 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing RLVR training instability through the lens of objective-level hacking
Feb 01, 2026Prolonged reinforcement learning with verifiable rewards (RLVR) has been shown to drive continuous improvements in the reasoning capabilities of large language models, but the training is often prone to instabilities, especially in Mixture-of-Experts (MoE) architectures. Training instability severely undermines model capability improvement, yet its underlying causes and mechanisms remain poorly understood. In this work, we introduce a principled framework for understanding RLVR instability through the lens of objective-level hacking. Unlike reward hacking, which arises from exploitable verifiers, objective-level hacking emerges from token-level credit misalignment and is manifested as system-level spurious signals in the optimization objective. Grounded in our framework, together with extensive experiments on a 30B MoE model, we trace the origin and formalize the mechanism behind a key pathological training dynamic in MoE models: the abnormal growth of the training-inference discrepancy, a phenomenon widely associated with instability but previously lacking a mechanistic explanation. These findings provide a concrete and causal account of the training dynamics underlying instabilities in MoE models, offering guidance for the design of stable RLVR algorithms.
Lightweight posterior construction for gravitational-wave catalogs with the Kolmogorov-Arnold network
Aug 26, 2025Neural density estimation has seen widespread applications in the gravitational-wave (GW) data analysis, which enables real-time parameter estimation for compact binary coalescences and enhances rapid inference for subsequent analysis such as population inference. In this work, we explore the application of using the Kolmogorov-Arnold network (KAN) to construct efficient and interpretable neural density estimators for lightweight posterior construction of GW catalogs. By replacing conventional activation functions with learnable splines, KAN achieves superior interpretability, higher accuracy, and greater parameter efficiency on related scientific tasks. Leveraging this feature, we propose a KAN-based neural density estimator, which ingests megabyte-scale GW posterior samples and compresses them into model weights of tens of kilobytes. Subsequently, analytic expressions requiring only several kilobytes can be further distilled from these neural network weights with minimal accuracy trade-off. In practice, GW posterior samples with fidelity can be regenerated rapidly using the model weights or analytic expressions for subsequent analysis. Our lightweight posterior construction strategy is expected to facilitate user-level data storage and transmission, paving a path for efficient analysis of numerous GW events in the next-generation GW detectors.
Improved deep learning techniques in gravitational-wave data analysis
Nov 09, 2020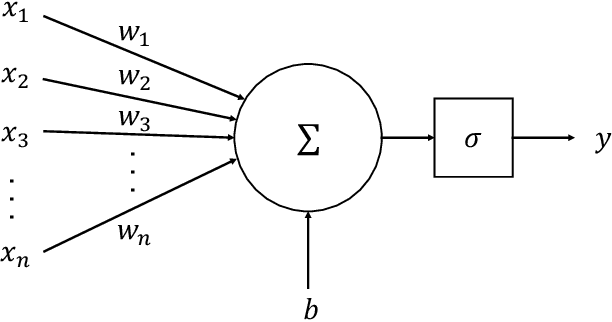
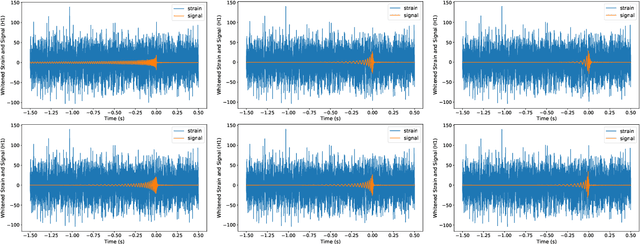
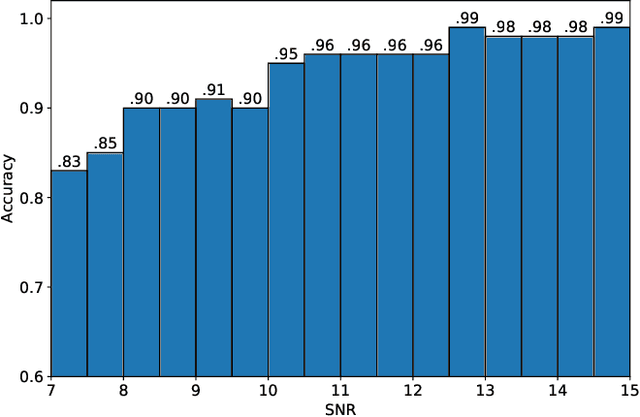
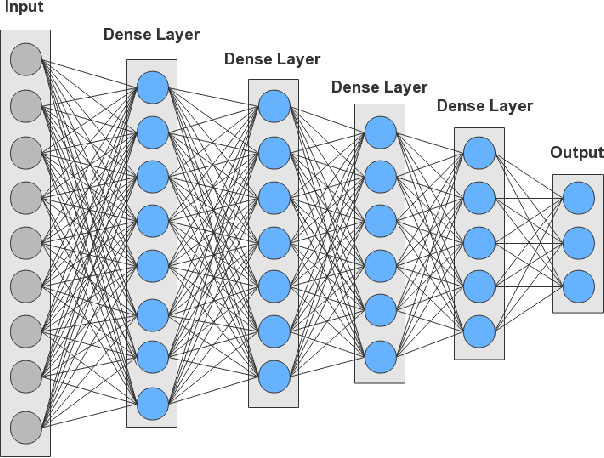
In recent years, convolutional neural network (CNN) and other deep learning models have been gradually introduced into the area of gravitational-wave (GW) data processing. Compared with the traditional matched-filtering techniques, CNN has significant advantages in efficiency in GW signal detection tasks. In addition, matched-filtering techniques are based on the template bank of the existing theoretical waveform, which makes it difficult to find GW signals beyond theoretical expectation. In this paper, based on the task of GW detection of binary black holes, we introduce the optimization techniques of deep learning, such as batch normalization and dropout, to CNN models. Detailed studies of model performance are carried out. Through this study, we recommend to use batch normalization and dropout techniques in CNN models in GW signal detection tasks. Furthermore, we investigate the generalization ability of CNN models on different parameter ranges of GW signals. We point out that CNN models are robust to the variation of the parameter range of the GW waveform. This is a major advantage of deep learning models over matched-filtering techniques.