 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPT: Adaptive Personalized Training for Diffusion Models with Limited Data
Jul 03, 2025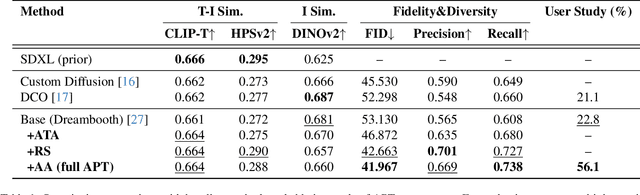
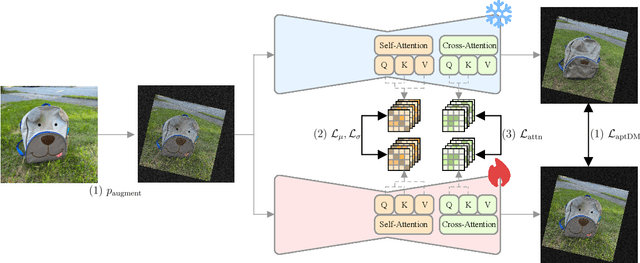


Personalizing diffusion models using limited data presents significant challenges, including overfitting, loss of prior knowledge, and degradation of text alignment. Overfitting leads to shifts in the noise prediction distribution, disrupting the denoising trajectory and causing the model to lose semantic coherence. In this paper, we propose Adaptive Personalized Training (APT), a novel framework that mitigates overfitting by employing adaptive training strategies and regularizing the model's internal representations during fine-tuning. APT consists of three key components: (1) Adaptive Training Adjustment, which introduces an overfitting indicator to detect the degree of overfitting at each time step bin and applies adaptive data augmentation and adaptive loss weighting based on this indicator; (2)Representation Stabilization, which regularizes the mean and variance of intermediate feature maps to prevent excessive shifts in noise prediction; and (3) Attention Alignment for Prior Knowledge Preservation, which aligns the cross-attention maps of the fine-tuned model with those of the pretrained model to maintain prior knowledge and semantic coherence. Through extensive experiments, we demonstrate that APT effectively mitigates overfitting, preserves prior knowledge, and outperforms existing methods in generating high-quality, diverse images with limited reference data.
* CVPR 2025 camera ready. Project page: https://lgcnsai.github.io/apt
GTA: Guided Transfer of Spatial Attention from Object-Centric Representations
Jan 05, 2024Utilizing well-trained representations in transfer learning often results in superior performance and faster convergence compared to training from scratch. However, even if such good representations are transferred, a model can easily overfit the limited training dataset and lose the valuable properties of the transferred representations. This phenomenon is more severe in ViT due to its low inductive bias. Through experimental analysis using attention maps in ViT, we observe that the rich representations deteriorate when trained on a small dataset. Motivated by this finding, we propose a novel and simple regularization method for ViT called Guided Transfer of spatial Attention (GTA). Our proposed method regularizes the self-attention maps between the source and target models. A target model can fully exploit the knowledge related to object localization properties through this explicit regularization. Our experimental results show that the proposed GTA consistently improves the accuracy across five benchmark datasets especially when the number of training data is small.
Rethinking Evaluation Protocols of Visual Representations Learned via Self-supervised Learning
