpose of feature selection is to identify a small, highly discriminative subset of the original feature set. In many applications, the dataset may have thousands of features and only a few dozens of samples (sometimes termed `wide'). This study is a cautionary tale demonstrating why feature selection in such cases may lead to undesirable results. In view to highlight the sample size issue, we derive the required sample size for declaring two features different. Using an example, we illustrate the heavy dependency between feature set and classifier, which poses a question to classifier-agnostic feature selection methods. However, the choice of a good selector-classifier pair is hampered by the low correlation between estimated and true error rate, as illustrated by another example. While previous studies raising similar issues validate their message with mostly synthetic data, here we carried out an experiment with 20 real datasets. We created an exaggerated scenario whereby we cut a very small portion of the data (10 instances per class) for feature selection and used the rest of the data for testing. The results reinforce the caution and suggest that it may be better to refrain from feature selection from very wide datasets rather than return misleading output to the user.