 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniform Convergence with Square-Root Lipschitz Loss
Jun 22, 2023We establish generic uniform convergence guarantees for Gaussian data in terms of the Rademacher complexity of the hypothesis class and the Lipschitz constant of the square root of the scalar loss function. We show how these guarantees substantially generalize previous results based on smoothness (Lipschitz constant of the derivative), and allow us to handle the broader class of square-root-Lipschitz losses, which includes also non-smooth loss functions appropriate for studying phase retrieval and ReLU regression, as well as rederive and better understand "optimistic rate" and interpolation learning guarantees.
An Agnostic View on the Cost of Overfitting in Ridge Regression
Jun 22, 2023We study the cost of overfitting in noisy kernel ridge regression (KRR), which we define as the ratio between the test error of the interpolating ridgeless model and the test error of the optimally-tuned model. We take an "agnostic" view in the following sense: we consider the cost as a function of sample size for any target function, even if the sample size is not large enough for consistency or the target is outside the RKHS. We analyze the cost of overfitting under a Gaussian universality ansatz using recently derived (non-rigorous) risk estimates in terms of the task eigenstructure. Our analysis provides a more refined characterization of benign, tempered and catastrophic overfitting (qv Mallinar et al. 2022).
Optimistic Rates: A Unifying Theory for Interpolation Learning and Regularization in Linear Regression
Dec 08, 2021
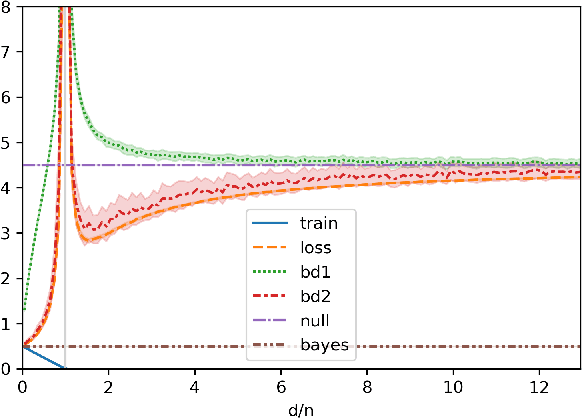
We study a localized notion of uniform convergence known as an "optimistic rate" (Panchenko 2002; Srebro et al. 2010) for linear regression with Gaussian data. Our refined analysis avoids the hidden constant and logarithmic factor in existing results, which are known to be crucial in high-dimensional settings, especially for understanding interpolation learning. As a special case, our analysis recovers the guarantee from Koehler et al. (2021), which tightly characterizes the population risk of low-norm interpolators under the benign overfitting conditions. Our optimistic rate bound, though, also analyzes predictors with arbitrary training error. This allows us to recover some classical statistical guarantees for ridge and LASSO regression under random designs, and helps us obtain a precise understanding of the excess risk of near-interpolators in the over-parameterized regime.
Uniform Convergence of Interpolators: Gaussian Width, Norm Bounds, and Benign Overfitting
Jun 17, 2021
We consider interpolation learning in high-dimensional linear regression with Gaussian data, and prove a generic uniform convergence guarantee on the generalization error of interpolators in an arbitrary hypothesis class in terms of the class's Gaussian width. Applying the generic bound to Euclidean norm balls recovers the consistency result of Bartlett et al. (2020) for minimum-norm interpolators, and confirms a prediction of Zhou et al. (2020) for near-minimal-norm interpolators in the special case of Gaussian data. We demonstrate the generality of the bound by applying it to the simplex, obtaining a novel consistency result for minimum l1-norm interpolators (basis pursuit). Our results show how norm-based generalization bounds can explain and be used to analyze benign overfitting, at least in some settings.
On Uniform Convergence and Low-Norm Interpolation Learning
Jun 10, 2020We consider an underdetermined noisy linear regression model where the minimum-norm interpolating predictor is known to be consistent, and ask: can uniform convergence in a norm ball, or at least (following Nagarajan and Kolter) the subset of a norm ball that the algorithm selects on a typical input set, explain this success? We show that uniformly bounding the difference between empirical and population errors cannot show any learning in the norm ball, and cannot show consistency for any set, even one depending on the exact algorithm and distribution. But we argue we can explain the consistency of the minimal-norm interpolator with a slightly weaker, yet standard, notion, uniform convergence of zero-error predictors. We use this to bound the generalization error of low- (but not minimal-) norm interpolating predictors.