 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Generative Learning Trilemma: Generative Model Assessment in Data Scarcity Domains
Apr 14, 2025
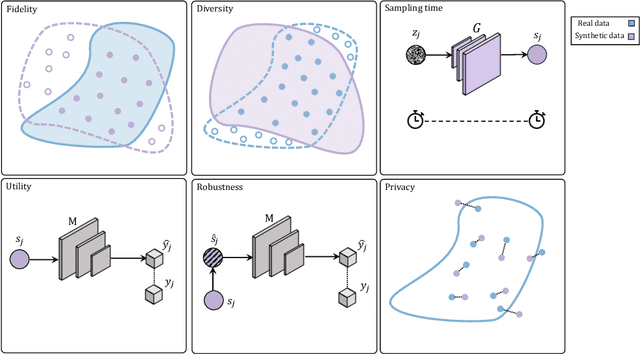
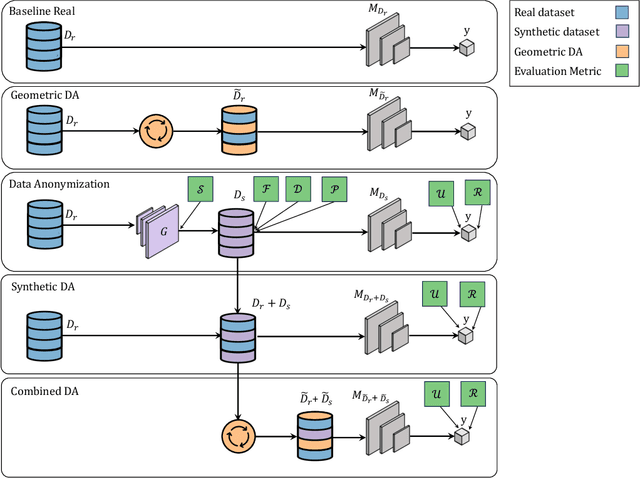
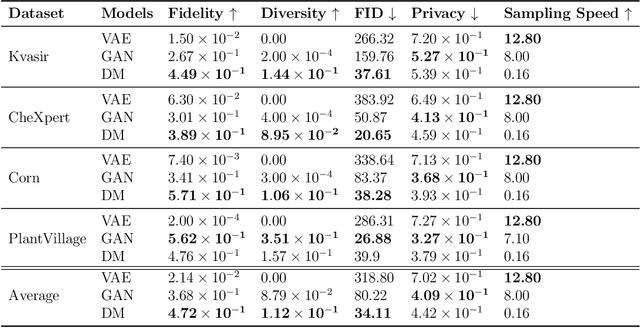
Data scarcity remains a critical bottleneck impeding technological advancements across various domains, including but not limited to medicine and precision agriculture. To address this challenge, we explore the potential of Deep Generative Models (DGMs) in producing synthetic data that satisfies the Generative Learning Trilemma: fidelity, diversity, and sampling efficiency. However, recognizing that these criteria alone are insufficient for practical applications, we extend the trilemma to include utility, robustness, and privacy, factors crucial for ensuring the applicability of DGMs in real-world scenarios. Evaluating these metrics becomes particularly challenging in data-scarce environments, as DGMs traditionally rely on large datasets to perform optimally. This limitation is especially pronounced in domains like medicine and precision agriculture, where ensuring acceptable model performance under data constraints is vital. To address these challenges, we assess the Generative Learning Trilemma in data-scarcity settings using state-of-the-art evaluation metrics, comparing three prominent DGMs: Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), and Diffusion Models (DMs). Furthermore, we propose a comprehensive framework to assess utility, robustness, and privacy in synthetic data generated by DGMs. Our findings demonstrate varying strengths among DGMs, with each model exhibiting unique advantages based on the application context. This study broadens the scope of the Generative Learning Trilemma, aligning it with real-world demands and providing actionable guidance for selecting DGMs tailored to specific applications.