Apr 07, 2023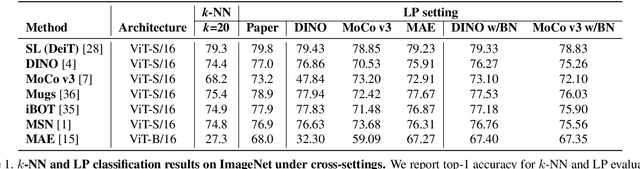
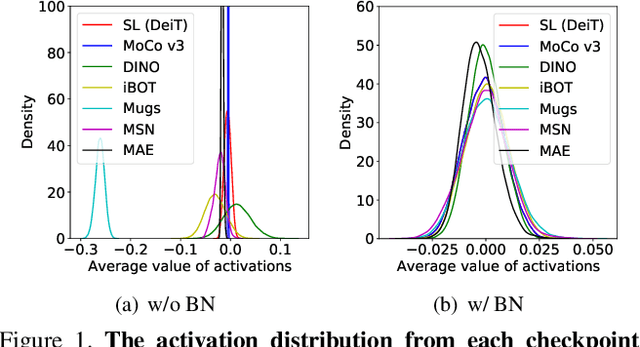
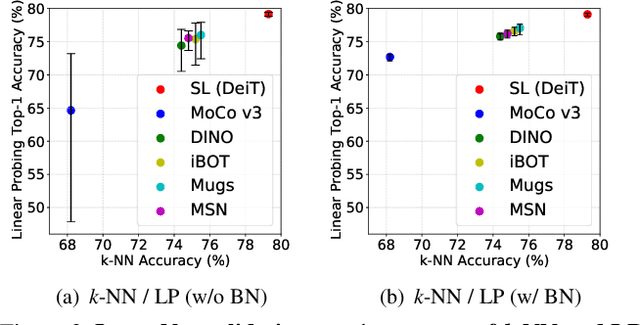

Linear probing (LP) (and $k$-NN) on the upstream dataset with labels (e.g., ImageNet) and transfer learning (TL) to various downstream datasets are commonly employed to evaluate the quality of visual representations learned via self-supervised learning (SSL). Although existing SSL methods have shown good performances under those evaluation protocols, we observe that the performances are very sensitive to the hyperparameters involved in LP and TL. We argue that this is an undesirable behavior since truly generic representations should be easily adapted to any other visual recognition task, i.e., the learned representations should be robust to the settings of LP and TL hyperparameters. In this work, we try to figure out the cause of performance sensitivity by conducting extensive experiments with state-of-the-art SSL methods. First, we find that input normalization for LP is crucial to eliminate performance variations according to the hyperparameters. Specifically, batch normalization before feeding inputs to a linear classifier considerably improves the stability of evaluation, and also resolves inconsistency of $k$-NN and LP metrics. Second, for TL, we demonstrate that a weight decay parameter in SSL significantly affects the transferability of learned representations, which cannot be identified by LP or $k$-NN evaluations on the upstream dataset. We believe that the findings of this study will be beneficial for the community by drawing attention to the shortcomings in the current SSL evaluation schemes and underscoring the need to reconsider them.
Self-Knowledge Distillation: A Simple Way for Better Generalization
Jun 22, 2020



The generalization capability of deep neural networks has been substantially improved by applying a wide spectrum of regularization methods, e.g., restricting function space, injecting randomness during training, augmenting data, etc. In this work, we propose a simple yet effective regularization method named self-knowledge distillation (Self-KD), which progressively distills a model's own knowledge to soften hard targets (i.e., one-hot vectors) during training. Hence, it can be interpreted within a framework of knowledge distillation as a student becomes a teacher itself. The proposed method is applicable to any supervised learning tasks with hard targets and can be easily combined with existing regularization methods to further enhance the generalization performance. Furthermore, we show that Self-KD achieves not only better accuracy, but also provides high quality of confidence estimates. Extensive experimental results on three different tasks, image classification, object detection, and machine translation, demonstrate that our method consistently improves the performance of the state-of-the-art baselines, and especially, it achieves state-of-the-art BLEU score of 30.0 and 36.2 on IWSLT15 English-to-German and German-to-English tasks, respectively.
