 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Anomaly Detection in Time-series: An Extensive Evaluation and Analysis of State-of-the-art Methods
Dec 06, 2022



Unsupervised anomaly detection in time-series has been extensively investigated in the literature. Notwithstanding the relevance of this topic in numerous application fields, a complete and extensive evaluation of recent state-of-the-art techniques is still missing. Few efforts have been made to compare existing unsupervised time-series anomaly detection methods rigorously. However, only standard performance metrics, namely precision, recall, and F1-score are usually considered. Essential aspects for assessing their practical relevance are therefore neglected. This paper proposes an original and in-depth evaluation study of recent unsupervised anomaly detection techniques in time-series. Instead of relying solely on standard performance metrics, additional yet informative metrics and protocols are taken into account. In particular, (1) more elaborate performance metrics specifically tailored for time-series are used; (2) the model size and the model stability are studied; (3) an analysis of the tested approaches with respect to the anomaly type is provided; and (4) a clear and unique protocol is followed for all experiments. Overall, this extensive analysis aims to assess the maturity of state-of-the-art time-series anomaly detection, give insights regarding their applicability under real-world setups and provide to the community a more complete evaluation protocol.
TransferI2I: Transfer Learning for Image-to-Image Translation from Small Datasets
May 14, 2021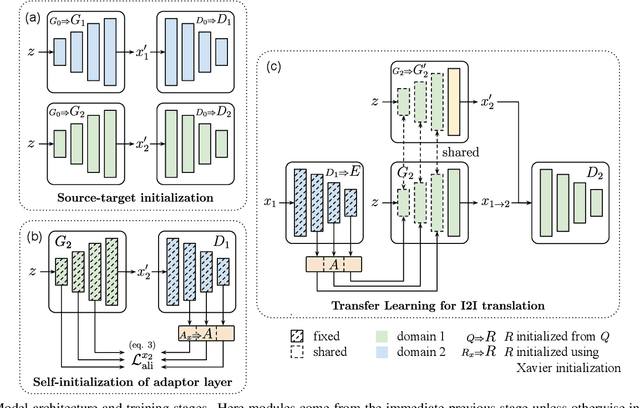
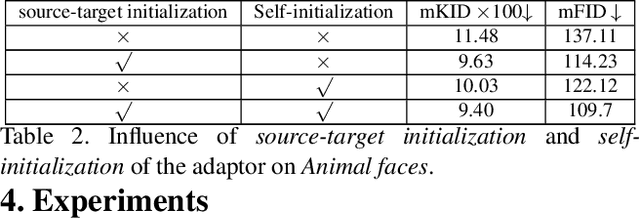
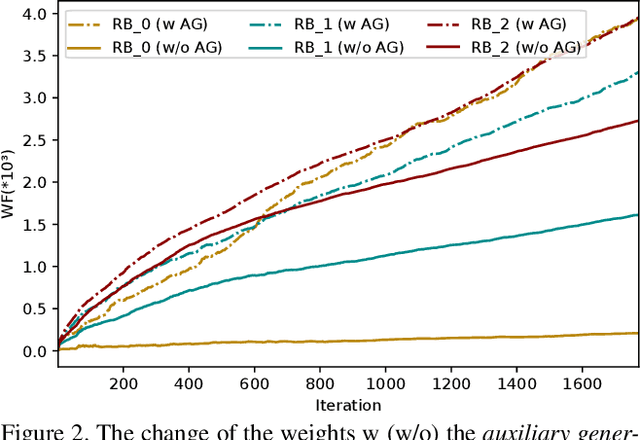
Image-to-image (I2I) translation has matured in recent years and is able to generate high-quality realistic images. However, despite current success, it still faces important challenges when applied to small domains. Existing methods use transfer learning for I2I translation, but they still require the learning of millions of parameters from scratch. This drawback severely limits its application on small domains. In this paper, we propose a new transfer learning for I2I translation (TransferI2I). We decouple our learning process into the image generation step and the I2I translation step. In the first step we propose two novel techniques: source-target initialization and self-initialization of the adaptor layer. The former finetunes the pretrained generative model (e.g., StyleGAN) on source and target data. The latter allows to initialize all non-pretrained network parameters without the need of any data. These techniques provide a better initialization for the I2I translation step. In addition, we introduce an auxiliary GAN that further facilitates the training of deep I2I systems even from small datasets. In extensive experiments on three datasets, (Animal faces, Birds, and Foods), we show that we outperform existing methods and that mFID improves on several datasets with over 25 points.
Review on Computer Vision Techniques in Emergency Situation
Mar 09, 2018
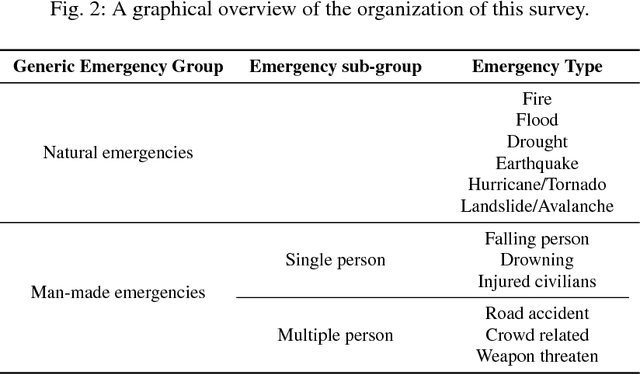


