 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Unbiased Low-Rank Approximation with Minimum Distortion
May 12, 2025We describe an algorithm for sampling a low-rank random matrix $Q$ that best approximates a fixed target matrix $P\in\mathbb{C}^{n\times m}$ in the following sense: $Q$ is unbiased, i.e., $\mathbb{E}[Q] = P$; $\mathsf{rank}(Q)\leq r$; and $Q$ minimizes the expected Frobenius norm error $\mathbb{E}\|P-Q\|_F^2$. Our algorithm mirrors the solution to the efficient unbiased sparsification problem for vectors, except applied to the singular components of the matrix $P$. Optimality is proven by showing that our algorithm matches the error from an existing lower bound.
Over-the-Air Statistical Estimation
Mar 06, 2021We study schemes and lower bounds for distributed minimax statistical estimation over a Gaussian multiple-access channel (MAC) under squared error loss, in a framework combining statistical estimation and wireless communication. First, we develop "analog" joint estimation-communication schemes that exploit the superposition property of the Gaussian MAC and we characterize their risk in terms of the number of nodes and dimension of the parameter space. Then, we derive information-theoretic lower bounds on the minimax risk of any estimation scheme restricted to communicate the samples over a given number of uses of the channel and show that the risk achieved by our proposed schemes is within a logarithmic factor of these lower bounds. We compare both achievability and lower bound results to previous "digital" lower bounds, where nodes transmit errorless bits at the Shannon capacity of the MAC, showing that estimation schemes that leverage the physical layer offer a drastic reduction in estimation error over digital schemes relying on a physical-layer abstraction.
Fisher information under local differential privacy
May 21, 2020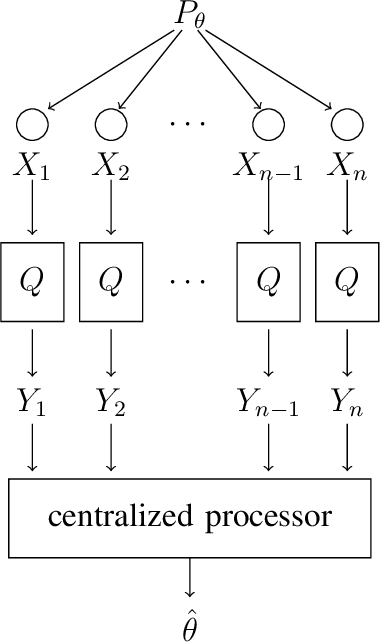

We develop data processing inequalities that describe how Fisher information from statistical samples can scale with the privacy parameter $\varepsilon$ under local differential privacy constraints. These bounds are valid under general conditions on the distribution of the score of the statistical model, and they elucidate under which conditions the dependence on $\varepsilon$ is linear, quadratic, or exponential. We show how these inequalities imply order optimal lower bounds for private estimation for both the Gaussian location model and discrete distribution estimation for all levels of privacy $\varepsilon>0$. We further apply these inequalities to sparse Bernoulli models and demonstrate privacy mechanisms and estimators with order-matching squared $\ell^2$ error.
rTop-k: A Statistical Estimation Approach to Distributed SGD
May 21, 2020
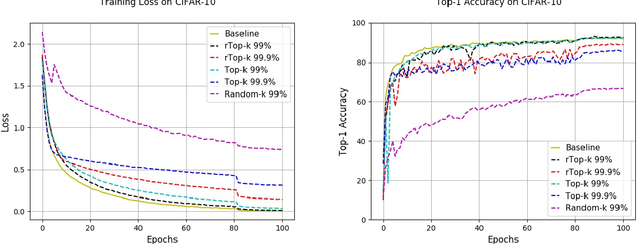

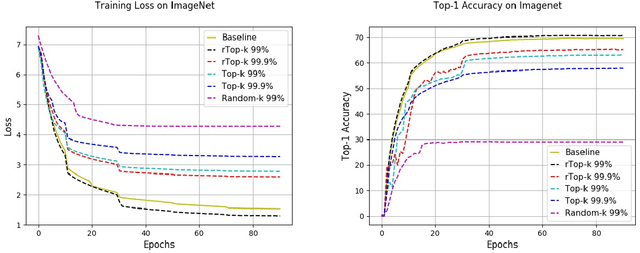
The large communication cost for exchanging gradients between different nodes significantly limits the scalability of distributed training for large-scale learning models. Motivated by this observation, there has been significant recent interest in techniques that reduce the communication cost of distributed Stochastic Gradient Descent (SGD), with gradient sparsification techniques such as top-k and random-k shown to be particularly effective. The same observation has also motivated a separate line of work in distributed statistical estimation theory focusing on the impact of communication constraints on the estimation efficiency of different statistical models. The primary goal of this paper is to connect these two research lines and demonstrate how statistical estimation models and their analysis can lead to new insights in the design of communication-efficient training techniques. We propose a simple statistical estimation model for the stochastic gradients which captures the sparsity and skewness of their distribution. The statistically optimal communication scheme arising from the analysis of this model leads to a new sparsification technique for SGD, which concatenates random-k and top-k, considered separately in the prior literature. We show through extensive experiments on both image and language domains with CIFAR-10, ImageNet, and Penn Treebank datasets that the concatenated application of these two sparsification methods consistently and significantly outperforms either method applied alone.
Learning Distributions from their Samples under Communication Constraints
Feb 07, 2019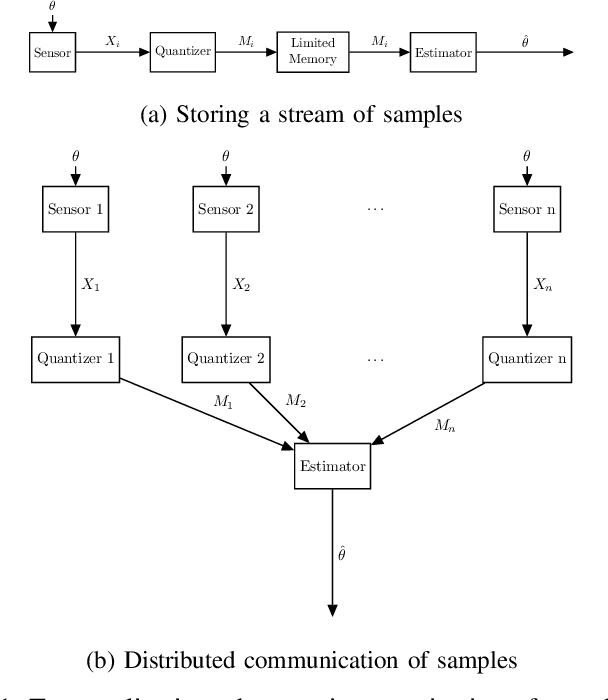
We consider the problem of learning high-dimensional, nonparametric and structured (e.g. Gaussian) distributions in distributed networks, where each node in the network observes an independent sample from the underlying distribution and can use $k$ bits to communicate its sample to a central processor. We consider three different models for communication. Under the independent model, each node communicates its sample to a central processor by independently encoding it into $k$ bits. Under the more general sequential or blackboard communication models, nodes can share information interactively but each node is restricted to write at most $k$ bits on the final transcript. We characterize the impact of the communication constraint $k$ on the minimax risk of estimating the underlying distribution under $\ell^2$ loss. We develop minimax lower bounds that apply in a unified way to many common statistical models and reveal that the impact of the communication constraint can be qualitatively different depending on the tail behavior of the score function associated with each model. A key ingredient in our proof is a geometric characterization of Fisher information from quantized samples.