Beyond a Single Mode: GAN Ensembles for Diverse Medical Data Generation
Mar 31, 2025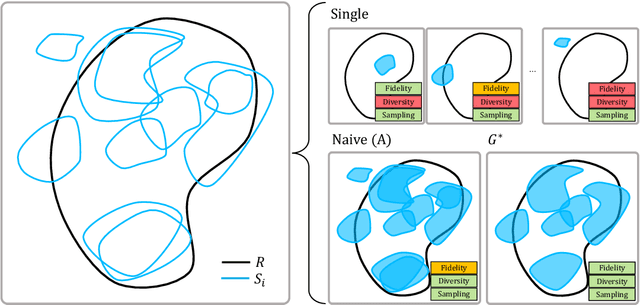

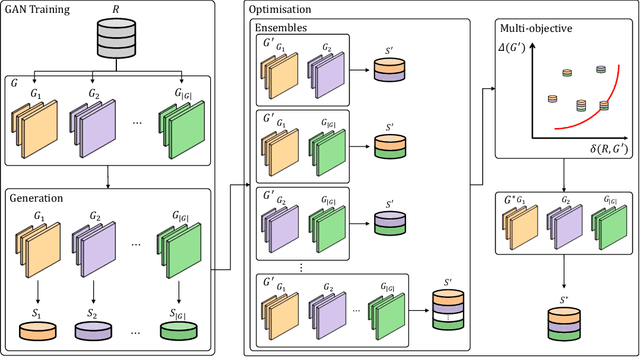
The advancement of generative AI, particularly in medical imaging, confronts the trilemma of ensuring high fidelity, diversity, and efficiency in synthetic data generation. While Generative Adversarial Networks (GANs) have shown promise across various applications, they still face challenges like mode collapse and insufficient coverage of real data distributions. This work explores the use of GAN ensembles to overcome these limitations, specifically in the context of medical imaging. By solving a multi-objective optimisation problem that balances fidelity and diversity, we propose a method for selecting an optimal ensemble of GANs tailored for medical data. The selected ensemble is capable of generating diverse synthetic medical images that are representative of true data distributions and computationally efficient. Each model in the ensemble brings a unique contribution, ensuring minimal redundancy. We conducted a comprehensive evaluation using three distinct medical datasets, testing 22 different GAN architectures with various loss functions and regularisation techniques. By sampling models at different training epochs, we crafted 110 unique configurations. The results highlight the capability of GAN ensembles to enhance the quality and utility of synthetic medical images, thereby improving the efficacy of downstream tasks such as diagnostic modelling.
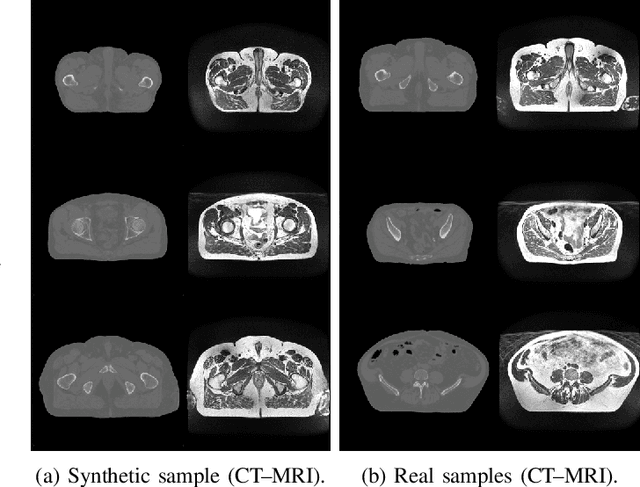
Whole-Body Image-to-Image Translation for a Virtual Scanner in a Healthcare Digital Twin
Mar 18, 2025



Generating positron emission tomography (PET) images from computed tomography (CT) scans via deep learning offers a promising pathway to reduce radiation exposure and costs associated with PET imaging, improving patient care and accessibility to functional imaging. Whole-body image translation presents challenges due to anatomical heterogeneity, often limiting generalized models. We propose a framework that segments whole-body CT images into four regions-head, trunk, arms, and legs-and uses district-specific Generative Adversarial Networks (GANs) for tailored CT-to-PET translation. Synthetic PET images from each region are stitched together to reconstruct the whole-body scan. Comparisons with a baseline non-segmented GAN and experiments with Pix2Pix and CycleGAN architectures tested paired and unpaired scenarios. Quantitative evaluations at district, whole-body, and lesion levels demonstrated significant improvements with our district-specific GANs. Pix2Pix yielded superior metrics, ensuring precise, high-quality image synthesis. By addressing anatomical heterogeneity, this approach achieves state-of-the-art results in whole-body CT-to-PET translation. This methodology supports healthcare Digital Twins by enabling accurate virtual PET scans from CT data, creating virtual imaging representations to monitor, predict, and optimize health outcomes.
