 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePronunciation Dictionary-Free Multilingual Speech Synthesis by Combining Unsupervised and Supervised Phonetic Representations
Jun 02, 2022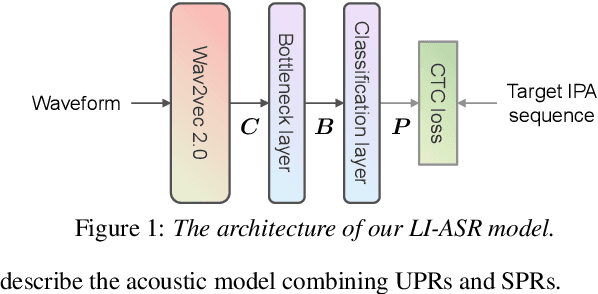

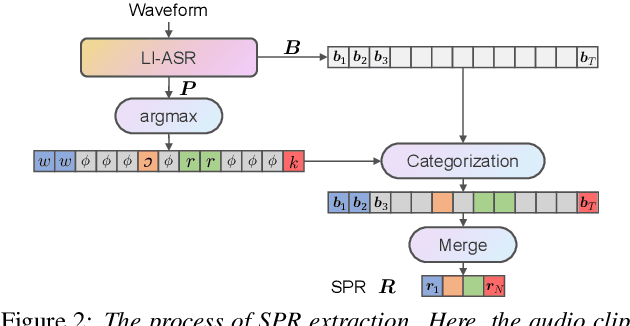

This paper proposes a multilingual speech synthesis method which combines unsupervised phonetic representations (UPR) and supervised phonetic representations (SPR) to avoid reliance on the pronunciation dictionaries of target languages. In this method, a pretrained wav2vec 2.0 model is adopted to extract UPRs and a language-independent automatic speech recognition (LI-ASR) model is built with a connectionist temporal classification (CTC) loss to extract segment-level SPRs from the audio data of target languages. Then, an acoustic model is designed, which first predicts UPRs and SPRs from texts separately and then combines the predicted UPRs and SPRs to generate mel-spectrograms. The results of our experiments on six languages show that the proposed method outperformed the methods that directly predicted mel-spectrograms from character or phoneme sequences and the ablated models that utilized only UPRs or SPRs.
AdaDurIAN: Few-shot Adaptation for Neural Text-to-Speech with DurIAN
May 12, 2020
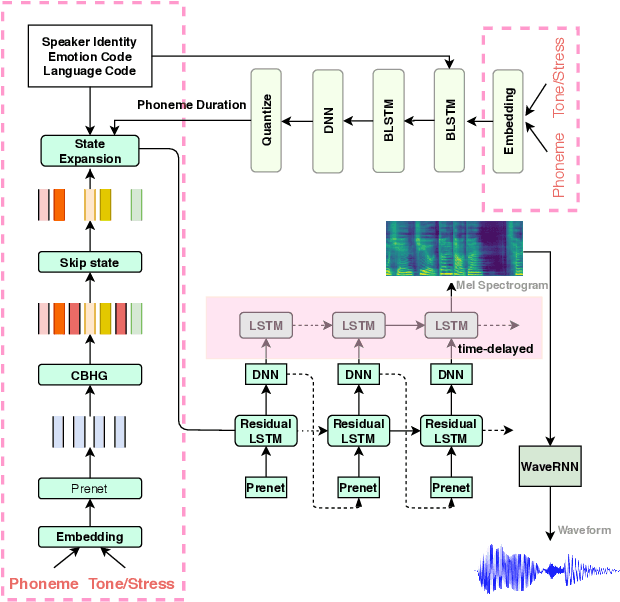
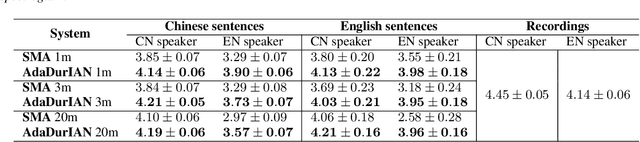
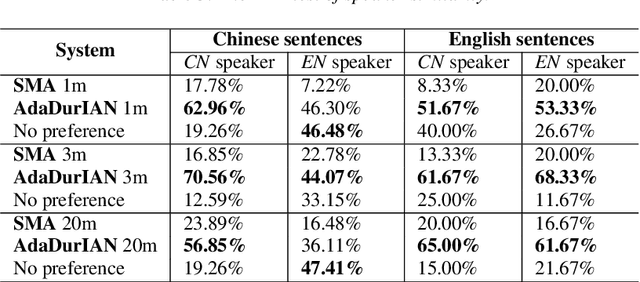
This paper investigates how to leverage a DurIAN-based average model to enable a new speaker to have both accurate pronunciation and fluent cross-lingual speaking with very limited monolingual data. A weakness of the recently proposed end-to-end text-to-speech (TTS) systems is that robust alignment is hard to achieve, which hinders it to scale well with very limited data. To cope with this issue, we introduce AdaDurIAN by training an improved DurIAN-based average model and leverage it to few-shot learning with the shared speaker-independent content encoder across different speakers. Several few-shot learning tasks in our experiments show AdaDurIAN can outperform the baseline end-to-end system by a large margin. Subjective evaluations also show that AdaDurIAN yields higher mean opinion score (MOS) of naturalness and more preferences of speaker similarity. In addition, we also apply AdaDurIAN to emotion transfer tasks and demonstrate its promising performance.