 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Based Multi-Document Summarization Exploiting Main-Event Biased Monotone Submodular Content Extraction
Oct 05, 2023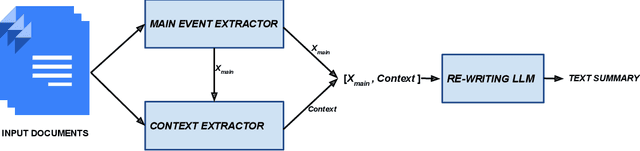
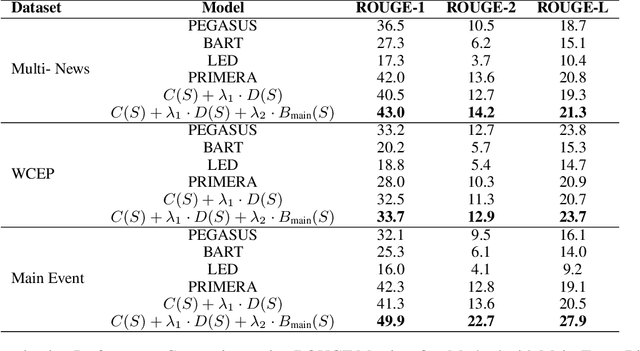

Multi-document summarization is a challenging task due to its inherent subjective bias, highlighted by the low inter-annotator ROUGE-1 score of 0.4 among DUC-2004 reference summaries. In this work, we aim to enhance the objectivity of news summarization by focusing on the main event of a group of related news documents and presenting it coherently with sufficient context. Our primary objective is to succinctly report the main event, ensuring that the summary remains objective and informative. To achieve this, we employ an extract-rewrite approach that incorporates a main-event biased monotone-submodular function for content selection. This enables us to extract the most crucial information related to the main event from the document cluster. To ensure coherence, we utilize a fine-tuned Language Model (LLM) for rewriting the extracted content into a coherent text. The evaluation using objective metrics and human evaluators confirms the effectiveness of our approach, as it surpasses potential baselines, demonstrating excellence in both content coverage, coherence, and informativeness.
Controllable Multi-document Summarization: Coverage & Coherence Intuitive Policy with Large Language Model Based Rewards
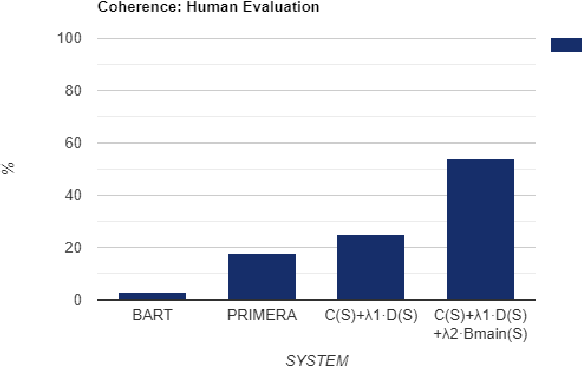
Oct 05, 2023Memory-efficient large language models are good at refining text input for better readability. However, controllability is a matter of concern when it comes to text generation tasks with long inputs, such as multi-document summarization. In this work, we investigate for a generic controllable approach for multi-document summarization that leverages the capabilities of LLMs to refine the text. In particular, we train a controllable content extraction scheme to extract the text that will be refined by an LLM. The scheme is designed with a novel coverage and coherence intuitive policy, which is duly rewarded by a passively trained LLM. Our approach yields competitive results in the evaluation using ROUGE metrics and outperforms potential baselines in coherence, as per human evaluation.