Using Synthetic Images to Augment Small Medical Image Datasets
Mar 02, 2025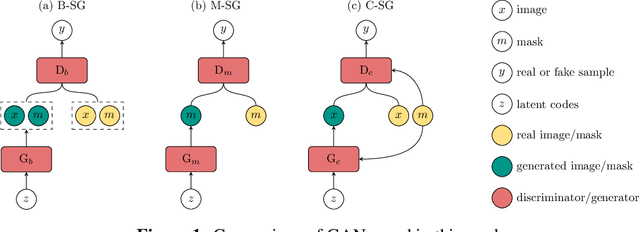

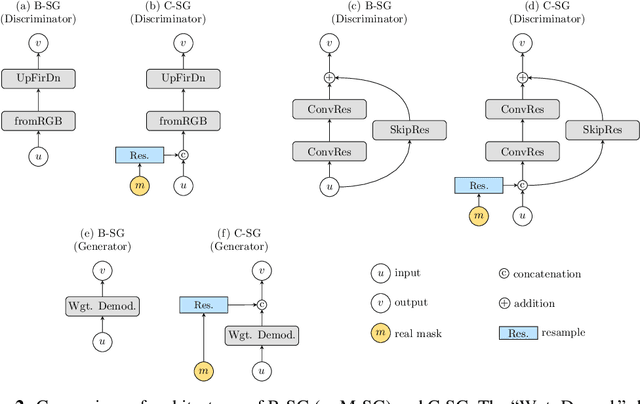

Recent years have witnessed a growing academic and industrial interest in deep learning (DL) for medical imaging. To perform well, DL models require very large labeled datasets. However, most medical imaging datasets are small, with a limited number of annotated samples. The reason they are small is usually because delineating medical images is time-consuming and demanding for oncologists. There are various techniques that can be used to augment a dataset, for example, to apply affine transformations or elastic transformations to available images, or to add synthetic images generated by a Generative Adversarial Network (GAN). In this work, we have developed a novel conditional variant of a current GAN method, the StyleGAN2, to generate multi-modal high-resolution medical images with the purpose to augment small medical imaging datasets with these synthetic images. We use the synthetic and real images from six datasets to train models for the downstream task of semantic segmentation. The quality of the generated medical images and the effect of this augmentation on the segmentation performance were evaluated afterward. Finally, the results indicate that the downstream segmentation models did not benefit from the generated images. Further work and analyses are required to establish how this augmentation affects the segmentation performance.
