 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTop-$K$ ranking with a monotone adversary
Feb 12, 2024


In this paper, we address the top-$K$ ranking problem with a monotone adversary. We consider the scenario where a comparison graph is randomly generated and the adversary is allowed to add arbitrary edges. The statistician's goal is then to accurately identify the top-$K$ preferred items based on pairwise comparisons derived from this semi-random comparison graph. The main contribution of this paper is to develop a weighted maximum likelihood estimator (MLE) that achieves near-optimal sample complexity, up to a $\log^2(n)$ factor, where n denotes the number of items under comparison. This is made possible through a combination of analytical and algorithmic innovations. On the analytical front, we provide a refined $\ell_\infty$ error analysis of the weighted MLE that is more explicit and tighter than existing analyses. It relates the $\ell_\infty$ error with the spectral properties of the weighted comparison graph. Motivated by this, our algorithmic innovation involves the development of an SDP-based approach to reweight the semi-random graph and meet specified spectral properties. Additionally, we propose a first-order method based on the Matrix Multiplicative Weight Update (MMWU) framework. This method efficiently solves the resulting SDP in nearly-linear time relative to the size of the semi-random comparison graph.
Conjugate Gradients and Accelerated Methods Unified: The Approximate Duality Gap View
Jul 16, 2019This note provides a novel, simple analysis of the method of conjugate gradients for the minimization of convex quadratic functions. In contrast with standard arguments, our proof is entirely self-contained and does not rely on the existence of Chebyshev polynomials. Another advantage of our development is that it clarifies the relation between the method of conjugate gradients and general accelerated methods for smooth minimization by unifying their analyses within the framework of the Approximate Duality Gap Technique that was introduced by the authors.
Linear Coupling: An Ultimate Unification of Gradient and Mirror Descent
Nov 07, 2016First-order methods play a central role in large-scale machine learning. Even though many variations exist, each suited to a particular problem, almost all such methods fundamentally rely on two types of algorithmic steps: gradient descent, which yields primal progress, and mirror descent, which yields dual progress. We observe that the performances of gradient and mirror descent are complementary, so that faster algorithms can be designed by LINEARLY COUPLING the two. We show how to reconstruct Nesterov's accelerated gradient methods using linear coupling, which gives a cleaner interpretation than Nesterov's original proofs. We also discuss the power of linear coupling by extending it to many other settings that Nesterov's methods cannot apply to.
Spectral Sparsification and Regret Minimization Beyond Matrix Multiplicative Updates
Jun 16, 2015
In this paper, we provide a novel construction of the linear-sized spectral sparsifiers of Batson, Spielman and Srivastava [BSS14]. While previous constructions required $\Omega(n^4)$ running time [BSS14, Zou12], our sparsification routine can be implemented in almost-quadratic running time $O(n^{2+\varepsilon})$. The fundamental conceptual novelty of our work is the leveraging of a strong connection between sparsification and a regret minimization problem over density matrices. This connection was known to provide an interpretation of the randomized sparsifiers of Spielman and Srivastava [SS11] via the application of matrix multiplicative weight updates (MWU) [CHS11, Vis14]. In this paper, we explain how matrix MWU naturally arises as an instance of the Follow-the-Regularized-Leader framework and generalize this approach to yield a larger class of updates. This new class allows us to accelerate the construction of linear-sized spectral sparsifiers, and give novel insights on the motivation behind Batson, Spielman and Srivastava [BSS14].
