 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Distributions from their Samples under Communication Constraints
Paper and Code
Feb 07, 2019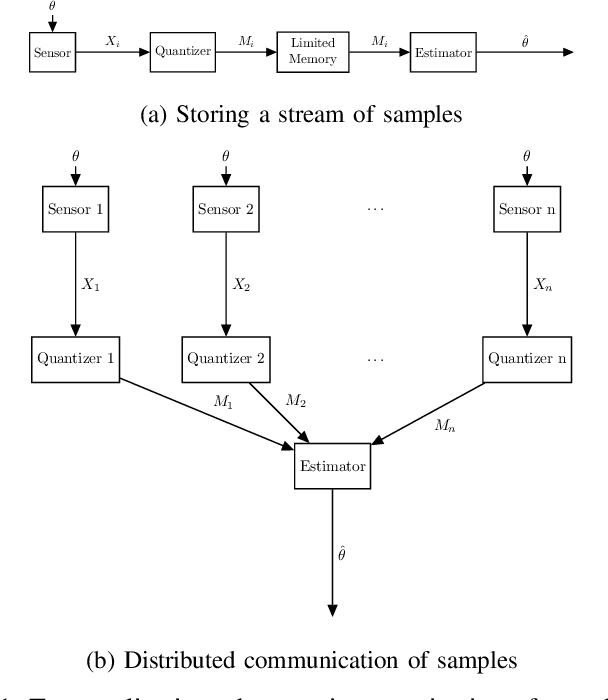
We consider the problem of learning high-dimensional, nonparametric and structured (e.g. Gaussian) distributions in distributed networks, where each node in the network observes an independent sample from the underlying distribution and can use $k$ bits to communicate its sample to a central processor. We consider three different models for communication. Under the independent model, each node communicates its sample to a central processor by independently encoding it into $k$ bits. Under the more general sequential or blackboard communication models, nodes can share information interactively but each node is restricted to write at most $k$ bits on the final transcript. We characterize the impact of the communication constraint $k$ on the minimax risk of estimating the underlying distribution under $\ell^2$ loss. We develop minimax lower bounds that apply in a unified way to many common statistical models and reveal that the impact of the communication constraint can be qualitatively different depending on the tail behavior of the score function associated with each model. A key ingredient in our proof is a geometric characterization of Fisher information from quantized samples.