Multi-Dataset Multi-Task Learning for COVID-19 Prognosis
May 22, 2024In the fight against the COVID-19 pandemic, leveraging artificial intelligence to predict disease outcomes from chest radiographic images represents a significant scientific aim. The challenge, however, lies in the scarcity of large, labeled datasets with compatible tasks for training deep learning models without leading to overfitting. Addressing this issue, we introduce a novel multi-dataset multi-task training framework that predicts COVID-19 prognostic outcomes from chest X-rays (CXR) by integrating correlated datasets from disparate sources, distant from conventional multi-task learning approaches, which rely on datasets with multiple and correlated labeling schemes. Our framework hypothesizes that assessing severity scores enhances the model's ability to classify prognostic severity groups, thereby improving its robustness and predictive power. The proposed architecture comprises a deep convolutional network that receives inputs from two publicly available CXR datasets, AIforCOVID for severity prognostic prediction and BRIXIA for severity score assessment, and branches into task-specific fully connected output networks. Moreover, we propose a multi-task loss function, incorporating an indicator function, to exploit multi-dataset integration. The effectiveness and robustness of the proposed approach are demonstrated through significant performance improvements in prognosis classification tasks across 18 different convolutional neural network backbones in different evaluation strategies. This improvement is evident over single-task baselines and standard transfer learning strategies, supported by extensive statistical analysis, showing great application potential.
Multi-Scale Texture Loss for CT denoising with GANs
Mar 25, 2024

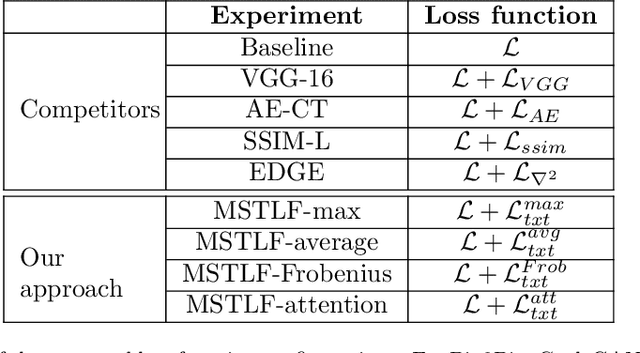

Generative Adversarial Networks (GANs) have proved as a powerful framework for denoising applications in medical imaging. However, GAN-based denoising algorithms still suffer from limitations in capturing complex relationships within the images. In this regard, the loss function plays a crucial role in guiding the image generation process, encompassing how much a synthetic image differs from a real image. To grasp highly complex and non-linear textural relationships in the training process, this work presents a loss function that leverages the intrinsic multi-scale nature of the Gray-Level-Co-occurrence Matrix (GLCM). Although the recent advances in deep learning have demonstrated superior performance in classification and detection tasks, we hypothesize that its information content can be valuable when integrated into GANs' training. To this end, we propose a differentiable implementation of the GLCM suited for gradient-based optimization. Our approach also introduces a self-attention layer that dynamically aggregates the multi-scale texture information extracted from the images. We validate our approach by carrying out extensive experiments in the context of low-dose CT denoising, a challenging application that aims to enhance the quality of noisy CT scans. We utilize three publicly available datasets, including one simulated and two real datasets. The results are promising as compared to other well-established loss functions, being also consistent across three different GAN architectures. The code is available at: https://github.com/FrancescoDiFeola/DenoTextureLoss
LatentAugment: Data Augmentation via Guided Manipulation of GAN's Latent Space
Jul 21, 2023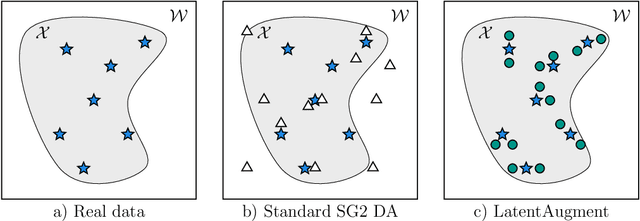
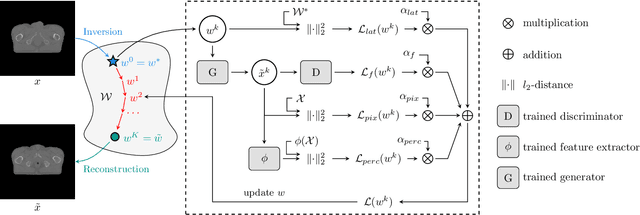
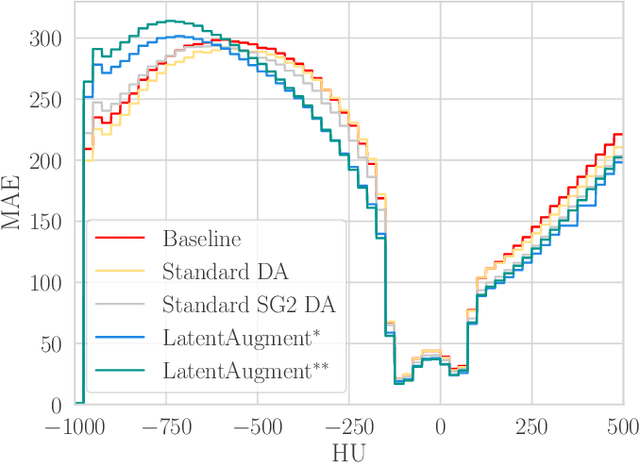
