 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech-language Pre-training for End-to-end Spoken Language Understanding
Feb 11, 2021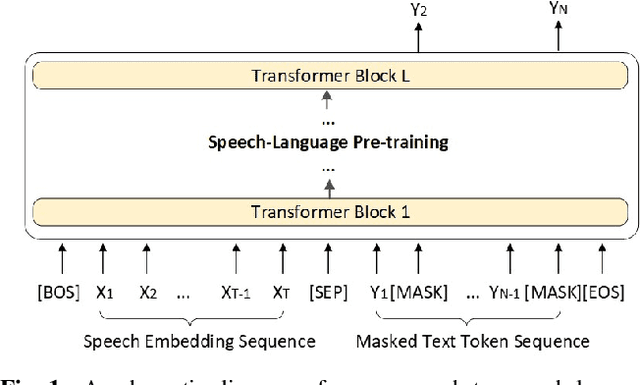
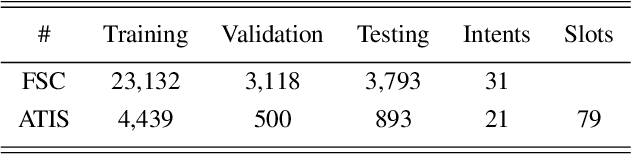
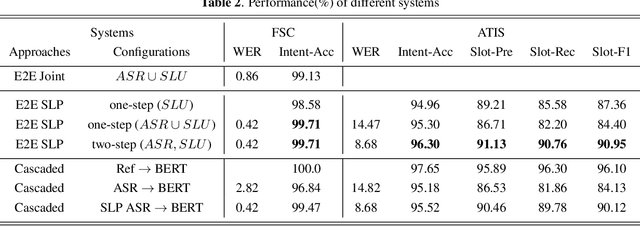

End-to-end (E2E) spoken language understanding (SLU) can infer semantics directly from speech signal without cascading an automatic speech recognizer (ASR) with a natural language understanding (NLU) module. However, paired utterance recordings and corresponding semantics may not always be available or sufficient to train an E2E SLU model in a real production environment. In this paper, we propose to unify a well-optimized E2E ASR encoder (speech) and a pre-trained language model encoder (language) into a transformer decoder. The unified speech-language pre-trained model (SLP) is continually enhanced on limited labeled data from a target domain by using a conditional masked language model (MLM) objective, and thus can effectively generate a sequence of intent, slot type, and slot value for given input speech in the inference. The experimental results on two public corpora show that our approach to E2E SLU is superior to the conventional cascaded method. It also outperforms the present state-of-the-art approaches to E2E SLU with much less paired data.