 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpherical Inducing Features for Orthogonally-Decoupled Gaussian Processes
Apr 27, 2023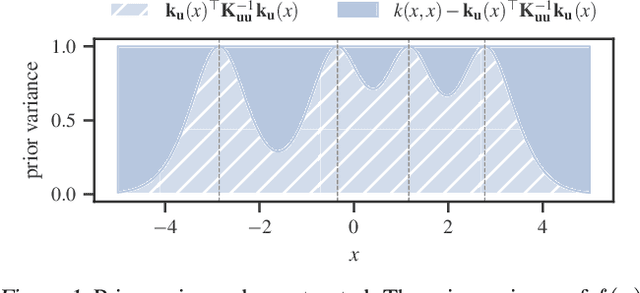
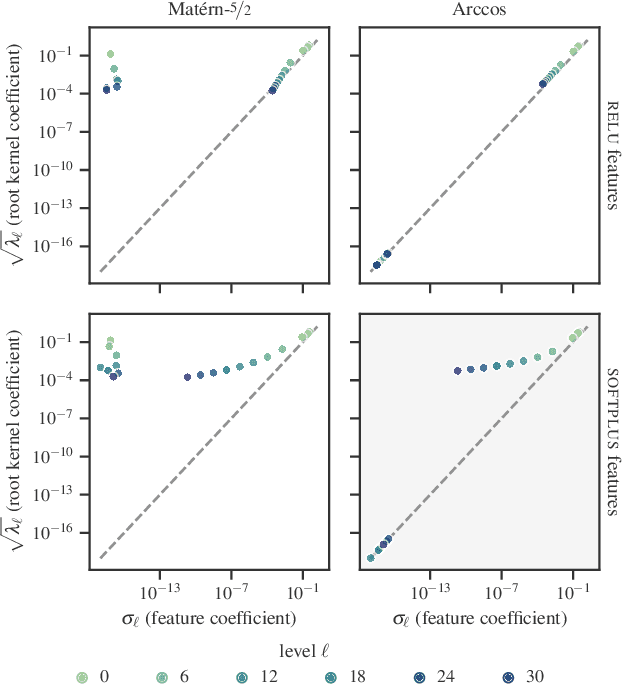

Despite their many desirable properties, Gaussian processes (GPs) are often compared unfavorably to deep neural networks (NNs) for lacking the ability to learn representations. Recent efforts to bridge the gap between GPs and deep NNs have yielded a new class of inter-domain variational GPs in which the inducing variables correspond to hidden units of a feedforward NN. In this work, we examine some practical issues associated with this approach and propose an extension that leverages the orthogonal decomposition of GPs to mitigate these limitations. In particular, we introduce spherical inter-domain features to construct more flexible data-dependent basis functions for both the principal and orthogonal components of the GP approximation and show that incorporating NN activation features under this framework not only alleviates these shortcomings but is more scalable than alternative strategies. Experiments on multiple benchmark datasets demonstrate the effectiveness of our approach.
BORE: Bayesian Optimization by Density-Ratio Estimation
Feb 17, 2021



Bayesian optimization (BO) is among the most effective and widely-used blackbox optimization methods. BO proposes solutions according to an explore-exploit trade-off criterion encoded in an acquisition function, many of which are computed from the posterior predictive of a probabilistic surrogate model. Prevalent among these is the expected improvement (EI) function. The need to ensure analytical tractability of the predictive often poses limitations that can hinder the efficiency and applicability of BO. In this paper, we cast the computation of EI as a binary classification problem, building on the link between class-probability estimation and density-ratio estimation, and the lesser-known link between density-ratios and EI. By circumventing the tractability constraints, this reformulation provides numerous advantages, not least in terms of expressiveness, versatility, and scalability.
Model-based Asynchronous Hyperparameter Optimization
Mar 24, 2020



We introduce a model-based asynchronous multi-fidelity hyperparameter optimization (HPO) method, combining strengths of asynchronous Hyperband and Gaussian process-based Bayesian optimization. Our method obtains substantial speed-ups in wall-clock time over, both, synchronous and asynchronous Hyperband, as well as a prior model-based extension of the former. Candidate hyperparameters to evaluate are selected by a novel jointly dependent Gaussian process-based surrogate model over all resource levels, allowing evaluations at one level to be informed by evaluations gathered at all others. We benchmark several covariance functions and conduct extensive experiments on hyperparameter tuning for multi-layer perceptrons on tabular data, convolutional networks on image classification, and recurrent networks on language modelling, demonstrating the benefits of our approach.
Cycle-Consistent Adversarial Learning as Approximate Bayesian Inference
Aug 24, 2018



We formalize the problem of learning interdomain correspondences in the absence of paired data as Bayesian inference in a latent variable model (LVM), where one seeks the underlying hidden representations of entities from one domain as entities from the other domain. First, we introduce implicit latent variable models, where the prior over hidden representations can be specified flexibly as an implicit distribution. Next, we develop a new variational inference (VI) algorithm for this model based on minimization of the symmetric Kullback-Leibler (KL) divergence between a variational joint and the exact joint distribution. Lastly, we demonstrate that the state-of-the-art cycle-consistent adversarial learning (CYCLEGAN) models can be derived as a special case within our proposed VI framework, thus establishing its connection to approximate Bayesian inference methods.