 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePronunciation Dictionary-Free Multilingual Speech Synthesis by Combining Unsupervised and Supervised Phonetic Representations
Paper and Code
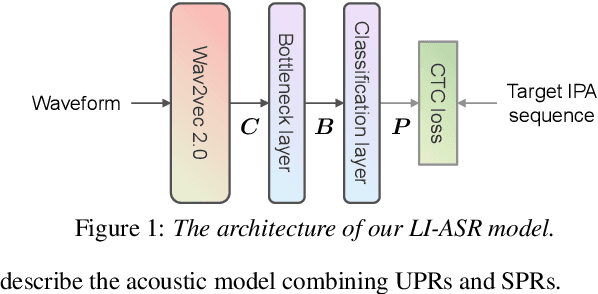

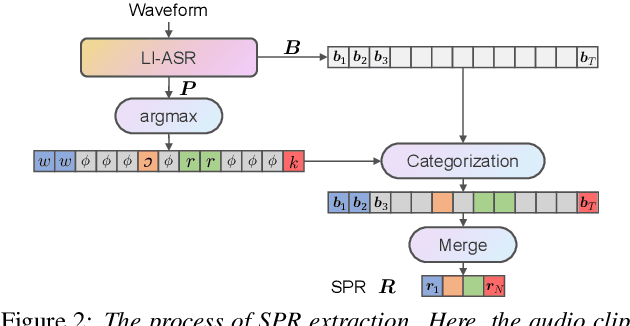

This paper proposes a multilingual speech synthesis method which combines unsupervised phonetic representations (UPR) and supervised phonetic representations (SPR) to avoid reliance on the pronunciation dictionaries of target languages. In this method, a pretrained wav2vec 2.0 model is adopted to extract UPRs and a language-independent automatic speech recognition (LI-ASR) model is built with a connectionist temporal classification (CTC) loss to extract segment-level SPRs from the audio data of target languages. Then, an acoustic model is designed, which first predicts UPRs and SPRs from texts separately and then combines the predicted UPRs and SPRs to generate mel-spectrograms. The results of our experiments on six languages show that the proposed method outperformed the methods that directly predicted mel-spectrograms from character or phoneme sequences and the ablated models that utilized only UPRs or SPRs.