Flow-Based Algorithms for Local Graph Clustering
Oct 13, 2013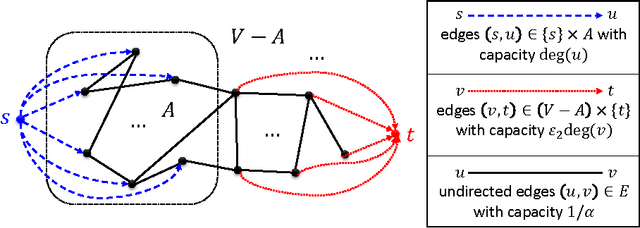

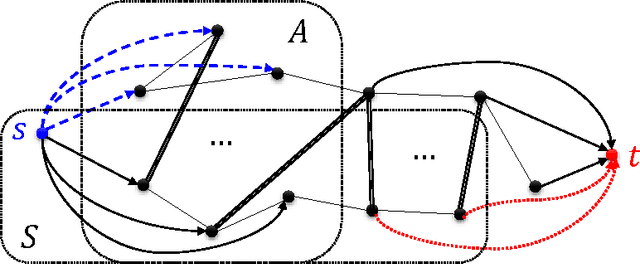
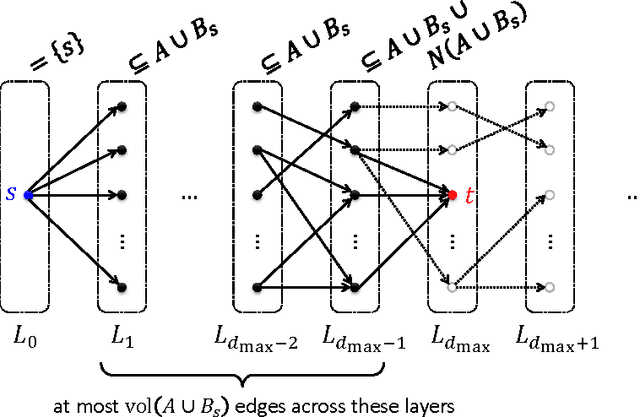
Given a subset S of vertices of an undirected graph G, the cut-improvement problem asks us to find a subset S that is similar to A but has smaller conductance. A very elegant algorithm for this problem has been given by Andersen and Lang [AL08] and requires solving a small number of single-commodity maximum flow computations over the whole graph G. In this paper, we introduce LocalImprove, the first cut-improvement algorithm that is local, i.e. that runs in time dependent on the size of the input set A rather than on the size of the entire graph. Moreover, LocalImprove achieves this local behaviour while essentially matching the same theoretical guarantee as the global algorithm of Andersen and Lang. The main application of LocalImprove is to the design of better local-graph-partitioning algorithms. All previously known local algorithms for graph partitioning are random-walk based and can only guarantee an output conductance of O(\sqrt{OPT}) when the target set has conductance OPT \in [0,1]. Very recently, Zhu, Lattanzi and Mirrokni [ZLM13] improved this to O(OPT / \sqrt{CONN}) where the internal connectivity parameter CONN \in [0,1] is defined as the reciprocal of the mixing time of the random walk over the graph induced by the target set. In this work, we show how to use LocalImprove to obtain a constant approximation O(OPT) as long as CONN/OPT = Omega(1). This yields the first flow-based algorithm. Moreover, its performance strictly outperforms the ones based on random walks and surprisingly matches that of the best known global algorithm, which is SDP-based, in this parameter regime [MMV12]. Finally, our results show that spectral methods are not the only viable approach to the construction of local graph partitioning algorithm and open door to the study of algorithms with even better approximation and locality guarantees.
Implementing regularization implicitly via approximate eigenvector computation
Apr 27, 2011Regularization is a powerful technique for extracting useful information from noisy data. Typically, it is implemented by adding some sort of norm constraint to an objective function and then exactly optimizing the modified objective function. This procedure often leads to optimization problems that are computationally more expensive than the original problem, a fact that is clearly problematic if one is interested in large-scale applications. On the other hand, a large body of empirical work has demonstrated that heuristics, and in some cases approximation algorithms, developed to speed up computations sometimes have the side-effect of performing regularization implicitly. Thus, we consider the question: What is the regularized optimization objective that an approximation algorithm is exactly optimizing? We address this question in the context of computing approximations to the smallest nontrivial eigenvector of a graph Laplacian; and we consider three random-walk-based procedures: one based on the heat kernel of the graph, one based on computing the the PageRank vector associated with the graph, and one based on a truncated lazy random walk. In each case, we provide a precise characterization of the manner in which the approximation method can be viewed as implicitly computing the exact solution to a regularized problem. Interestingly, the regularization is not on the usual vector form of the optimization problem, but instead it is on a related semidefinite program.