 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLS-DYNA Machine Learning-based Multiscale Method for Nonlinear Modeling of Short Fiber-Reinforced Composites
Jan 06, 2023



Short-fiber-reinforced composites (SFRC) are high-performance engineering materials for lightweight structural applications in the automotive and electronics industries. Typically, SFRC structures are manufactured by injection molding, which induces heterogeneous microstructures, and the resulting nonlinear anisotropic behaviors are challenging to predict by conventional micromechanical analyses. In this work, we present a machine learning-based multiscale method by integrating injection molding-induced microstructures, material homogenization, and Deep Material Network (DMN) in the finite element simulation software LS-DYNA for structural analysis of SFRC. DMN is a physics-embedded machine learning model that learns the microscale material morphologies hidden in representative volume elements of composites through offline training. By coupling DMN with finite elements, we have developed a highly accurate and efficient data-driven approach, which predicts nonlinear behaviors of composite materials and structures at a computational speed orders-of-magnitude faster than the high-fidelity direct numerical simulation. To model industrial-scale SFRC products, transfer learning is utilized to generate a unified DMN database, which effectively captures the effects of injection molding-induced fiber orientations and volume fractions on the overall composite properties. Numerical examples are presented to demonstrate the promising performance of this LS-DYNA machine learning-based multiscale method for SFRC modeling.
* Final version of this manuscript is published in Journal of Engineering Mechanics. Wei, H., Wu, C. T., Hu, W., Su, T. H., Oura H., Nishi, M., Naito T., Chung S., Shen L. (2023). LS-DYNA machine learning-based multiscale method for nonlinear modeling of short-fiber-reinforced composites. Journal of Engineering Mechanics. 149(3): 04023003. https://doi.org/10.1061/JENMDT.EMENG-6945
Speech-language Pre-training for End-to-end Spoken Language Understanding
Feb 11, 2021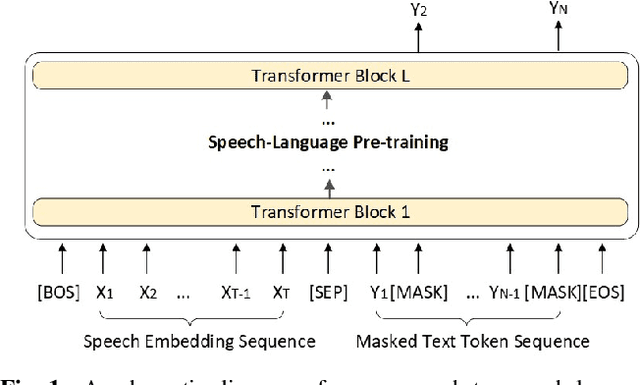
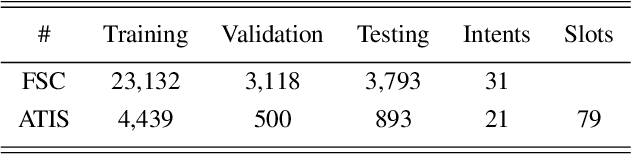
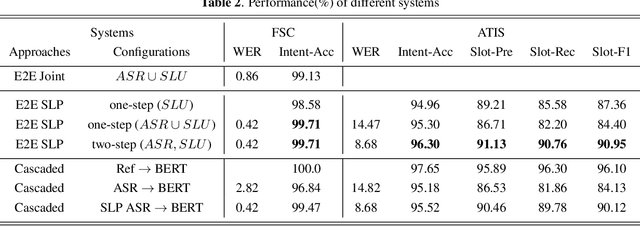

End-to-end (E2E) spoken language understanding (SLU) can infer semantics directly from speech signal without cascading an automatic speech recognizer (ASR) with a natural language understanding (NLU) module. However, paired utterance recordings and corresponding semantics may not always be available or sufficient to train an E2E SLU model in a real production environment. In this paper, we propose to unify a well-optimized E2E ASR encoder (speech) and a pre-trained language model encoder (language) into a transformer decoder. The unified speech-language pre-trained model (SLP) is continually enhanced on limited labeled data from a target domain by using a conditional masked language model (MLM) objective, and thus can effectively generate a sequence of intent, slot type, and slot value for given input speech in the inference. The experimental results on two public corpora show that our approach to E2E SLU is superior to the conventional cascaded method. It also outperforms the present state-of-the-art approaches to E2E SLU with much less paired data.