Data Augmentation (DA) is a technique to increase the quantity and diversity of the training data, and by that alleviate overfitting and improve generalisation. However, standard DA produces synthetic data for augmentation with limited diversity. Generative Adversarial Networks (GANs) may unlock additional information in a dataset by generating synthetic samples having the appearance of real images. However, these models struggle to simultaneously address three key requirements: fidelity and high-quality samples; diversity and mode coverage; and fast sampling. Indeed, GANs generate high-quality samples rapidly, but have poor mode coverage, limiting their adoption in DA applications. We propose LatentAugment, a DA strategy that overcomes the low diversity of GANs, opening up for use in DA applications. Without external supervision, LatentAugment modifies latent vectors and moves them into latent space regions to maximise the synthetic images' diversity and fidelity. It is also agnostic to the dataset and the downstream task. A wide set of experiments shows that LatentAugment improves the generalisation of a deep model translating from MRI-to-CT beating both standard DA as well GAN-based sampling. Moreover, still in comparison with GAN-based sampling, LatentAugment synthetic samples show superior mode coverage and diversity. Code is available at: https://github.com/ltronchin/LatentAugment.
A comparative study between paired and unpaired Image Quality Assessment in Low-Dose CT Denoising
Apr 11, 2023The current deep learning approaches for low-dose CT denoising can be divided into paired and unpaired methods. The former involves the use of well-paired datasets, whilst the latter relaxes this constraint. The large availability of unpaired datasets has raised the interest in deepening unpaired denoising strategies that, in turn, need for robust evaluation techniques going beyond the qualitative evaluation. To this end, we can use quantitative image quality assessment scores that we divided into two categories, i.e., paired and unpaired measures. However, the interpretation of unpaired metrics is not straightforward, also because the consistency with paired metrics has not been fully investigated. To cope with this limitation, in this work we consider 15 paired and unpaired scores, which we applied to assess the performance of low-dose CT denoising. We perform an in-depth statistical analysis that not only studies the correlation between paired and unpaired metrics but also within each category. This brings out useful guidelines that can help researchers and practitioners select the right measure for their applications.
Multimodal Explainability via Latent Shift applied to COVID-19 stratification
Dec 28, 2022



We are witnessing a widespread adoption of artificial intelligence in healthcare. However, most of the advancements in deep learning (DL) in this area consider only unimodal data, neglecting other modalities. Their multimodal interpretation necessary for supporting diagnosis, prognosis and treatment decisions. In this work we present a deep architecture, explainable by design, which jointly learns modality reconstructions and sample classifications using tabular and imaging data. The explanation of the decision taken is computed by applying a latent shift that, simulates a counterfactual prediction revealing the features of each modality that contribute the most to the decision and a quantitative score indicating the modality importance. We validate our approach in the context of COVID-19 pandemic using the AIforCOVID dataset, which contains multimodal data for the early identification of patients at risk of severe outcome. The results show that the proposed method provides meaningful explanations without degrading the classification performance.