 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual and audio scene classification for detecting discrepancies in video: a baseline method and experimental protocol
May 01, 2024



This paper presents a baseline approach and an experimental protocol for a specific content verification problem: detecting discrepancies between the audio and video modalities in multimedia content. We first design and optimize an audio-visual scene classifier, to compare with existing classification baselines that use both modalities. Then, by applying this classifier separately to the audio and the visual modality, we can detect scene-class inconsistencies between them. To facilitate further research and provide a common evaluation platform, we introduce an experimental protocol and a benchmark dataset simulating such inconsistencies. Our approach achieves state-of-the-art results in scene classification and promising outcomes in audio-visual discrepancies detection, highlighting its potential in content verification applications.
Environment Classification via Blind Roomprints Estimation
Sep 15, 2022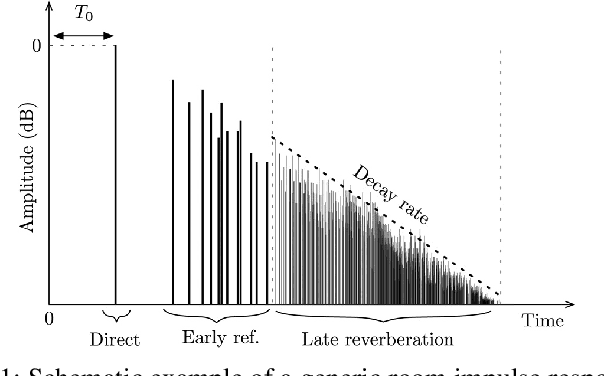
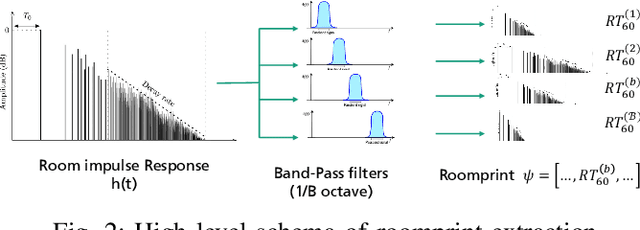


In this paper we present a novel approach for environment classification for speech recordings, which does not require the selection of decaying reverberation tails. It is based on a multi-band RT60 analysis of blind channel estimates and achieves an accuracy of up to 93.6% on test recordings derived from the ACE corpus.
Open Challenges in Synthetic Speech Detection
Sep 15, 2022
In this paper the current status and open challenges of synthetic speech detection are addressed. The work comprises an initial analysis of available open datasets and of existing detection methods, a description of the requirements for new research datasets compliant with regulations and better representing real-case scenarios, and a discussion of the desired characteristics of future trustworthy detection methods in terms of both functional and non-functional requirements. Compared to other works, based on specific detection solutions or presenting single dataset of synthetic speeches, our paper is meant to orient future state-of-the-art research in the domain, to quickly lessen the current gap between synthesis and detection approaches.
Speaker-Independent Microphone Identification in Noisy Conditions
Jun 23, 2022


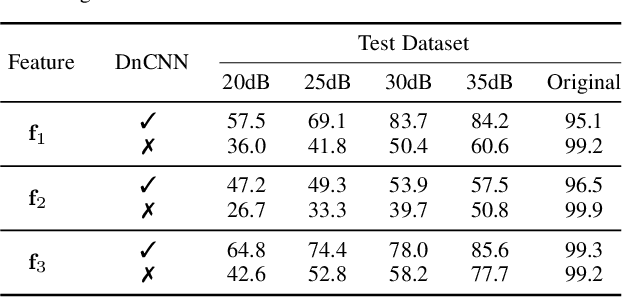
This work proposes a method for source device identification from speech recordings that applies neural-network-based denoising, to mitigate the impact of counter-forensics attacks using noise injection. The method is evaluated by comparing the impact of denoising on three state-of-the-art features for microphone classification, determining their discriminating power with and without denoising being applied. The proposed framework achieves a significant performance increase for noisy material, and more generally, validates the usefulness of applying denoising prior to device identification for noisy recordings.