Bin-wise Temperature Scaling (BTS): Improvement in Confidence Calibration Performance through Simple Scaling Techniques
Sep 23, 2019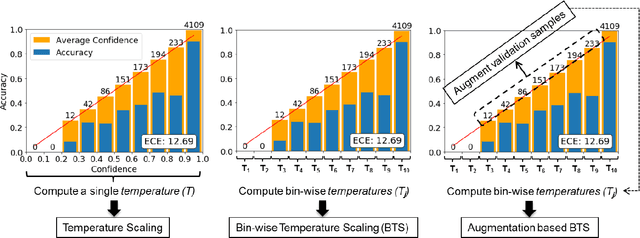
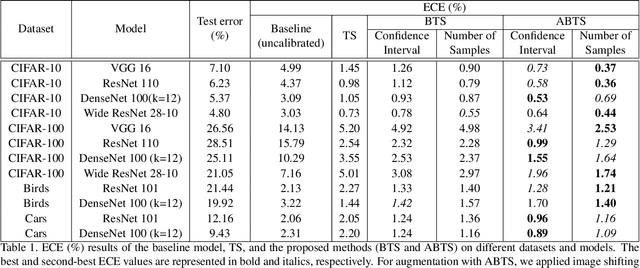
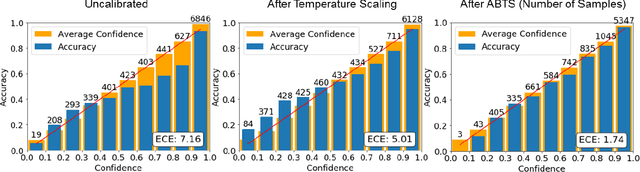
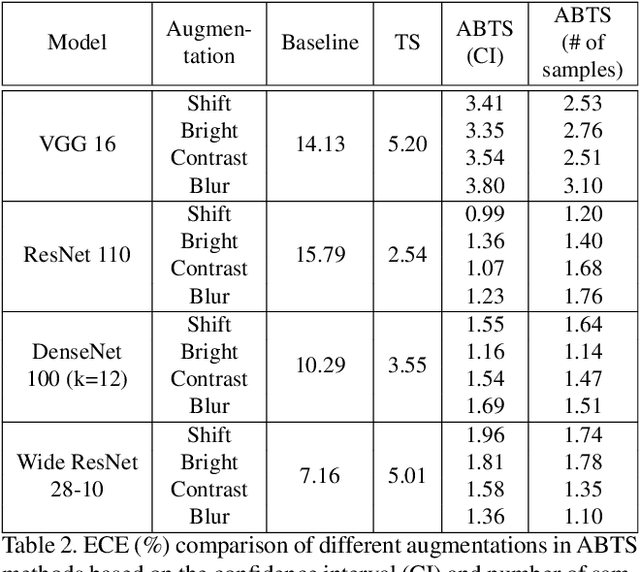
The prediction reliability of neural networks is important in many applications. Specifically, in safety-critical domains, such as cancer prediction or autonomous driving, a reliable confidence of model's prediction is critical for the interpretation of the results. Modern deep neural networks have achieved a significant improvement in performance for many different image classification tasks. However, these networks tend to be poorly calibrated in terms of output confidence. Temperature scaling is an efficient post-processing-based calibration scheme and obtains well calibrated results. In this study, we leverage the concept of temperature scaling to build a sophisticated bin-wise scaling. Furthermore, we adopt augmentation of validation samples for elaborated scaling. The proposed methods consistently improve calibration performance with various datasets and deep convolutional neural network models.
Propagated Perturbation of Adversarial Attack for well-known CNNs: Empirical Study and its Explanation
Sep 23, 2019

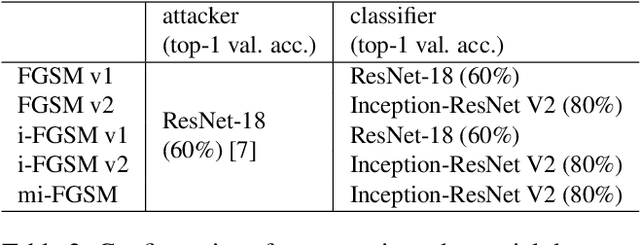
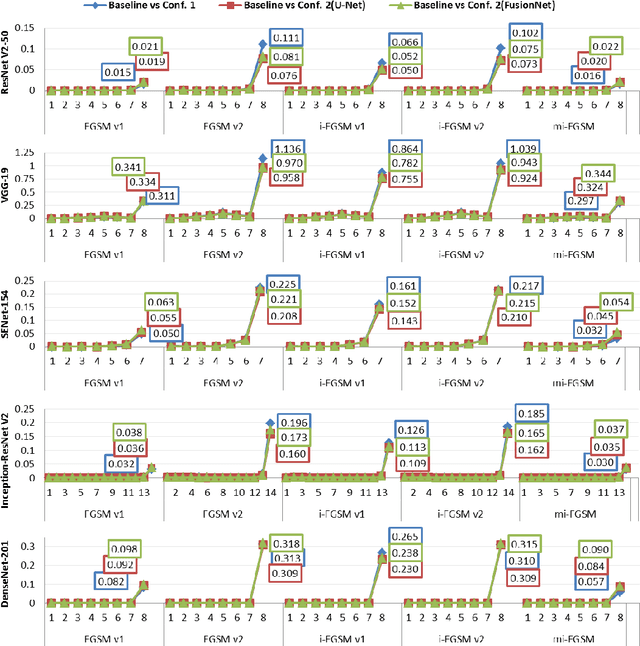
Deep Neural Network based classifiers are known to be vulnerable to perturbations of inputs constructed by an adversarial attack to force misclassification. Most studies have focused on how to make vulnerable noise by gradient based attack methods or to defense model from adversarial attack. The use of the denoiser model is one of a well-known solution to reduce the adversarial noise although classification performance had not significantly improved. In this study, we aim to analyze the propagation of adversarial attack as an explainable AI(XAI) point of view. Specifically, we examine the trend of adversarial perturbations through the CNN architectures. To analyze the propagated perturbation, we measured normalized Euclidean Distance and cosine distance in each CNN layer between the feature map of the perturbed image passed through denoiser and the non-perturbed original image. We used five well-known CNN based classifiers and three gradient-based adversarial attacks. From the experimental results, we observed that in most cases, Euclidean Distance explosively increases in the final fully connected layer while cosine distance fluctuated and disappeared at the last layer. This means that the use of denoiser can decrease the amount of noise. However, it failed to defense accuracy degradation.