Attention-based Neural Text Segmentation
Aug 29, 2018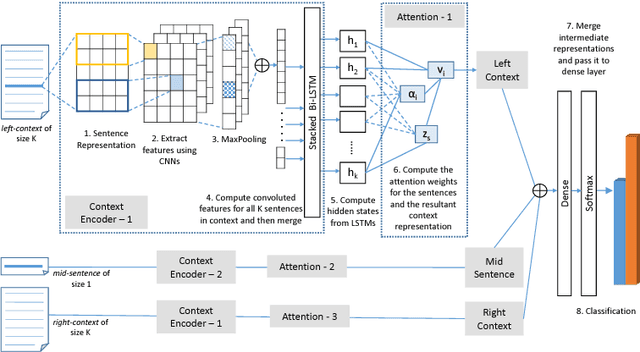
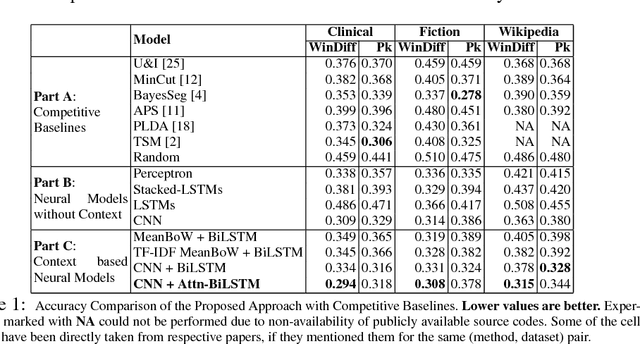
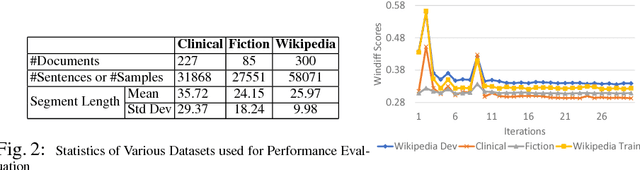
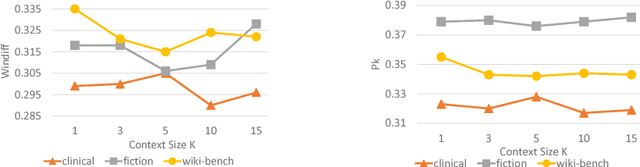
Text segmentation plays an important role in various Natural Language Processing (NLP) tasks like summarization, context understanding, document indexing and document noise removal. Previous methods for this task require manual feature engineering, huge memory requirements and large execution times. To the best of our knowledge, this paper is the first one to present a novel supervised neural approach for text segmentation. Specifically, we propose an attention-based bidirectional LSTM model where sentence embeddings are learned using CNNs and the segments are predicted based on contextual information. This model can automatically handle variable sized context information. Compared to the existing competitive baselines, the proposed model shows a performance improvement of ~7% in WinDiff score on three benchmark datasets.
Arithmetic Word Problem Solver using Frame Identification
Aug 09, 2018
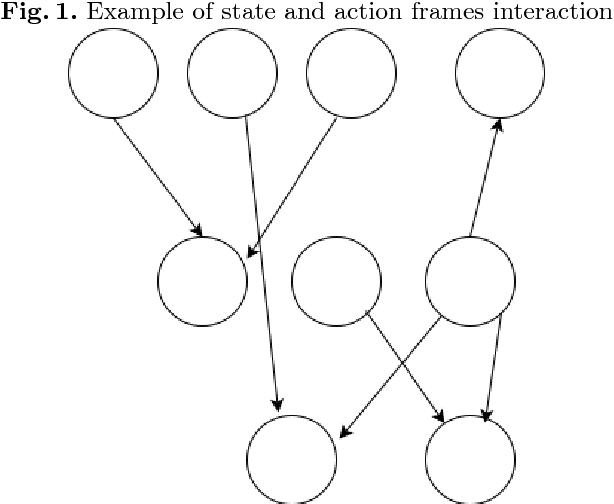

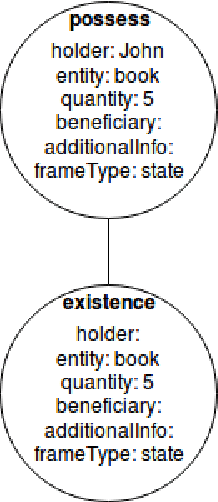
Automatic Word problem solving has always posed a great challenge for the NLP community. Usually a word problem is a narrative comprising of a few sentences and a question is asked about a quantity referred in the sentences. Solving word problem involves reasoning across sentences, identification of operations, their order, relevant quantities and discarding irrelevant quantities. In this paper, we present a novel approach for automatic arithmetic word problem solving. Our approach starts with frame identification. Each frame can either be classified as a state or an action frame. The frame identification is dependent on the verb in a sentence. Every frame is unique and is identified by its slots. The slots are filled using dependency parsed output of a sentence. The slots are entity holder, entity, quantity of the entity, recipient, additional information like place, time. The slots and frames helps to identify the type of question asked and the entity referred. Action frames act on state frame(s) which causes a change in quantities of the state frames. The frames are then used to build a graph where any change in quantities can be propagated to the neighboring nodes. Most of the current solvers can only answer questions related to the quantity, while our system can answer different kinds of questions like `who', `what' other than the quantity related questions `how many'. There are three major contributions of this paper. 1. Frame Annotated Corpus (with a frame annotation tool) 2. Frame Identification Module 3. A new easily understandable Framework for word problem solving