In emergency situations, actions that save lives and limit the impact of hazards are crucial. In order to act, situational awareness is needed to decide what to do. Geolocalized photos and video of the situations as they evolve can be crucial in better understanding them and making decisions faster. Cameras are almost everywhere these days, either in terms of smartphones, installed CCTV cameras, UAVs or others. However, this poses challenges in big data and information overflow. Moreover, most of the time there are no disasters at any given location, so humans aiming to detect sudden situations may not be as alert as needed at any point in time. Consequently, computer vision tools can be an excellent decision support. The number of emergencies where computer vision tools has been considered or used is very wide, and there is a great overlap across related emergency research. Researchers tend to focus on state-of-the-art systems that cover the same emergency as they are studying, obviating important research in other fields. In order to unveil this overlap, the survey is divided along four main axes: the types of emergencies that have been studied in computer vision, the objective that the algorithms can address, the type of hardware needed and the algorithms used. Therefore, this review provides a broad overview of the progress of computer vision covering all sorts of emergencies.
* 25 pages
Bandwidth limited object recognition in high resolution imagery
Jan 16, 2017
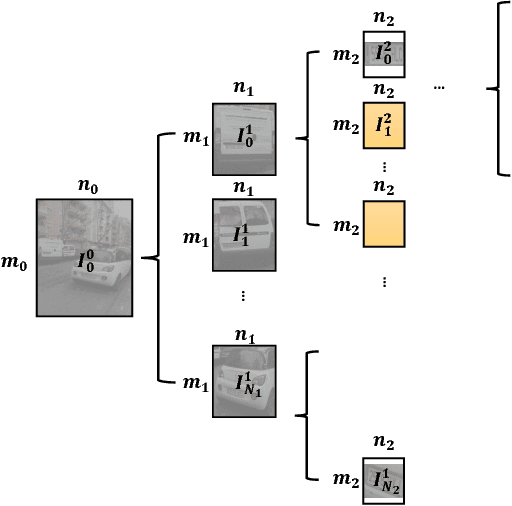
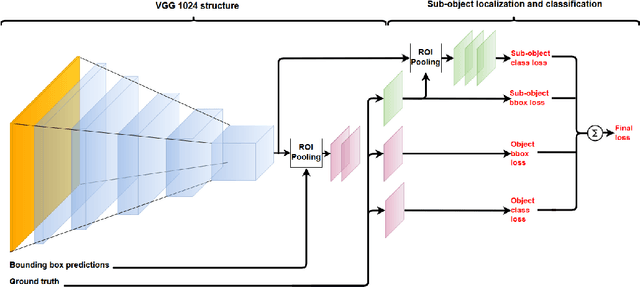

This paper proposes a novel method to optimize bandwidth usage for object detection in critical communication scenarios. We develop two operating models of active information seeking. The first model identifies promising regions in low resolution imagery and progressively requests higher resolution regions on which to perform recognition of higher semantic quality. The second model identifies promising regions in low resolution imagery while simultaneously predicting the approximate location of the object of higher semantic quality. From this general framework, we develop a car recognition system via identification of its license plate and evaluate the performance of both models on a car dataset that we introduce. Results are compared with traditional JPEG compression and demonstrate that our system saves up to one order of magnitude of bandwidth while sacrificing little in terms of recognition performance.
* 9 pages, 9 figures, accepted in WACV